|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese
КОНСПЕКТИ ЛЕКЦІЙ, ШПАРГАЛКИ
Інформатика та інформаційні технології. Шпаргалка: коротко, найголовніше
Довідник / Конспекти лекцій, шпаргалки Зміст
1. Інформатика. Інформація Подання та обробка/інформації. Системи числення Інформатика займається формалізованим уявленням об'єктів та структур їх взаємозв'язків у різних галузях науки, техніки, виробництва. Для моделювання об'єктів та явищ використовуються різні формальні засоби, наприклад, логічні формули, структури даних, мови програмування та ін. В інформатиці таке фундаментальне поняття, як інформація, має різні значення: 1) формальне подання зовнішніх форм інформації; 2) абстрактне значення інформації, її внутрішній зміст, семантика; 3) відношення інформації до реального світу. Але, зазвичай, під інформацією розуміють її абстрактне значення - семантику. Якщо ми хочемо обмінюватися інформацією, нам потрібні узгоджені уявлення, щоб не порушувалася правильність інтерпретації. Для цього інтерпретацію подання інформації ототожнюють із деякими математичними структурами. У цьому випадку обробка інформації може бути виконана строгими математичними методами. Один із математичних описів інформації - це подання її у вигляді функції y = f(x, t) де t - час, x - точка деякого поля, де вимірюється значення y. Залежно від параметрів функції x та t інформацію можна класифікувати. Якщо параметри - скалярні величини, що набирають безперервний ряд значень, то отримана таким чином інформація називається безперервною (або аналоговою). Якщо параметрам надати певний крок змін, то інформація називається дискретною. Дискретна інформація вважається універсальною. Дискретну інформацію зазвичай ототожнюють із цифровою інформацією, яка є окремим випадком символьної інформації алфавітного подання. Алфавіт – кінцевий набір символів будь-якої природи. Дуже часто в інформатиці виникає ситуація, коли символи одного алфавіту треба подати символами іншого, тобто провести операцію кодування. Як показала практика, найбільш простим алфавітом, що дозволяє кодувати інші алфавіти, є двійковий, що складається з двох символів, які позначаються, як правило, через 0 і 1. За допомогою n символів двійкового алфавіту можна закодувати 2n символів, а цього достатньо, щоб закодувати будь-який алфавіту. Розмір, який може бути представлений символом двійкового алфавіту, називається мінімальної одиницею інформації чи бітом. Послідовність із 8 біт - байт. Алфавіт, що містить 256 різних 8-бітових послідовностей, називається байтовим. Під системою числення мається на увазі набір правил найменування та запису чисел. Розрізняють позиційні та непозиційні системи числення. Система числення називається позиційною, якщо значення цифри числа залежить від розташування цифри числа. Інакше вона називається непозиційною. Значення числа визначається за становищем цих цифр у числі. 2. Подання чисел в ЕОМ. Формалізоване поняття алгоритму 32-розрядні процесори можуть працювати з оперативною пам'яттю ємністю до 232-1, а адреси можуть записуватися в діапазоні 00000000 – FFFFFFFF. Однак у реальному режимі процесор працює з пам'яттю до 220-1, а адреси потрапляють у діапазон 00000 – FFFFF. Байти пам'яті можуть поєднуватися в поля як фіксованої, так і змінної довжини. Словом називається поле фіксованої довжини, що складається з 2 байтів, подвійним словом – поле з 4 байтів. Адреси полів бувають парні та непарні, при цьому для парних адрес операції виконуються швидше. Числа з фіксованою точкою в ЕОМ представляються як цілі двійкові числа, і об'єм, що займається ними, може становити 1, 2 або 4 байти. Цілі двійкові числа подаються у додатковому коді. Додатковий код позитивного числа дорівнює самому числу, а додатковий код від'ємного числа може бути отриманий за такою формулою: x = 10n – \x\, де n – розрядність числа. У двійковій системі числення додатковий код виходить шляхом інверсії розрядів, тобто заміною одиниць нулями і навпаки, і додаванням одиниці до молодшого розряду. Кількість бітів мантиси визначає точність уявлення чисел, кількість бітів машинного порядку визначає діапазон уявлення чисел з плаваючою точкою. Формалізоване поняття алгоритму Алгоритм може існувати лише тоді, коли в той же час існує певний математичний об'єкт. Формалізоване поняття алгоритму пов'язані з поняттям рекурсивних функцій, нормальних алгоритмів Маркова, машин Тьюринга. У математиці функція називається однозначною, якщо будь-якого набору аргументів існує закон, яким визначається єдине значення функції. Як такий закон може виступати алгоритм; у цьому випадку функція називається обчислюваною. Рекурсивні функції - це підклас функцій, що обчислюються, а алгоритми, що визначають обчислення, називаються супутніми алгоритмами рекурсивних функцій. Спочатку фіксуються базові рекурсивні функції, котрим супутній алгоритм тривіальний, однозначний; потім вводяться три правила - оператори підстановки, рекурсії та мінімізації, за допомогою яких на основі базових функцій виходять складніші рекурсивні функції. Базовими функціями та їх супутніми алгоритмами можуть виступати: 1) функція n незалежних змінних, тотожно дорівнює нулю. Тоді, якщо знаком функції є n, то незалежно від кількості аргументів значення функції слід покласти рівним нулю; 2) тотожна функція n незалежних змінних видів Ψ ni. Тоді, якщо знаком функції є N, то значенням функції слід взяти значення i-го аргументу, вважаючи зліва направо; 3) λ-функція одного незалежного аргументу. Тоді, якщо знаком функції є λ, значенням функції слід взяти значення, наступне за значенням аргументу. 3. Введення в мову Pascal Основні символи мови - літери, цифри та спеціальні символи - становлять його алфавіт. Мова Pascal включає наступний набір основних символів: 1) 26 латинських малих і 26 латинських великих літер: 2) _ (знак підкреслення); 3) 10 цифр: 0 1 2 3 4 5 6 7 8 9; 4) знаки операцій: + - Про / = <> < > <= >= := @; 5) обмежувачі:., ( ) [ ] (..) { } (* *).. : ; 6) специфікатори: ^ # $; 7) службові (зарезервовані) слова: ABSOLUTE, ASSEMBLER, AND, ARRAY, ASM, BEGIN, CASE, CONST, CONSTRUCTOR, DESTRUCTOR, DIV, DO, DOWNTO, ELSE, END, EXPORT, EXTERNAL, FAR, FILE, FOR, FORWARD, FUNCTION, GOTO, IF, IMPLEMENTATION, IN, INDEX, INHERITED, INLINE, INTERFACE, INTERRUPT, LABEL, LIBRARY, MOD, NAME, NIL, NEAR, NOT, OBJECT, OF, OR, PACKED, PRIVATE, PROCEDURE, PROGRAM, PUBLIC, RECORD, REPEAT, RESIDENT, SET, SHL, SHR, STRING, THEN, TO, TYPE, UNIT, UNTIL, USES, VAR, VIRTUAL, WHILE, WITH, XOR. Крім перерахованих, набір основних символів входить пробіл. У мові Pascal існує правило: тип явно задається в описі змінної або функції, що передує їх використанню. Концепція типу мови Pascal має такі основні властивості: 1) будь-який тип даних визначає безліч значень, до якого належить константа, які може приймати змінна або вираз або виробляти операція чи функція; 2) тип значення, що задається константою, змінною або виразом, можна визначити за їх видом або описом; 3) кожна операція чи функція вимагають аргументів фіксованого типу та видають результат фіксованого типу. У мові Pascal існують скалярні та структуровані типи даних. До скалярних типів відносяться стандартні типи та типи, що визначаються користувачем. Стандартні типи включають цілі, дійсні, символьні, логічні та адресні типи. Цілі типи визначають константи, змінні та функції, значення яких реалізуються безліччю цілих чисел, допустимих у цій ЕОМ. У мові Pascal прийнято наступний пріоритет операцій:
1) обчислення у круглих дужках; 2) обчислення значень функцій; 3) унарні операції; 4) операції */div mod and; 5) операції + - або xor; 6) операції відносини = <> < > <= >=. 4. Стандартні процедури та функції Арифметичні функції 1. Function Abs(X); повертає абсолютне значення параметра. 2. Function ArcTan(X: Extended): Extended; повертає Арктангенс аргументу. 3. Function Exp(X: Real): Real; повертає експоненту. 4. Function Frac(X: Real): Real; повертає дрібну частину аргументу. 5. Function Int(X: Real): Real; повертає цілу частину аргументу. 6. Function Ln(X: Real): Real; повертає натуральний логарифм (Ln е = 1) виразу x речового типу. 7. Function Pi: Extended; повертає значення Pi, визначене як 3.1415926535. 8. Function Sin(X: Extended): Extended; повертає синус аргументу. 9. Function Sqr(X: Extended): Extended; повертає квадрат аргументу. 10. Function Sqrt(X: Extended): Extended; повертає квадратний корінь аргументу. Процедури та функції перетворення величин 1. Procedure Str(X[: Width[: Decimals]]; var S); перетворює число X в рядкову виставу. 2. Function Chr (X: Byte): Char; повертає символ із порядковим номером x у ASCII-таблиці. 3. Function High(X); повертає найбільше значення діапазоні параметра. 4. Function Low(X); повертає найменше значення діапазону параметра. 5. Function Ord(X): Longlnt; повертає порядкове значення виразу перерахованого типу. 6. Function Round (X: Extended): LongInt; округляє значення речовинного типу до цілого. 7. Function Trunc (X: Extended): LongInt; усікає значення речовинного типу до цілого. 8. Procedure Val(S; var V; var Code: Integer); перетворює число з рядкового значення S числове уявлення V. Процедури та функції роботи з порядковими величинами 1. Procedure Dec(var X [; N: LongInt]); віднімає одиницю або N із змінної X. 2. Procedure Inc(var X [; N: LongInt]); додає одиницю або N до змінної X. 3. Function Odd(X: LongInt): Boolean; повертає True, якщо X - непарне число, і False - інакше. 4. Function Pred(X); повертає попереднє значення параметра. 5. Function Succ(X); повертає наступне значення параметра. 5. Оператори мови Pascal Умовний оператор Формат повного умовного оператора визначається так: If B then S1 else S2 де B - умова розгалуження (ухвалення рішення), логічний вираз чи ставлення; S1, S2 - один виконуваний оператор, простий чи складовий. При виконанні умовного оператора спочатку обчислюється вираз B, потім аналізується його результат: якщо B - істинно, виконується оператор S1 - гілка then, а оператор S2 пропускається; якщо B - хибно, то виконується оператор S2 - гілка else, а оператор S1 - пропускається. оператор вибору Структура оператора має такий вигляд: case S of c1: insruction1; c2: insruction2; ... cn: insructionN; else instruction end; де S – вираз порядкового типу, значення якого обчислюється; c1, c2,..., on - константи порядкового типу, з якими порівнюються вирази S; instructionl,..., instructionN - оператори, у тому числі виконується той, з константою якого збігається значення висловлювання S; instruction - оператор, який виконується, якщо значення виразу S не збігається з жодною з констант c1, o2, on. Оператор циклу із параметром Коли починає виконуватися оператор for, початкове та кінцеве значення визначаються один раз, і ці значення зберігаються протягом усього виконання оператора for. Оператор, який міститься в тілі оператора for, виконується один раз для кожного значення діапазону між початковим і кінцевим значенням. Лічильник циклу завжди ініціалізується початковим значенням. Оператор циклу з передумовою While B do S; де B - логічна умова, істинність якої перевіряється (вона є умовою завершення циклу) $; S – тіло циклу – один оператор. Вираз, за допомогою якого здійснюється керування повторенням оператора, повинен мати логічний тип. Обчислення його провадиться до того, як внутрішній оператор буде виконаний. Внутрішній оператор виконується повторно до тих пір, поки вираз набуває значення ТГІ. Якщо вираз від початку приймає значення False, то оператор, що міститься всередині оператора циклу з передумовою, не виконується. Оператор циклу з постумовою repeat S until B; де B - логічна умова, істинність якої перевіряється (вона є умовою завершення циклу); S – один або більше операторів тіла циклу. Результат виразу має бути логічного типу. Оператори, укладені між ключовими словами repeat і until, виконуються послідовно до того часу, поки результат виразу не прийме значення True. Послідовність операторів виконається принаймні один раз, оскільки обчислення виразу проводиться після кожного виконання послідовності операторів. 6. Поняття допоміжного алгоритму Алгоритм розв'язання задачі проектується шляхом декомпозиції всього завдання окремі подзадачи. Зазвичай підзавдання реалізуються як підпрограм. Підпрограма - це деякий допоміжний алгоритм, що багаторазово використовується в основному алгоритмі з різними значеннями деяких вхідних величин, які називаються параметрами. Підпрограма в мовах програмування – це послідовність операторів, які визначені та записані лише в одному місці програми, однак їх можна викликати для виконання з однієї або кількох точок програми. Кожна підпрограма визначається унікальним іменем. У мові Pascal існують два типи підпрограм – процедури та функції. Процедура та функція – це іменована послідовність описів та операторів. При використанні процедур або функцій програма повинна містити текст процедури або функції та звернення до процедури або функції. Параметри, вказані в описі, називаються формальними, вказані у зверненні підпрограми - фактичними. Усі формальні параметри можна розбити на наступні категорії: 1) параметри-змінні; 2) параметри-константи; 3) параметри-значення; 4) параметри-процедури та параметри-функції, тобто параметри процедурного типу; 5) нетипізовані параметри-змінні. Тексти процедур та функцій містяться в розділах процедур та функцій. Передача імен процедур та функцій як параметри У багатьох завданнях, особливо у задачах обчислювальної математики, необхідно передавати імена процедур та функцій як параметри. Для цього в TURBO PASCAL введено новий тип даних – процедурний, або функціональний, залежно від того, що описується. (Опис процедурних та функціональних типів наведено у розділі опису типів.) Функціональний та процедурний тип визначається як заголовок процедури та функції зі списком формальних параметрів, але без імені. Можна визначити функціональний або процедурний тип без параметрів, наприклад: тип Proc = Procedure; Після оголошення процедурного або функціонального типу його можна використовувати для опису формальних параметрів - імен процедур і функцій. Крім того, необхідно написати ті реальні процедури або функції, імена яких передаватимуться як фактичні параметри. 7. Процедури та функції в Pascal Процедури Pascal Опис процедури складається із заголовка та блоку, який, за винятком розділу підключення модулів, не відрізняються від блоку програми. Заголовок складається з ключового слова Procedure, імені процедури та необов'язкового списку формальних параметрів у круглих дужках: Procedure <ім'я> [(<список формальних параметрів>)]; Для кожного формального параметра має бути визначено його тип. Групи параметрів в описі процедури поділяються крапкою з комою. За структурою процедура майже повністю аналогічна до програми. Однак у блоці процедури немає розділу підключення модулів. Блок складається з двох частин: описової та виконавчої. В описовій частині міститься опис елементів процедури. А у виконавчій частині вказуються дії з доступними процедурами елементами програми (наприклад, глобальні змінні та константи), що дозволяють отримати необхідний результат. Розділ інструкцій процедури відрізняється від розділу інструкцій програми лише тим, що після ключового слова End, що завершує цей розділ, ставиться крапка з комою, а не крапка. Для звернення до процедури використовується інструкція виклику. Вона складається з імені процедури та списку аргументів, укладеного у круглі дужки. Оператори, які мають виконуватися під час запуску процедури, містяться в операторній частині модуля процедури. Іноді потрібно, щоб процедура викликала сама себе. Такий спосіб виклику називається рекурсією. Рекурсія корисна у випадках, коли основне завдання можна розбити на підзавдання, кожна з яких реалізується за алгоритмом, що збігається з основним. Функції у Pascal Опис функції визначає частину програми, в якій обчислюється та повертається значення. Опис функції складається з заголовка та блоку. Заголовок містить ключове слово Function, ім'я функції, необов'язковий список формальних параметрів, укладений у круглі дужки, та тип значення, що повертається функцією. Загальний вигляд заголовка функції наступний: Function <ім'я> [(<список формальних параметрів>)]: <тип результату, що повертається>; У реалізації Turbo Pascal 7.0 фірми Borland значення, що повертається функцією, не може мати складовий тип. А мова Object Pascal, що використовується в інтегрованих середовищах розробки Borland Delphi, допускає будь-який тип результату, що повертається, крім файлового типу. Блок функції є локальний блок, за структурою аналогічний блоку процедури. У тілі функції має бути хоча б одна інструкція присвоєння, у лівій частині якої стоїть ім'я функції. Саме вона і визначає значення, яке повертається функцією. Якщо таких інструкцій кілька, результатом функції буде значення останньої виконаної інструкції присвоювання. Функція активується під час виклику функції. Під час виклику функції вказується ідентифікатор функції та будь-які параметри, необхідні для обчислення функції. Виклик функції може включатися у вирази як операнда. Коли вираз обчислюється, функція виконується і значення операнда стає значення, що повертається функцією. У операторній частині блоку функції задаються оператори, які мають виконуватися під час активізації функції. У модулі повинен утримуватися принаймні один оператор присвоювання, в якому ідентифікатору функції присвоюється значення. Результатом функції є останнє значення. Якщо такий оператор присвоювання відсутня або він не був виконаний, то значення, яке повертається функцією, не визначено. Якщо ідентифікатор функції використовується при виклику функції всередині модуля функції, то функція виконується рекурсивно. 8. Випереджувальні описи та підключення підпрограм. Директива У програмі може бути кілька підпрограм, т. е. структура програми може бути ускладнена. Однак ці підпрограми можуть розташовуватися на одному рівні вкладеності, тому спочатку має йти опис підпрограми, а потім звернення до неї, якщо не використовується спеціальний випереджальний опис. Опис процедури, що містить замість блоку операторів директиву forward, називається випереджаючим описом. У будь-якому місці після цього опису за допомогою визначального опису процедура має визначатися. Визначальний опис - це опис, в якому використовується той же ідентифікатор процедури, але опущений список формальних параметрів, і включений блок операторів. Опис forward та визначальний опис повинні бути присутніми в одній і тій же частині опису процедури та функції. Між ними можуть описуватися інші процедури та функції, які можуть звертатися до процедури з випереджаючим описом. Таким чином, можлива взаємна рекурсія. Випереджальний опис та визначальний опис є повним описом процедури. Процедура вважається описаною за допомогою випереджального опису. Якщо програмі буде утримуватися чимало підпрограм, то програма перестане бути наочною, у ній важко орієнтуватися. Щоб уникнути цього, деякі підпрограми зберігають у вигляді вихідних файлів на диску, а при необхідності вони підключаються до основної програми на етапі компіляції за допомогою директиви компіляції. Директива – це спеціальний коментар, який може бути розміщений у будь-якому місці програми, там, де може знаходитись і звичайний коментар. Однак вони відрізняються тим, що директива має спеціальну форму запису: відразу після закриває дужки без пропуску записується знак $, а потім, знову ж таки без пропуску, вказується директива. Приклад: 1) {$E+} - емулювати математичний співпроцесор; 2) {$F+} - формувати далекий тип виклику процедур та функцій; 3) {$N+} - використовувати математичний співпроцесор; 4) {$R+} - перевіряти вихід за межі діапазонів. Деякі ключі компіляції можуть містити параметр, наприклад: {$I ім'я файлу} - включити в текст програми, що компілюється, названий файл 9. Параметри підпрограм У описі процедури чи функції задається список формальних параметрів. Кожен параметр, описаний у списку формальних параметрів, є локальним по відношенню до процедури або функції, що описується, і в модулі, пов'язаному з даною процедурою або функцією, на нього можна посилатися за його ідентифікатором. Існує три типи параметрів: значення, змінна та нетипізована змінна. Вони характеризуються таким: 1. Група параметрів без попереднього ключового слова є список параметрів-значень. 2. Група параметрів, перед якими слідує ключове слово const і за якими слідує тип, є списком параметрів-констант. 3. Група параметрів, перед якими стоїть ключове слово var і за якими слідує тип, є списком параметрів-змінних. Параметри-значення Формальний параметр-значення обробляється як локальна по відношенню до процедури або функції змінна, за винятком того, що він отримує своє початкове значення з відповідного фактичного параметра при активізації процедури або функції. Зміни, які зазнає формального параметра-значення, не впливають на значення фактичного параметра. Відповідне фактичне значення параметра значення має бути виразом, і його значення не повинно мати файловий тип або будь-який структурний тип, що містить у собі файловий тип. Фактичний параметр повинен мати тип, сумісний для присвоєння з типом формального параметра-значення. Якщо параметр має рядковий тип, формальний параметр матиме атрибут розміру, рівний 255. Параметри-константи У тілі підпрограми значення параметра-константи не можна змінити. Параметрами-константами можна оформити параметри, зміни яких у підпрограмі небажано і має бути заборонено. Параметри-змінні Параметр-змінна використовується у випадках, коли значення має бути передано з підпрограми до блоку, що викликає. У цьому випадку під час виклику підпрограми формальний параметр заміщується аргументом-змінною, і будь-які зміни формального параметра відображаються на аргументі. Процедурні змінні Після визначення процедурного типу з'являється можливість описувати змінні цього. Такі змінні називають процедурними змінними. Як і ціла змінна, якій можна надати значення цілого типу, процедурної змінної можна надати значення процедурного типу. Таким значенням може бути, звичайно, інша процедурна змінна, але воно може також бути ідентифікатором процедури або функції. У такому контексті опис процедури або функції можна розглядати як опис особливого роду константи, значенням якої є процедура або функція. Як і при будь-якому іншому присвоюванні, значення змінної в лівій і правій частині повинні бути сумісні з присвоєння. Процедурні типи, щоб вони були сумісні за присвоєнням, повинні мати те саме число параметрів, а параметри на відповідних позиціях повинні бути однакового типу. Імена параметрів в описі процедурного типу жодної дії не викликають. Крім того, для забезпечення сумісності щодо присвоєння процедура або функція, якщо її потрібно привласнити процедурній змінній, не повинна бути стандартною або вкладеною. 10. Типи параметрів підпрограм Параметри-значення Формальний параметр-значення обробляється як локальна змінна, він отримує своє початкове значення відповідного фактичного параметра при активізації процедури або функції. Зміни, які зазнає формального параметра-значення, не впливають на значення фактичного параметра. Відповідне фактичне значення параметра значення має бути виразом, і його значення не повинно мати файловий тип. Параметри-константи Формальні параметри-константи набувають свого значення при активізації процедури або функції. Присвоєння формальному параметру-константі не допускаються. Формальний параметр-константа не може передаватися як фактичний параметр іншій процедурі або функції. Параметри-змінні Параметр-змінна використовується, коли значення має передаватися з процедури або функції програмі, що викликає. При активізації формальний параметр-змінна заміщається фактичною змінною, зміни формального параметра-змінної відбиваються на фактичному параметрі. Нетипізовані параметри Коли формальний параметр є нетипізованим параметром-змінною, то відповідний фактичний параметр може бути посиланням на змінну або константу. Нетипізований параметр, описаний з ключовим словом var, може бути модифікований, а нетипізований параметр, описаний з ключовим словом const, доступний тільки за читанням. Процедурні змінні Після визначення процедурного типу з'являється можливість описувати змінні цього. Такі змінні називають процедурними змінними. Процедурною змінною можна визначити значення процедурного типу. Процедура або функція при присвоєнні має бути: 1) не стандартною; 2) не вкладеної; 3) не процедурою типу inline; 4) не процедурою переривання (interrupt). Параметри процедурного типу Оскільки процедурні типи допускається використовувати в будь-якому контексті, можна описувати процедури або функції, які сприймають процедури і функції як параметри. Параметри процедурного типу особливо корисні у разі, коли над безліччю процедур чи функцій потрібно виконати якісь спільні дії. Якщо процедура або функція повинні передаватися як параметр, вони повинні задовольняти ті самі правила сумісності типу, що і при присвоєнні. Тобто такі процедури або функції повинні компілюватися з директивою far, вони не можуть бути вбудованими функціями, не можуть бути вкладеними та не можуть описуватися з атрибутами inline або interrupt. 11. Рядковий тип у Pascal. Процедури та функції для змінних рядкового типу Послідовність символів певної довжини називається рядком. Змінні рядкового типу визначаються шляхом вказівки імені змінної, зарезервованого слова string, і можливо, але не обов'язково вказівки максимального розміру, тобто довжини рядка у квадратних дужках. Якщо не задавати максимальний розмір рядка, то за умовчанням він дорівнює 255, тобто рядок складатиметься з 255 символів. До кожного елемента рядка можна звернутися за його номером. Однак введення та виведення рядків здійснюються повністю, а не поелементно, як це відбувається в масивах. Число введених символів не повинно перевищувати вказаного в максимальному розмірі рядка, так якщо таке перевищення буде, то "зайві" символи будуть проігноровані. Процедури та функції для змінних рядкового типу 1. Function Copy(S: String; Index, Count: Integer): String; Повертає рядок рядок. S – вираз типу String. Index і Count – вирази цілого типу. Функція повертає рядок, що містить Count символів, що починаються з позиції Index. Якщо Index більший за довжину S, функція повертає порожній рядок. 2. Procedure Delete (var S: String; Index, Count: Integer); Видаляє підстроку символів довжиною Count із рядка S, починаючи з позиції Index. S – змінна типу String. Index і Count – вирази цілого типу. Якщо Index більший за довжину S, символи не видаляються. 3. Procedure Insert(Source: String; var S: String; Index: Integer); Поєднує підрядок у рядок, починаючи з певної позиції. Source – вираз типу String. S – змінна типу String будь-якої довжини. Index - вираз цілого типу. Insert вставляє Source S, починаючи з позиції S. 4. Function Length(S: String): Integer; Повертає число символів, що фактично використовується в рядку S. Зверніть увагу: при використанні рядків з нуль-закінченням число символів не обов'язково дорівнює числу байтів. 5. Function Pos(Substr: String; S: String): Integer; Шукає підрядок у рядку. Pos шукає Substr всередині S і повертає ціле значення, яке є індексом першого символу Substr всередині S. Якщо Substr не знайдено, Pos повертає нуль. 12. Записи Запис є сукупність обмеженого числа логічно пов'язаних компонентів, що належать до різних типів. Компоненти запису називаються полями, кожне з яких визначається ім'ям. Поле запису містить ім'я поля, за яким через двокрапку вказується тип цього поля. Поля запису можуть відноситися до будь-якого типу, допустимого в Pascal, за винятком файлового типу. Опис запису в мові Pascal здійснюється за допомогою службового слова RECORD, за яким описуються компоненти запису. Завершується опис запису службовим словом END. Наприклад, записник містить прізвища, ініціали та номери телефону, тому окремий рядок у записнику зручно представити у вигляді наступного запису: type Row = Record FIO: String[20]; TEL: String[7]; end; var str: Row; Опис записів можливий і без використання імені типу, наприклад: var str: Record FIO: String[20]; TEL: String[7]; end; Звертання до запису загалом допускається лише операторах присвоювання, де ліворуч і праворуч від знака присвоювання використовуються імена записів однакового типу. У решті випадків оперують окремими полями записів. Щоб звернутися до окремого компонента запису, необхідно вказати ім'я запису та через точку вказати ім'я потрібного поля. Таке ім'я називається складовим. Компонентом запису може бути запис, у такому разі складене ім'я міститиме не два, а більшу кількість імен. Звернення до компонентів записів можна спростити, якщо скористатися оператором приєднання with. Він дозволяє замінити складові імена, що характеризують кожне поле просто на імена полів, а ім'я запису визначити в операторі приєднання. Іноді вміст окремого запису залежить від значення одного з його полів. У мові Pascal допускається опис запису, що складається із загальної та варіантної частин. Варіантна частина визначається за допомогою конструкції case P of, де Р - ім'я поля із загальної частини запису. Можливі значення, що приймаються цим полем, перераховуються так само, як і в операторі варіанта. Однак замість вказівки виконуваної дії, як це робиться в операторі варіанта, вказуються поля варіанта, укладені у круглі дужки. Опис варіантної частини завершується службовим словом end. Тип поля Р можна вказати у заголовку варіантної частини. Ініціалізація записів здійснюється за допомогою типізованих констант. 13. Безліч Поняття множини в мові Pascal ґрунтується на математичному уявленні про множини: це обмежена сукупність різних елементів. Для побудови конкретного множинного типу використовується перерахований або інтервальний тип даних. Тип елементів, що становлять безліч, називається базовим типом. Множинний тип описується за допомогою службових слів Set of, наприклад: type M = Set of B; тут М – множинний тип, В – базовий тип. Приналежність змінних до множинного типу може бути визначена у розділі опису змінних. Константи множинного типу записуються у вигляді укладеної у квадратні дужки послідовності елементів або інтервалів базового типу, розділених комами. До змінних і константів множини застосовні операції присвоєння (:=), об'єднання (+), перетину (*) і віднімання (-). Результат виконання цих операцій є величина множинного типу: 1) ['A','B'] + ['A','D'] дасть ['A','B','D']; 2) ['A'] * ['A','B','C'] дасть ['A']; 3) ['A','B','C'] - ['A','B'] дасть ['C'] До множинних величин застосовні операції: тотожність (=), нетотожність (<>), міститься в (<=), містить (>=). Результат виконання цих операцій має логічний тип: 1) ['A','B'] = ['A','C'] дасть FALSE; 2) ['A','B'] <> ['A','C'] дасть TRUE; 3) ['B'] <= ['B','C'] дасть TRUE; 4) ['C','D'] >= ['A'] дасть FALSE. Крім цих операцій, для роботи з величинами множинного типу використовується операція in, що перевіряє належність елемента базового типу, що стоїть ліворуч від знака операції, множині, що стоїть праворуч від знака операції. Результат виконання цієї операції – булевський. Величини множини не можуть бути елементами списку введення-виводу. У кожній конкретній реалізації транслятора з мови Pascal кількість елементів базового типу, на якому будується безліч, обмежена. 14. Файли. Операції з файлами Файловий тип даних визначає впорядковану сукупність однотипних компонентів. Під час роботи з файлами виконуються операції вводу-виводу. Операція введення - це перепис даних із зовнішнього пристрою на пам'ять, операція виведення - пересилання даних із пам'яті на зовнішній пристрій. Текстові файли Для опису таких файлів є тип Text: var TF1, TF2: Text; Компонентні файли Компонентний або типізований файл - це файл з оголошеним типом його компонент. type M = File Of T; де М – ім'я файлового типу; Т – тип компоненти. Операції здійснюються за допомогою процедур. Write (f, X1, X2, ... XK) Безтипові файли Безтипові файли дозволяють записувати на диск довільні ділянки пам'яті ЕОМ та зчитувати їх. var f: File; 1. Procedure Assign(var F; FileName: String); Вона зіставляє ім'я файлу зі змінною. 2. Procedure Close(var F); Вона розриває зв'язок між файловою змінною та зовнішнім дисковим файлом і закриває файл. 3. Function Eof(var F): Boolean; {Типізовані або нетипізовані файли} Function Eof[(var F: Text)]: Boolean; {Текстові файли} Перевіряє наприкінці файлу. 4. Procedure Erase(var F); Видаляє зовнішній файл, пов'язаний із F. 5. Function FileSize(var F): Integer; Повертає розмір у байтах файлу F. 6. Function FilePos(var F): LongInt; Повертає поточну позицію у файлі. 7. Procedure Reset (var F [: File; RecSize: Word]); Відкриває наявний файл. 8. Procedure Rewrite(var F: File [; Recsize: Word]); Створює та відкриває новий файл. 9. Procedure Seek(var F; N: LongInt); Переміщує поточну позицію файлу до певного компонента. 10. Procedure Append(var F: Text); Дозапис. 11. Function Eoln [(var F: Text)]: Boolean; Перевіряє на кінець рядка. 12. Procedure Read (F, V1 [, V2 ..., Vn]); {Типізовані та нетипізовані файли} Procedure Read([var F: Text;] V1[, V2..., Vn]); {Текстові файли} Читає компонент файлу змінну. 13. Procedure Readln([var F: Text;] V1 [, V2..., Vn]); Зчитує рядок символів у файлі, включаючи маркер кінця рядка, та переходить до початку наступного. 14. Function SeekEof [(var F: Text)]: Boolean; Повертає ознаку кінця файлу. Використовується лише для відкритих текстових файлів. 15. Procedure Writeln([var F: Text;] [P1, P2..., Pn]); {Текстові файли} Виконує операцію Write, потім поміщає мітку кінця рядка файл. 15. Модулі. Види модулів Модуль (UNIT) Pascal - це особливим чином оформлена бібліотека підпрограм. Модуль, на відміну програми, може бути запущений виконання самостійно, може лише брати участь у побудові програм та інших модулів. Модуль Pascal є окремо зберігається і незалежно компилируемую програмну одиницю. Всі програмні елементи модуля можна розбити на дві частини: 1) програмні елементи, призначені для використання іншими програмами або модулями, такі елементи називають видимими поза модулем; 2) програмні елементи, необхідних лише роботи самого модуля, їх називають невидимими (чи прихованими). unit <ім'я модуля>; {заголовок модуля} інтерфейс {Опис видимих програмних елементів модуля} реалізація {опис прихованих програмних елементів модуля} починати {оператори ініціалізації елементів модуля} end. Для звернення до змінної, описаної в модулі, необхідно застосувати складове ім'я, що складається з імені модуля та імені змінної, розділених точкою. Рекурсивне використання модулів заборонено. Перерахуємо, які види модулів бувають. 1. Модуль SYSTEM. Модуль SYSTEM реалізує підтримуючі підпрограми нижнього рівня для всіх вбудованих засобів, таких як введення-виведення, робота з рядками, операції з плаваючою точкою та динамічний розподіл пам'яті. 2. Модуль DOS. Модуль Dos реалізує численні процедури та функції Pascal, які еквівалентні найчастіше використовуваним викликам DOS, як, наприклад, GetTime, SetTime, DiskSize і таке інше. 3. Модуль CRT. Модуль CRT реалізує ряд потужних програм, що надають повну можливість керування засобами комп'ютера РС, такими як керування режимом екрана, розширені коди клавіатури, кольори, вікна та звукові сигнали. 4. Модуль GRAPH. За допомогою процедур і функцій, що входять до цього модуля, можна створювати різні графічні зображення на екрані. 5. Модуль OVERLAY. Модуль OVERLAY дає змогу зменшити вимоги до пам'яті програми DOS реального режиму. 16. Посилальний тип даних. Динамічна пам'ять. Динамічні змінні. Робота з динамічною пам'яттю Статичною змінною (статично розміщеною) називається описана явним чином у програмі змінна, звернення до неї здійснюється на ім'я. Місце пам'яті розміщувати статичних змінних визначається при компіляції програми. На відміну від таких статичних змінних програм, написаних мовою Pascal, можуть бути створені динамічні змінні. Основна властивість динамічних змінних у тому, що вони створюються, і пам'ять їм виділяється під час виконання програми. Розміщуються динамічні змінні динамічної області пам'яті (heap-области). Динамічна змінна явно не вказується в описах змінних, і до неї не можна звернутися по імені. Доступ до таких змінних здійснюється за допомогою покажчиків та посилань. Посилальний тип (покажчик) визначає безліч значень, які вказують на динамічні змінні певного типу, що називається базовим типом. Змінна посилання типу містить адресу динамічної змінної в пам'яті. Якщо базовий тип є ще не описаним ідентифікатором, то він повинен бути описаний в тій же частині опису типів, що і тип-покажчик. Зарезервоване слово nil означає константу зі значенням покажчика, яка ні на що не вказує. Наведемо приклад опису динамічних змінних. var p1, p2: ^real; p3, p4: ^integer; ... Процедури та функції роботи з динамічною пам'яттю 1. Процедура New (var p: Pointer). Виділяє місце в динамічній області пам'яті для розміщення динамічної змінної p", і її адреса надає покажчику p. 2. Процедура Dispose (var p: Pointer). Звільняє ділянку пам'яті, виділений розміщення динамічної змінної процедурою New, і значення покажчика p стає невизначеним. 3. Процедура GetMem (var p: Pointer; size: Word). Виділяє ділянку пам'яті в heap-області, надає адресу його початку покажчику p, розмір ділянки в байтах визначається параметром size. 4. Процедура FreeMem (varp: Pointer; size: Word). Звільняє ділянку пам'яті, адресу початку якого визначено покажчиком p, а розмір - параметром size. Значення покажчика p стає невизначеним. 5. Процедура Mark (var p: Pointer) записує в покажчик p адресу початку ділянки вільної динамічної пам'яті на момент її виклику. 6. Процедура Release (var p: Pointer) звільняє ділянку динамічної пам'яті, починаючи з адреси, записаної в покажчик p процедурою Mark, тобто очищає ту динамічну пам'ять, яка була зайнята після виклику процедури Mark. 7. Функція MaxAvail: Longint повертає довжину в байтах найдовшої вільної ділянки динамічної пам'яті. 8. Функція MemAvail: Longint повертає повний обсяг вільної динамічної пам'яті у байтах. 9. Допоміжна функція SizeOf(X): Word повертає обсяг у байтах, який займає X, причому X може бути або ім'ям змінної будь-якого типу, або ім'ям типу. 17. Абстрактні структури даних Структуровані типи даних, такі як масиви, множини, записи, є статичні структури, оскільки їх розміри незмінні протягом усього часу виконання програми. Часто потрібно, щоб структури даних змінювали свої розміри під час вирішення завдання. Такі структури даних називають динамічними. До них належать стеки, черги, списки, дерева та ін. Опис динамічних структур за допомогою масивів, записів та файлів призводить до неекономного використання пам'яті ЕОМ та збільшує час вирішення завдань. Кожна компонента будь-якої динамічної структури є записом, що містить, принаймні, два поля: одне поле типу "покажчик", а друге - для розміщення даних. У випадку запис може містити не один, а кілька покажчиків і кілька полів даних. Поле даних може бути змінною, масивом, множиною або записом. Якщо вказівна частина містить адресу одного елемента списку, то список називається односпрямованим (або однозв'язним). Якщо він містить дві компоненти, то двозв'язним. Над списками можна проводити різні операції, наприклад: 1) додавання елемента до списку; 2) видалення елемента зі списку із заданим ключем; 3) пошук елемента із заданим значенням ключового поля; 4) сортування елементів списку; 5) розподіл списку на два і більше списків; 6) об'єднання двох і більше списків до одного; 7) інші операції. Однак, як правило, потреби у всіх операціях при вирішенні різних завдань не виникає. Тому, залежно від основних операцій, які необхідно застосувати, існують різні види списків. Найбільш популярні з них – це стек та черга. 18. Стеки Стеком називається динамічна структура даних, додавання компоненти в яку і виняток компоненти з якої виробляється з одного кінця, що називається вершиною стека. Стек працює за принципом LIFO (Last-In, First-Out) - "Той, що поступив останнім, обслуговується першим". Зазвичай над стеками виконується три операції: 1) початкове формування стека (запис першої компоненти); 2) додавання компоненти до стек; 3) вибірка компоненти (видалення). Для формування стека та роботи з ним необхідно мати дві змінні типу "покажчик", перша з яких визначає вершину стека, а друга - допоміжна. приклад. Скласти програму, яка формує стек, додає до нього довільну кількість компонент, а потім читає всі компоненти. Program STACK; uses Crt; тип Alfa = String [10]; PComp = ^Comp; Comp = Record sD: Alfa; pNext: PComp end; було pTop: PComp; sC: Alfa; Procedure CreateStack(var pTop: PComp; var sC: Alfa); починати New (pTop); pTop^.pNext:= NIL; pTop^.sD:= sC; end; Procedure AddComp(var pTop: PComp; var sC: Alfa); var pAux: PComp; починати NEW (pAux); pAux^.pNext:= pTop; pTop: = pAux; pTop^.sD:= sC; end; Procedure DelComp (var pTop: PComp; var sC: ALFA); починати sC:= pTop^.sD; pTop:= pTop^.pNext; end; починати Clrscr; writeln( ВВЕДИ РЯДКУ ); readln(sC); CreateStack(pTop, sC); повторювати writeln( ВВЕДИ РЯДКУ ); readln(sC); AddComp(pTop, sC); until sC = 'END'; 19. Черги Чергою називається динамічна структура даних, додавання компоненти в яку проводиться в один кінець, а вибірка здійснюється з іншого кінця. Черга працює за принципом FIFO (First-In, First-Out) - "Вступив першим, обслуговується першим". приклад. Скласти програму, яка формує чергу, додає до неї довільну кількість компонент, а потім читає всі компоненти. Program QUEUE; uses Crt; тип Alfa = String [10]; PComp = ^Comp; Comp = record sD: Alfa; pNext: PComp; end; було pBegin, pEnd: PComp; sC: Alfa; Procedure CreateQueue(var pBegin, pEnd: PComp; var sC: Alfa); починати New (pBegin); pBegin^.pNext:= NIL; pBegin^.sD:= sC; pEnd: = pBegin; end; Procedure AddQueue(var pEnd: PComp; var sC: Alfa); var pAux: PComp; починати New (pAux); pAux^.pNext:= NIL; pEnd^.pNext:= pAux; pEnd: = pAux; pEnd^.sD:= sC; end; Procedure DelQueue(var pBegin: PComp; var sC: Alfa); починати sC:= pBegin^.sD; pBegin:= pBegin^.pNext; end; починати Clrscr; writeln( ВВЕДИ РЯДКУ ); readln(sC); CreateQueue(pBegin, pEnd, sC); повторювати writeln( ВВЕДИ РЯДКУ ); readln(sC); AddQueue(pEnd, sC); until sC = 'END'; 20. Деревоподібні структури даних Деревоподібною структурою даних називається кінцева множина елементів-вузлів, між якими існують відносини - зв'язок вихідного та породженого. Якщо використовувати рекурсивне визначення, запропоноване М. Віртом, деревоподібна структура даних з базовим типом t - це або порожня структура, або вузол типу t, з яким пов'язане кінцеве безліч деревоподібних структур з базовим типом t, званих піддеревами. Далі дамо визначення, що використовуються під час оперування деревоподібними структурами. Якщо вузол y знаходиться безпосередньо під вузлом х, то вузол y називається безпосереднім нащадком вузла х, а x - безпосереднім предком вузла у, тобто якщо вузол хнаходиться на i-му рівні, то відповідно вузол y знаходиться на (i + 1 ) - ом рівні. Максимальний рівень вузла дерева називається висотою чи глибиною дерева. Предка не має лише одного вузол дерева - його коріння. Вузли дерева, які не мають нащадків, називаються термінальними вузлами (або листами дерева). Усі інші вузли називаються внутрішніми вузлами. Кількість безпосередніх нащадків вузла визначає ступінь цього вузла, а максимально можливий ступінь вузла у цьому дереві визначає ступінь дерева. Предків і нащадків не можна поміняти місцями, т. е. зв'язок вихідного і породженого діє лише одному напрямі. Якщо пройти від кореня дерева до певного конкретного вузла, то кількість гілок дерева, яке буде пройдено, називається довжиною шляху цього вузла. Якщо всі гілки (вузли) у дерева впорядковані, дерево називається впорядкованим. Окремим випадком деревоподібних структур є бінарні дерева. Це дерева, у яких кожен нащадок має трохи більше двох нащадків, званих лівим і правим поддеревами. Таким чином, бінарне дерево - це деревоподібна структура, ступінь якої дорівнює двом. Упорядкованість бінарного дерева визначається за таким правилом: кожному вузлу відповідає своє ключове поле, і для кожного вузла значення ключа більше всіх ключів у його лівому піддереві і найменше всіх ключів у його правому піддереві. Дерево, ступінь якого більше двох, називається сильнорозгалуженим. 21. Операції над деревами Далі будемо розглядати всі операції стосовно бінарних дерев. I. Побудова дерева. Наведемо алгоритм побудови впорядкованого дерева. 1. Якщо дерево порожнє, дані переносяться в корінь дерева. Якщо дерево не порожнє, то здійснюється спуск по одній з його гілок таким чином, щоб упорядкованість дерева не порушувалася. В результаті новий вузол стає черговим аркушем дерева. 2. Щоб додати вузол у вже існуюче дерево, можна скористатися наведеним вище алгоритмом. 3. У разі видалення вузла з дерева слід бути уважним. Якщо видалений вузол є листом, або має тільки одного нащадка, то операція проста. Якщо ж вузол, що видаляється, має двох нащадків, то необхідно буде знайти вузол серед його нащадків, який можна буде поставити на його місце. Це необхідно через вимогу впорядкованості дерева. Можна вчинити таким чином: поміняти вузол, що видаляється місцями з вузлом, що має найбільше значення ключа в лівому піддереві, або з вузлом, що має найменше значення ключа в правому піддереві, а потім видалити шуканий вузол як лист. ІІ. Пошук вузла із заданим значенням ключового поля. При здійсненні цієї операції необхідно здійснити обхід деревини. Необхідно враховувати різні форми запису дерева: префіксний, інфіксний і постфіксний. Виникає питання: як уявити вузли дерева, щоб було зручніше працювати із нею? Можна представляти дерево за допомогою масиву, де кожен вузол описується величиною комбінованого типу, яка має інформаційне поле символьного типу і два поля посилання типу. Але це не зовсім зручно, тому що дерева мають велику кількість вузлів, що заздалегідь не визначене. Тому краще при описі дерева використовувати динамічні змінні. Тоді кожен вузол представляється величиною одного типу, що містить опис заданої кількості інформаційних полів, а кількість відповідних полів має дорівнювати ступеню дерева. Логічно відсутність нащадків визначати за посиланням nil. Тоді на мові Pascal опис бінарного дерева може виглядати так: TYPE TreeLink = ^Tree; Tree = record; Inf: <тип даних>; Left, Right: TreeLink; Кінець. 22. Приклади реалізації операцій 1. Побудувати дерево із вузлів мінімальної висоти, або ідеально збалансоване дерево (кількість вузлів лівого та правого піддерев'я такого дерева повинні відрізнятися не більше ніж на одиницю). Рекурсивний алгоритм побудови: 1) перший вузол береться як корінь дерева; 2) тим самим способом будується ліве поддерево з nl вузлів; 3) тим самим способом будується праве поддерево з nr вузлів; nr = n - nl - 1 Як інформаційне поле братимемо номери вузлів, що вводяться з клавіатури. Рекурсивна функція, що реалізує цю побудову, буде виглядати так: Function Tree(n: Byte): TreeLink; Var t: TreeLink; nl, nr, x: Byte; Починати If n = 0 then Tree:= nil Ще Починати nl:= n div 2; nr = n - nl - 1; writeln('Введіть номер вершини); readln(x); new(t); t^.inf: = x; t^.left: = Tree (nl); t^.right: = Tree (nr); Tree: = t; Кінець; {Tree} Кінець. 2. У бінарному упорядкованому дереві знайти вузол із заданим значенням ключового поля. Якщо такого елемента у дереві немає, то додати його до дерева. Procedure Search(x: Byte; var t: TreeLink); Починати If t = nil then Починати New(t); t^inf:= x; t^.left:= nil; t^.right:= nil; кінець Else if x < t^.inf then Search(x, t^.left) Else if x > t^.inf then Search(x, t^.right) Ще Починати {обробка знайденого елемента} ... Кінець; Кінець. 23. Поняття графа. Способи подання графа Граф - пара G = (V,E), де V - безліч об'єктів довільної природи, званих вершинами, а E - сімейство пар ei = (vil, vi2), vijOV, званих ребрами. У загальному випадку безліч V та (або) сімейство E можуть містити нескінченну кількість елементів, але ми розглядатимемо тільки кінцеві графи, тобто графи, у яких як V, так і E кінцеві. Якщо порядок елементів, що входять до ei, має значення, то граф називається орієнтованим, скорочено – орграф, інакше – неорієнтованим. Ребра орграф називаються дугами. Якщо e = , то вершини v і називаються кінцями ребра. У цьому говорять, що ребро e є суміжним (інцидентним) кожної з вершин v і в. Вершини v і також називаються суміжними (інцидентними). У випадку допускаються ребра виду e = ; такі ребра називаються петлями. Ступінь вершини графа - це число ребер, інцидентних даній вершині, причому петлі враховуються двічі. Вага вершини - число (дійсне, ціле або раціональне), поставлене у відповідність даній вершині (інтерпретується як вартість, пропускна спроможність тощо). Шляхом у графі (або маршрутом в орграфі) називається послідовність вершин і ребер (або дуг - в орграфі) виду v0, (v0,v1), v1,..., (vn -1,vn), vn. Число n називається довжиною шляху. Шлях без ребер, що повторюються, називається ланцюгом, без повторюваних вершин - простим ланцюгом. Замкнутий шлях без повторюваних ребер називається циклом (або контуром в орграфі); без повторюваних вершин (крім першої та останньої) - простим циклом. Граф називається зв'язковим, якщо існує шлях між будь-якими двома його вершинами, і незв'язним - інакше. Існують різні способи представлення графів. 1. Матриця інцидентності. Це прямокутна матриця розмірності n год m, де n – кількість вершин, а m – кількість ребер. 2. Матриця суміжності. Це квадратна матриця розмірності n год n, де n – кількість вершин. 3. Список суміжності (інцидентності). Є структурою даних, яка для кожної вершини графа зберігає список суміжних із нею вершин. Список являє собою масив покажчиків, i-ий елемент якого містить покажчик на список вершин, суміжних з i-ою вершиною. 4. Список списків. Є деревоподібною структурою даних, в якій одна гілка містить списки вершин, суміжних для кожної. 24. Різні уявлення графа Для реалізації графа у вигляді списку інцидентності можна використовувати такий тип: Type List = ^S; S = record; inf: Byte; next: List; end; Тоді граф задається так: Var Gr: array[1..n] of List; Тепер звернемося до процедури обходу графа. Це допоміжний алгоритм, який дає змогу переглянути всі вершини графа, проаналізувати усі інформаційні поля. Якщо розглядати обхід графа в глибину, то є два типи алгоритмів: рекурсивний і нерекурсивний. На мові Pascal процедура обходу в глибину буде виглядати так: Procedure Obhod (gr: Graph; k: Byte); Var g: Graph; l: List; Починати nov[k]:= false; g:= gr; While g^.inf <> k do g:= g^.next; l:= g^.smeg; While l <> nil do begin If nov[l^.inf] then Obhod(gr, l^.inf); l:= l^.next; Кінець; Кінець; Подання графа списком списків Граф можна визначити за допомогою списку списків таким чином: Type List = ^Tlist; Tlist = record inf: Byte; next: List; end; Graph = ^TGpaph; TGpaph = record inf: Byte; smeg: List; next: Graph; end; При обході графа завширшки ми вибираємо довільну вершину і проглядаємо відразу всі вершини, суміжні з нею. Наведемо процедуру обходу графа завширшки на псевдокоді: Procedure Obhod2(v); Починати queue = O; queue <= v; nov [v] = False; While queue <> O do Починати p<=queue; For u in spisok(p) do If nov[u] then Починати nov[u]: = False; queue <= u; Кінець; Кінець; Кінець; 25. Об'єктний тип у Pascal. Поняття об'єкта, його опис та використання Об'єктно-орієнтована мова програмування характеризується трьома основними властивостями: 1) інкапсуляція. Комбінування записів з процедурами та функціями, що маніпулюють полями цих записів, формує новий тип даних - об'єкт; 2) успадкування. Визначення об'єкта та його подальше використання для побудови ієрархії породжених об'єктів з можливістю для кожного породженого об'єкта, що відноситься до ієрархії, доступу до коду та даних всіх об'єктів, що породжують; 3) поліморфізм. Привласнення дії одного імені, яке потім спільно використовується вниз і вгору по ієрархії об'єктів, причому кожен об'єкт ієрархії виконує цю дію способом саме йому відповідним. Говорячи про об'єкт, ми вводимо до нового типу даних - об'єктний. Об'єктний тип є структурою, що з фіксованого числа компонентів. Кожен компонент є полем, що містить дані строго певного типу, або методом, що виконує операції над об'єктом. Об'єктний тип може наслідувати компоненти іншого об'єктного типу. Якщо тип T2 успадковує від типу T1, то тип T2 є нащадком типу Р, а сам тип Р є батьком типу Г2. Наступний вихідний код наводить приклад опису об'єктного типу. тип Point = об'єкт X, Y: integer; end; Rect = об'єкт A, B: TPoint; procedure Init(XA, YA, XB, YB: Integer); procedure Copy(var R: TRectangle); procedure Move(DX, DY: Integer); procedure Grow(DX, DY: Integer); procedure Intersect(var R: TRectangle); procedure Union(var R: TRectangle); функція Contains(P: Point): Boolean; end; На відміну від інших типів, об'єктні типи можуть описуватися лише в розділі описів типів, що знаходиться на зовнішньому рівні області дії програми або модуля. Таким чином, об'єктні типи не можуть описуватися в розділі описів змінних або всередині процедури, функції або методу. Тип компоненти файлового типу не може мати об'єктний тип або структурний тип, що містить компоненти об'єктного типу. 26. Спадкування Спадкування - це процес породження нових типів-нащадків від існуючих типів-батьків, при цьому нащадок отримує (успадковує) від батька всі його поля та методи. Тип-нащадок, у своїй, називається спадкоємцем чи породженим (дочірнім) типом. А тип, якому успадковує дочірній тип, називається породжувальним (батьківським) типом. Наслідувані поля та методи можна використовувати у незмінному вигляді або перевизначати (модифікувати). Н. Вірт у своїй мові Паскаль прагнув максимальної простоти, тому він не став його ускладнювати запровадженням відносини спадкування. Тому типи в Паскалі не можуть наслідувати. Однак Turbo Pascal 7.0 розширює цю мову для підтримки спадкування. Одним із таких розширень є нова категорія структури даних, пов'язана із записами, але значно потужніша. Типи даних у цій новій категорії визначаються за допомогою нового зарезервованого Object. Синтаксис дуже схожий на синтаксис визначення записів: тип <ім'я типу> = Object [(<ім'я типу батька>)] ([<область дії>] <опис полів та методів>)+ end; Знак "+" після синтаксичної конструкції в круглих дужках означає, що ця конструкція повинна зустрічатися один або більше разів у цьому описі. Область дії є одним із наступних ключових слів: ▪ Private; ▪ Protected; ▪ Public. Область дії характеризує, яким ділянкам програми будуть доступні компоненти, описи яких слідують за ключовим словом, що називає цю область дії. Докладніше про сфери дії компонент розказано у питанні № 28. Спадкування - це потужний інструмент, який використовується для розробки програм. Воно дозволяє реалізувати практично об'єктно-орієнтовану декомпозицію завдання, засобами мови висловлювати відносини між об'єктами типів, що утворюють ієрархію, і навіть сприяє повторному використанню програмного коду. 27. Створення екземплярів об'єктів Примірник об'єкта створюється за допомогою опису змінної або константи об'єктного типу або шляхом застосування стандартної процедури New до змінної типу "покажчик на об'єктний тип". Результуючий об'єкт називається екземпляром об'єктного типу. Якщо об'єктний тип містить віртуальні методи, екземпляри цього об'єктного типу повинні ініціалізуватися за допомогою виклику конструктора перед викликом будь-якого віртуального методу. Привласнення екземпляра об'єктного типу не передбачає ініціалізації екземпляра. Об'єкт ініціалізується кодом, що генерується компілятором, який виконується між викликом конструктора і моментом, коли виконання фактично досягає першого оператора в блоці коду конструктора. Якщо екземпляр об'єкта не ініціалізується і перевірка діапазону включена (директивою {$R+}), перший виклик віртуального методу екземпляра об'єкта дає помилку етапу виконання. Якщо перевірка діапазону вимкнена директивою {$R-}), перший виклик віртуального методу неініціалізованого об'єкта може призвести до непередбачуваної поведінки. Правило обов'язкової ініціалізації застосовується також до екземплярів, що є компонентами структурних типів. Наприклад: було Comment: array [1..5] of TStrField; I: integer; починати for I:= 1 to 5 do Comment [I]. Init (1, I + 10, 40, 'перше_ім'я'); . . . for I:= 1 to 5 do Comment [I].Done; end; Для динамічних екземплярів ініціалізація зазвичай пов'язана з розміщенням, а очищення - з видаленням, що досягається завдяки розширеному синтаксису стандартних процедур New і Dispose. Наприклад: було SP: StrFieldPtr; починати New (SP, Init (1, 1, 25, 'перше_ім'я'); SP^.Put ("Володимир"); SP^.Display; . . . Dispose (SP, Done); end. Вказівник на об'єктний тип є сумісним за присвоєнням з вказівником на будь-який батьківський об'єктний тип, тому під час виконання програми вказівник на об'єктний тип може вказувати на екземпляр цього типу або екземпляр будь-якого дочірнього типу. 28. Компоненти та сфера дії Область дії ідентифікатора компоненти тягнеться за межі об'єктного типу. Більш того, область дії ідентифікатора компонента простягається крізь блоки процедур, функцій, конструкторів та деструкторів, які реалізують методи об'єктного типу та його спадкоємців. Виходячи з цих міркувань, ідентифікатор компоненти повинен бути унікальним всередині об'єктного типу і всередині всіх його спадкоємців, а також усередині його методів. В описі об'єктного типу заголовок методу може задавати параметри об'єктного типу, що описується, навіть якщо опис ще не повний. Розглянемо наступну схему опису типу, що містить компоненти всіх допустимих областей дії: тип <ім'я типу> = Object [(<ім'я типу батька>)] приватний <приватні описи полів та методів> захищений <захищені описи полів та методів> громадськості <загальнодоступні описи полів та методів> end; Поля та методи, описані в розділі Private, можуть бути використані тільки всередині модуля, що містить їх опис та ніде більше. Захищені поля та методи, тобто описані в розділі Protected, є видимими в модулі, де визначається тип, і нащадкам даного типу. Поля та методи з розділу Public не мають обмежень на використання та можуть бути задіяні у будь-якому місці програми, яка має доступ до об'єкта даного типу. Область дії ідентифікатора компонента, описаного частини private описи типу, обмежується модулем (програмою), яка містить опис об'єктного типу. Іншими словами, приватні (private) компоненти-ідентифікатори діють як звичайні загальнодоступні ідентифікатори в рамках модуля, що містить опис об'єктного типу, а поза модулем будь-які приватні компоненти та ідентифікатори невідомі та недоступні. Помістивши в один модуль зв'язані типи об'єктів, можна зробити так, що ці об'єкти можуть звертатися до приватних компонентів один одного, і ці приватні компоненти будуть невідомі іншим модулям. 29. Методи Опис методу всередині об'єктного типу відповідає випереджальному опису методу (forward). Таким чином, десь після опису об'єктного типу, але всередині тієї ж області дії, що і область дії опису об'єктного типу, метод повинен реалізуватися шляхом визначення його опису. Для процедурних і функціональних методів визначальний опис має форму звичайного опису процедури або функції з винятком, що в цьому випадку ідентифікатор процедури або функції розглядається як ідентифікатор методу. У визначальному описі методу завжди є неявний параметр з ідентифікатором Self, що відповідає формальному параметру-змінної, що володіє об'єктним типом. Всередині блоку методу Self представляє екземпляр, компонент методу якого було вказано для активізації методу. Таким чином, будь-які зміни значень полів Self відбиваються на екземплярі. Віртуальні методи За замовчуванням методи статичні, однак вони можуть, за винятком конструкторів, бути віртуальними (за допомогою включення директиви virtual в опис методу). Компілятор дозволяє посилання на виклики статичних методів під час компіляції, тоді як виклики віртуальних методів дозволяються під час виконання. Це іноді називають пізнім зв'язуванням. Перевизначення статичного методу залежить від зміни заголовка методу. На противагу цьому, перевизначення віртуального методу має зберігати порядок, типи та імена параметрів, а також типи результатів функцій, якщо такі є. Більше того, перевизначення знову ж таки має включати директиву virtual. Динамічні методи Borland Pascal підтримує додаткові методи з пізнім зв'язуванням, які називають динамічними методами. Динамічні методи відрізняються від віртуальних лише характером їхньої диспетчеризації на етапі виконання. У всіх інших відносинах динамічні методи вважаються еквівалентними віртуальним. Опис динамічного методу еквівалентно опису віртуального методу, але опис динамічного методу повинен включати індекс динамічного методу, який вказується безпосередньо за ключовим словом virtual. Індекс динамічного методу повинен бути цілою константою в діапазоні від 1 до 656535 і повинен бути унікальним серед індексів інших динамічних методів, що містяться в об'єктному типі або його предках. Наприклад: procedure FileOpen(var Msg: TMessage); virtual 100; Перевизначення динамічного методу має відповідати порядку, типу та імен параметрів і точно відповідати типу результату функції методу, що породжує. Перевизначення також має включати директиву virtual, за якою слідує той же індекс динамічного методу, який був заданий в об'єктному типі предка. 30. Конструктори та деструктори Конструктори та деструктори є спеціалізованими формами методів. Конструктори і деструктори, що використовуються у зв'язку з розширеним синтаксисом стандартних процедур New і Dispose, мають здатність розміщення і видалення динамічних об'єктів. Крім того, конструктори мають можливість виконати необхідну ініціалізацію об'єктів, що містять віртуальні методи. Як і всі інші методи, конструктори та деструктори можуть успадковуватися, а об'єкти можуть містити будь-яку кількість конструкторів та деструкторів. Конструктори використовуються для ініціалізації новостворених об'єктів. Зазвичай ініціалізація ґрунтується на значеннях, що передаються конструктору як параметри. Конструктор може бути віртуальним, оскільки механізм диспетчеризації віртуального методу залежить від конструктора, який першим зробив ініціалізацію об'єкта. Наведемо кілька прикладів конструкторів: constructor Field.Copy(var F: Field); починати Self:= F; end; Головною дією конструктора породженого (дочірнього) типу майже завжди є виклик відповідного конструктора його безпосереднього батька для ініціалізації наслідуваних полів об'єкта. Після виконання цієї процедури конструктор ініціалізує поля об'єкта, що належать лише породженому типу. Деструктори є протилежностями конструкторів і використовуються для очищення об'єктів після їх використання. Зазвичай очищення полягає у видаленні всіх полів покажчиків в об'єкті. Примітка Деструктор може бути віртуальним і часто є таким. Деструктор рідко має параметри. Наведемо кілька прикладів деструкторів: destructor Field.Done; починати FreeMem(Name, Length (Name^) + 1); end; destructor StrField.Done; починати FreeMem (Value, Len); Field.Done; end; Деструктор дочірнього типу, такий як зазначений вище TStrField. Done зазвичай спочатку видаляє введені в породженому типі поля покажчиків, а потім як остання дія викликає відповідний збирач-деструктор безпосереднього батька для видалення успадкованих полів покажчиків об'єкта. 31. Деструктори Borland Pascal надає спеціальний тип методу, що називається збирачем сміття (або деструктором) для очищення та видалення динамічно розміщеного об'єкта. Деструктор об'єднує крок видалення об'єкта з будь-якими іншими діями чи завданнями, необхідними даного типу об'єкта. Для єдиного типу об'єкта можна визначити кілька деструкторів. Деструктори можна успадковувати, і вони можуть бути статичними, або віртуальними. Оскільки різні програми завершення зазвичай потребують різних типів об'єктів, зазвичай рекомендується, щоб деструктори завжди були віртуальними, завдяки чому для кожного типу об'єкта буде виконаний правильний деструктор. Зарезервоване слово destructor не потрібно вказувати для кожного методу очищення, навіть якщо визначення типу об'єкта містить віртуальні методи. Деструктори насправді працюють лише з динамічно розміщеними об'єктами. При очищенні динамічно розміщеного об'єкта деструктор здійснює спеціальні функції: він гарантує, що в області пам'яті, що динамічно розподіляється, завжди буде звільнятися правильне число байтів. Не може бути жодних побоювань щодо використання деструктора стосовно статично розміщених об'єктів; Власне, не передаючи типу об'єкта деструктору, програміст позбавляє об'єкт цього типу повних переваг управління динамічної пам'яттю в Borland Pascal. Деструктори насправді стають самими собою тоді, коли мають очищатися поліморфічні об'єкти і коли має звільнятися пам'ять, яку вони займають. Поліморфічні об'єкти - це об'єкти, які присвоєно батьківському типу завдяки правилам сумісності розширених типів Borland Pascal. Термін "поліморфічний" є підходящим, оскільки код, що обробляє об'єкт, "не знає" точно під час компіляції, який тип об'єкта йому доведеться зрештою обробити. Єдине, що він знає, це те, що цей об'єкт належить ієрархії об'єктів, які є нащадками зазначеного типу об'єкта. Сам собою метод деструктора може бути порожній і виконувати тільки цю функцію: destructor AnObject.Done; починати end; Те, що робиться корисним у цьому деструкторі, не є надбанням його тіла, проте при цьому компілятором генерується код епілогу у відповідь на зарезервоване слово destructor. Це нагадує модуль, який нічого не експортує, але здійснює деякі невидимі дії за рахунок виконання своєї секції ініціалізації перед стартом програми. Усі дії відбуваються "за лаштунками". 32. Віртуальні методи Метод стає віртуальним, якщо його оголошенням у типі об'єкта стоїть нове зарезервоване слово virtual. Якщо оголошується метод у батьківському типі як virtual, всі методи з аналогічними іменами в дочірніх типах також повинні оголошуватися віртуальними щоб уникнути помилки компілятора. Нижче наведено об'єкти з прикладу платіжної відомості, належним чином віртуалізовані: tyрe PEmрloyee = ^TEmployee; TEmployee = об'єкт Name, Title: string[25]; Rate: Real; конструктор Init (AName, ATitle: String; ARate: Real); функція GetPayAmount: Real; virtual; function GetName: String; function GetTitle: String; функція GetRate: Real; рrocedure Show; virtual; end; PHourly = ^THourly; THourly = object(TEmployee); Time: Integer; constructor Init (AName, ATitle: String; ARate: Real; Time: Integer); функція GetPayAmount: Real; virtual; функція GetTime: Integer; end; PSalaried = ^TSalaried; TSalaried = object(TEmployee); функція GetPayAmount: Real; virtual; end; PCommissioned = ^TCommissioned; TCommissioned = object(Salaried); Commission: Real; ПродажAmount: Real; constructor Init (AName, ATitle: String; ARate, ACommission, ASalesAmount: Real); функція GetPayAmount: Real; virtual; end; Конструктор є спеціальним типом процедури, яка виконує деяку роботу для механізму віртуальних методів. Більше того, конструктор повинен викликатись перед викликом будь-якого віртуального методу. Виклик віртуального методу без попереднього виклику конструктора може призвести до блокування системи, а компілятор немає способу перевірити порядок виклику методів. Кожен тип об'єкта, має віртуальні способи, повинен мати конструктор. Конструктор повинен викликатись перед викликом будь-якого іншого віртуального методу. Виклик віртуального методу без попереднього звернення до конструктора може викликати блокування системи, і компілятор зможе перевірити порядок, у якому викликаються методи. 33. Поля даних об'єкта та формальні параметри методу Висновок з того факту, що методи та їх об'єкти поділяють загальну сферу дії, є те, що формальні параметри методу не можуть бути ідентичними будь-якому з полів даних об'єкта. Це не якесь нове обмеження, що накладається об'єктно-орієнтованим програмуванням, а скоріше тими ж найстарішими правилами області дії, які Паскаль мав завжди. Це те саме, що й заборона для формальних параметрів процедури бути ідентичним локальним змінним цієї процедури. Розглянемо приклад, що ілюструє цю помилку для процедури: procedure CrunchIt(Crunchee: MyDataRec, Crunchby, ErrorCode: integer); було A, B: char; ErrorCode: integer; починати . . . end; На рядку, що містить оголошення локальної змінної ErrorCode, виникає помилка. Це тому, що ідентифікатори формального параметра і локальної змінної збігаються. Локальні змінні процедури та її формальні параметри спільно використовують спільну сферу дії і тому не можуть бути ідентичними. Буде отримано повідомлення "Error 4: Duplicate identifier" (Помилка 4; Повторення ідентифікатора), якщо спробувати компілювати щось подібне. Та ж помилка виникає при спробі присвоїти формальному параметру методу імені поля об'єкта, якому цей метод належить. Обставини дещо відрізняються, оскільки приміщення заголовка підпрограми всередину структури даних є натяком на нововведення в Turbo Pascal, але основні принципи дії Паскаля не змінилися. Як і раніше, необхідно дотримуватися певної культури при виборі ідентифікаторів змінних і параметрів. Деякі стилі програмування пропонують способи іменування полів типів, що дозволяють знизити ризик виникнення ідентифікаторів, що дублюються. Наприклад, угорська нотація пропонує імена полів починати з префіксу "m". 34. Інкапсуляція Об'єднання в об'єкті коду та даних називається інкапсуляцією. В принципі, можливо надати достатньо методів, завдяки яким користувач об'єкта ніколи не буде звертатися до полів об'єкта безпосередньо. Деякі інші об'єктно-орієнтовані мови, наприклад Smalltalk, вимагають обов'язкової інкапсуляції, проте Borland Pascal є вибір. Наприклад, об'єкти TEmployee і THourly написані таким чином, що цілком виключена необхідність прямого звернення до їх внутрішніх полів даних: тип TEmployee = об'єкт Name, Title: string[25]; Rate: Real; procedure Init (AName, ATitle: string; ARate: Real); function GetName: String; function GetTitle: String; функція GetRate: Real; функція GetPayAmount: Real; end; THourly = object(TEmployee) Time: Integer; procedure Init(AName, ATitle: string; ARate: Real, Atime: Integer); функція GetPayAmount: Real; end; Тут присутні лише чотири поля даних: Name, Title, Rate та Time. Методи GetName та GetTitle виводять прізвище працюючого та його посаду відповідно. Метод GetPayAmount використовує Rate, а у випадку працюючого THourly та Time для обчислення суми виплат працюючому. Тут уже немає потреби звертатися безпосередньо до цих полів даних. Припустивши існування екземпляра AnHourly типу THourly, ми могли б використовувати набір методів для маніпулювання полями даних AnHourly, наприклад: with AnHourly do починати Init (Александр Петров, Fork lift operator' 12.95, 62); {Виводить на екран прізвище, посаду та суму виплат} Шоу; end; Слід звернути увагу на те, що доступ до полів об'єкта здійснюється не інакше, як тільки за допомогою методів цього об'єкта. 35. Розширювані об'єкти Якщо визначено породжений тип, то методи типу, що породжує, успадковуються, проте за бажання вони можуть перевизначатися. Для перевизначення успадкованого методу просто описується новий метод із тим самим ім'ям, як і успадкований метод, але з іншим тілом і (за потреби) з іншим безліччю параметрів. Визначимо дочірній по відношенню до TEmployee тип, що представляє працівника, якому сплачується годинна ставка, у наступному прикладі: сопзЬ PayPeriods = 26; { періоди виплат } OvertimeThreshold = 80; {на період виплати} OvertimeFactor = 1.5; { Погодинний коефіцієнт } тип THourly = object(TEmployee) Time: Integer; procedure Init(AName, ATitle: string; ARate: Real, Atime: Integer); функція GetPayAmount: Real; end; procedure THourly.Init(AName, ATitle: string; ARate: Real, Atime: Integer); починати TEmployee.Init(AName, ATitle, ARate); Time: = ATime; end; function THourly.GetPayAmount: Real; було Overtime: Integer; починати Overtime:= Time - OvertimeThreshold; if Overtime > 0 then GetPayAmount:= RoundPay(OvertimeThreshold * Rate + Rate OverTime * OvertimeFactor * Rate) ще GetPayAmount:= RoundPay(Time * Rate) end; Викликаючи метод, що перевизначається, необхідно бути впевненим у тому, що породжений тип об'єкта включає функціональність батька. Крім того, будь-яка зміна батьківського методу автоматично впливає на всі породжені. Важливе зауваження: хоча методи можуть бути перевизначені, поля даних не можуть перевизначатися. Після того, як було визначено поле даних в ієрархії об'єкта, ніякий дочірній тип не може визначити поле даних точно з таким же ім'ям. 36. Сумісність типів об'єктів Спадкування дещо змінює правила сумісності типів в Borland Pascal. Нащадок успадковує сумісність типів своїх предків. Ця розширена сумісність типів набуває трьох форм: 1) між реалізаціями об'єктів; 2) між покажчиками реалізації об'єктів; 3) між формальними та фактичними параметрами. Сумісність типів розширюється лише від нащадка до батька. Наприклад, TSalaried є нащадком TEmployee, а TCommissioned - нащадком TSaried. Розглянемо такі описи: було AnEmрloyee: TEmployee; ASalaried: TSalaried; PCommissioned: TCommissioned; TEmployeePtr: ^TEmployee; TSalariedPtr: ^TSalaried; TCommissionedPtr: ^TCommissioned; За даними описами справедливі наступні оператори присвоєння: AnEmрloyee:=ASalaried; ASalaried:= ACommissioned; TCommissionedPtr:= ACommissioned; У загальному випадку правило сумісності типів формулюється так: джерело має бути в змозі повністю заповнити приймач. Породжені типи містять все, що містять їх типи, що породжують завдяки властивості успадкування. Тому породжений тип має розмір не менший за розмір батька. Присвоєння об'єкта, що породжує, породженому могло б залишити деякі поля породженого об'єкта невизначеними, що небезпечно і тому неприпустимо. В операторах привласнення з джерела до приймача копіюватимуться лише поля, які є спільними для обох типів. В операторі присвоєння: AnEmрloyee: = ACommissioned; Тільки поля Name, Title і Rate з ACommissioned будуть скопійовані в AnEmployee, оскільки ці поля є спільними для TCommissioned і TEmployee. Сумісність типів працює також між покажчиками на типи об'єктів і підпорядковується тим самим загальним правилам, як і реалізації об'єктів. Покажчик на нащадка може бути присвоєно покажчику на батька. Якщо дати попередні визначення, то наступні надання покажчиків будуть допустимими: TSalariedPtr:= TCommissionedPtr; TEmployeePtr:= TSalariedPtr; TEmployeePtr:= PCommissionedPtr; Формальний параметр (або значення, або параметр-змінна) даного об'єктного типу може приймати як фактичний параметр об'єкт свого ж типу або об'єкти всіх дочірніх типів. Якщо визначити заголовок процедури наступним чином: procedure CalcFedTax(Victim: TSalaried); то допустимими типами фактичних параметрів можуть бути TSalaried або TCommissioned, але не тип TEmployee. Victim також може бути параметром-змінною. При цьому виконуються самі правила сумісності. Параметр-значення є вказівником на дійсний об'єкт, що посилається як параметр, а параметр-змінна є копією фактичного параметра. Ця копія включає лише ті поля, які входять у тип формального параметра-значення. Це означає, що фактичний параметр перетворюється на тип формального параметра. 37. Про асемблера Колись асемблер був мовою, без знання якої не можна було змусити комп'ютер зробити щось корисне. Поступово ситуація змінювалася. З'являлися зручніші засоби спілкування з комп'ютером. Але на відміну від інших мов асемблер не вмирав, більше того, він не міг зробити цього в принципі. Чому? У пошуках відповіді спробуємо зрозуміти, що таке мова асемблера взагалі. Якщо коротко, то мова асемблера – це символічне уявлення машинної мови. Всі процеси в машині на найнижчому апаратному рівні приводяться в дію тільки командами (інструкціями) машинної мови. Звідси зрозуміло, що, незважаючи на загальну назву, мова асемблера для кожного типу комп'ютера своя. Це стосується і зовнішнього вигляду програм, написаних на асемблері, та ідей, відображенням яких ця мова є. По-справжньому вирішити проблеми, пов'язані з апаратурою (або навіть більше, що залежать від апаратури, як, наприклад, підвищення швидкодії програми), неможливо без знання асемблера. Програміст або будь-який інший користувач можуть використовувати будь-які високорівневі засоби аж до програм побудови віртуальних світів і, можливо, навіть не підозрювати, що насправді комп'ютер виконує не команди мови, якою написана його програма, а їх трансформоване уявлення у формі нудної та похмурої послідовності команд зовсім іншої мови – машинної. А тепер уявімо, що у такого користувача виникла нестандартна проблема. Наприклад, його програма повинна працювати з деяким незвичайним пристроєм або виконувати інші дії, що вимагають знання принципів роботи комп'ютера. Якою б гарною не була мова, якою програміст написав свою програму, без знання асемблера йому не обійтися. І невипадково практично всі компілятори мов високого рівня містять засоби зв'язку своїх модулів з модулями на асемблері або підтримують вихід асемблерний рівень програмування. Комп'ютер складається з кількох фізичних пристроїв, кожен з яких підключено до одного блоку, що називається системним 38. Програмна модель мікропроцесора На сучасному комп'ютерному ринку спостерігається велика різноманітність різних типів комп'ютерів. Тому можна припустити виникнення в споживача питання - як оцінити можливості конкретного типу (чи моделі) комп'ютера та її відмінності від комп'ютерів інших типів (моделей). Розгляди при цьому однієї тільки структурної схеми комп'ютера недостатньо, оскільки вона мало чим відрізняється у різних машин: в усіх комп'ютерів є оперативна пам'ять, процесор, зовнішні устрою. Різними є способи, засоби та ресурси, за допомогою яких комп'ютер функціонує як єдиний механізм. Щоб зібрати докупи всі поняття, що характеризують комп'ютер з погляду його функціональних програмно-керованих властивостей, існує спеціальний термін - архітектура ЕОМ. Вперше поняття архітектура ЕОМ стало згадуватися з появою машин 3-го покоління для їхньої порівняльної оцінки. До вивчення мови Ассемблера будь-якого комп'ютера має сенс приступати тільки після з'ясування того, яка частина комп'ютера залишена видимою та доступною для програмування цією мовою. Це так звана програмна модель комп'ютера, частиною якої є програмна модель мікропроцесора, яка містить 32 регістри в тій чи іншій мірі доступні для використання програмістом. Дані регістри можна розділити на великі групи: 1) 16 користувальницьких регістрів; 2) 16 системних регістрів. У програмах мовою Асемблера регістри використовуються дуже інтенсивно. Більшість регістрів мають певне функціональне призначення. Крім перелічених вище регістрів, фірми-розробники процесорів впроваджують у програмну модель додаткові регістри, призначені оптимізації певних класів обчислень. Так, у сімействі процесорів Pentium Pro (MMX) корпорації Intel було впроваджено розширення MMX від Intel. Воно включає 8 (MM0-MM7) 64-бітних регістрів і дозволяє здійснювати цілочисленні операції над парами декількох нових типів даних: 1) вісім упакованих байт; 2) чотири упаковані слова; 3) два подвійні слова; 4) вчетверне слово; Іншими словами, однією інструкцією MMX розширення програміст може, наприклад, скласти між собою два подвійні слова. Фізично ніяких нових регістрів не було додано. MM0-MM7 це мантиси (молодші 64 біта) стека 80 бітних FPU (floating point unit - співпроцесор) регістрів. Крім того, на даний момент існують такі розширення програмної моделі – 3DNOW! від AMD; SSE, SSE2, SSE3, SSE4. Останні 4 розширення підтримуються як процесорами фірми AMD, і процесорами корпорації Intel. 39. Регістри користувача Як випливає з назви, регістри користувача називаються тому, що програміст може використовувати їх при написанні своїх програм. До цих регістрів відносяться: 1) вісім 32-бітових регістрів, які можуть використовуватися програмістами для зберігання даних та адрес (їх ще називають регістрами загального призначення (РОН)): ▪ eax/ax/ah/al; ▪ ebx/bx/bh/bl; ▪ edx/dx/dh/dl; ▪ ecx/cx/ch/cl; ▪ ebp/bp; ▪ esi/si; ▪ edi/di; ▪ esp/sp. 2) шість регістрів сегментів: ▪ cs; ▪ ds; ▪ ss; ▪ es; ▪ fs; ▪ gs; 3) регістри стану та управління: ▪ регістр прапорів eflags/flags; ▪ регістр покажчика команди eip/ip. На наступному малюнку показані основні регістри мікропроцесора: Реєстри загального призначення
40. Реєстри загального призначення Усі регістри цієї групи дозволяють звертатися до своїх "молодших" частин. Використовувати для самостійної адресації можна лише молодші 16- та 8-бітові частини цих регістрів. Старші 16 біт цих регістрів як самостійні об'єкти недоступні. Перерахуємо регістри, які стосуються групи регістрів загального призначення. Оскільки ці регістри фізично перебувають у мікропроцесорі всередині арифметико-логического устрою (АЛУ), їх ще називають регістрами АЛУ: 1) eax/ax/ah/al (Accumulator register) – акумулятор. Застосовується для зберігання проміжних даних. У деяких командах використання цього регістру є обов'язковим; 2) ebx/bx/bh/bl (Base register) – базовий регістр. Застосовується для зберігання базової адреси деякого об'єкта пам'яті; 3) ecx/cx/ch/cl (Count register) – регістр-лічильник. Застосовується в командах, які роблять деякі дії, що повторюються. Його використання найчастіше неявно та приховано в алгоритмі роботи відповідної команди. Наприклад, команда організації циклу loop, крім передачі управління команді, що знаходиться за деякою адресою, аналізує та зменшує на одиницю значення регістра ecx/cx; 4) edx/dx/dh/dl (Data register) – регістр даних. Так само, як і регістр eax/ax/ah/al, він зберігає проміжні дані. У деяких командах використання обов'язково; для деяких команд це відбувається неявно. Наступні два регістри використовуються для підтримки так званих ланцюжкових операцій, тобто операцій, які проводять послідовну обробку ланцюжків елементів, кожен з яких може мати довжину 32, 16 або 8 біт: 1) esi/si (Source Index register) – індекс джерела. Цей регістр у ланцюжкових операціях містить поточну адресу елемента в ланцюжку-джерелі; 2) edi/di (Destination Index register) – індекс приймача (одержувача). Цей регістр у ланцюжкових операціях містить поточну адресу в ланцюжку-приймачі. У архітектурі мікропроцесора на програмно-апаратному рівні підтримується така структура даних, як стек. Для роботи зі стеком у системі команд мікропроцесора є спеціальні команди, а програмної моделі мікропроцесора для цього існують спеціальні регістри: 1) esp/sp (Stack Pointer register) – регістр покажчика стека. Містить вказівник вершини стека у поточному сегменті стека. 2) ebp/bp (Base Pointer register) - регістр покажчика бази кадру стека. Призначений для організації довільного доступу до даних усередині стека. Використання жорсткого закріплення регістрів для деяких команд дозволяє компактніше кодувати їх машинне подання. Знання цих особливостей дозволить за необхідності хоча б кілька байт заощадити пам'ять, займану кодом програми. 41. Сегментні регістри У програмній моделі мікропроцесора є шість сегментних регістрів: cs, ss, ds, es, gs, fs. Їх існування обумовлено специфікою організації та використання оперативної пам'яті мікропроцесорами Intel. Вона у тому, що мікропроцесор апаратно підтримує структурну організацію програми як трьох частин, званих сегментами. Відповідно така організація пам'яті називається сегментною. Для того щоб вказати на сегменти, до яких програма має доступ у конкретний момент часу, та призначені сегментні регістри. Фактично (з невеликою поправкою) у цих регістрах містяться адреси пам'яті, з яких починаються відповідні сегменти. Логіка обробки машинної команди побудована так, що при вибірці команди, доступі до даних програми або стеку неявно використовуються адреси в цілком певних сегментних регістрах. Мікропроцесор підтримує такі типи сегментів. 1. Сегмент коду. Містить команди програми. Для доступу до цього сегменту служить регістр cs (code segment register) – сегментний регістр коду. Він містить адресу сегмента з машинними командами, якого має доступ мікропроцесор (тобто. ці команди завантажуються в конвеєр мікропроцесора). 2. Сегмент даних. Містить дані, що обробляються програмою. Для доступу до цього сегменту служить регістр ds (data segment register) – сегментний регістр даних, який зберігає адресу сегмента даних поточної програми. 3. Сегмент стека. Цей сегмент є область пам'яті, звану стеком. Роботу зі стеком мікропроцесор організує за таким принципом: останній записаний у цю область елемент вибирається першим. Для доступу до цього сегменту служить регістр ss (stack segment register) – сегментний регістр стека, що містить адресу сегмента стека. 4. Додатковий сегмент даних. Не явно алгоритми виконання більшості машинних команд припускають, що дані, які вони обробляють, розташовані в сегменті даних, адреса якого знаходиться в сегментному регістрі ds. Якщо програмі недостатньо одного сегмента даних, вона має можливість використовувати ще три додаткових сегмента даних. Але на відміну від основного сегмента даних, адреса якого міститься в сегментному регістрі ds, при використанні додаткових сегментів даних їх адреси потрібно явно вказувати за допомогою спеціальних префіксів перевизначення сегментів у команді. Адреси додаткових сегментів даних повинні міститися в регістрах es, gs, fs (extension data segment registers). 42. Регістри стану та управління У мікропроцесор включено кілька регістрів, які постійно містять інформацію про стан як самого мікропроцесора, так і програми, команди якої зараз завантажені на конвеєр. До цих регістрів відносяться: 1) регістр прапорів eflags/flags; 2) регістр покажчика команди eip/ip. Використовуючи ці регістри, можна отримувати інформацію про результати виконання команд і проводити стан самого мікропроцесора. Розглянемо докладніше призначення та вміст цих регістрів 1. eflags/flags (flag register) – регістр прапорів. Розрядність eflags/flags – 32/16 біт. Окремі біти даного регістру мають певне функціональне призначення та називаються прапорами. Молодша частина цього регістру повністю подібна до регістру flags для i8086. Виходячи з особливостей використання прапора регістру eflags/flags можна поділити на три групи: 1) вісім прапорів стану. Ці прапори можуть змінюватись після виконання машинних команд. Прапори стану регістру eflags відбивають особливості результату виконання арифметичних чи логічних операцій. Це дає можливість аналізувати стан обчислювального процесу та реагувати на нього за допомогою команд умовних переходів та викликів підпрограм. 2) один прапор управління. Позначається df (Directory Flag). Він знаходиться в 10-му біті регістру eflags і використовується ланцюжковими командами. Значення прапора df визначає напрямок поелементної обробки в цих операціях: від початку рядка до кінця (df = 0) або навпаки, від кінця рядка до її початку (df = 1). Для роботи із прапором df існують спеціальні команди: cld (зняти прапор df) та std (установити прапор df). Застосування цих команд дозволяє привести прапор df у відповідність до алгоритму та забезпечити автоматичне збільшення або зменшення лічильників при виконанні операцій з рядками. 3) п'ять системних прапорів. Керують введенням-виводом, перериваннями, що маскуються, налагодженням, перемиканням між завданнями і віртуальним режимом 8086. Прикладним програмам не рекомендується модифікувати без необхідності ці прапори, так як у більшості випадків це призведе до переривання роботи програми. 2. eip/ip (Instraction Pointer register) - регістр-покажчик команд. Регістр eip/ip має розрядність 32/16 біт і містить зміщення наступної команди, що підлягає виконанню щодо вмісту сегментного регістру cs в поточному сегменті команд. Цей регістр безпосередньо недоступний програмісту, але завантаження та зміна його значення виконуються різними командами управління, до яких належать команди умовних та безумовних переходів, виклику процедур та повернення з процедур. Виникнення переривань також призводить до модифікації регістру eip/ip. 43. Системні регістри мікропроцесора Сама назва цих регістрів свідчить, що вони виконують специфічні функції у системі. Використання системних регістрів жорстко регламентовано. Саме вони забезпечують роботу захищеного режиму. Їх також можна розглядати як частину архітектури мікропроцесора, яка навмисно залишена видимою для того, щоб кваліфікований системний програміст міг виконати найнижчі рівні. Системні регістри можна поділити на три групи: 1) чотири регістри управління; До групи регістрів управління входять 4 регістри: ▪ cr0; ▪ cr1; ▪ cr2; ▪ cr3; 2) чотири регістри системних адрес (які також називаються регістрами управління пам'яттю); До регістрів системних адрес відносяться такі регістри: ▪ регістр таблиці глобальних дескрипторів gdtr; ▪ регістр таблиці локальних дескрипторів Idtr; ▪ регістр таблиці дескрипторів переривань idtr; ▪ 16-бітовий регістр задачі tr; 3) вісім регістрів налагодження. До них належать: ▪ dr0; ▪ dr1; ▪ dr2; ▪ dr3; ▪ dr4; ▪ dr5; ▪ dr6; ▪ dr7. Знання системних регістрів не є необхідним для написання програм на асемблері, у зв'язку з тим, що вони застосовуються, головним чином, для здійснення низькорівневих операцій. Однак в даний час тенденції в розробці програмного забезпечення (особливо у світлі значно збільшених можливостей з оптимізації сучасних компіляторів високорівневих мов, що часто формують код, що перевершує за ефективністю код, створений людиною) звужують область застосування Асемблера до вирішення найнижчого рівня завдань, де знання вищезазначених регістр виявитися дуже корисним. 44. Реєстри управління До групи регістрів управління входять чотири регістри: cr0, cr1, cr2, cr3. Ці регістри призначені для управління системою. Регістри керування доступні лише програмам із рівнем привілеїв 0. Хоча мікропроцесор має чотири регістри управління, доступними є лише три з них - виключається cr1, функції якого поки що не визначені (він зарезервований для майбутнього використання). Регістр cr0 містить системні прапори, що керують режимами роботи мікропроцесора і відображають його стан глобально, незалежно від конкретних завдань. Призначення системних прапорів: 1) pe (Protect Enable), біт 0 – дозвіл захищеного режиму роботи. Стан цього прапора показує, у якому з двох режимів - реальному (pe = 0) чи захищеному (pe = 1) - працює мікропроцесор у час; 2) mp (Math Present), біт 1 – наявність співпроцесора. Завжди 1; 3) ts (Task Switched), біт 3 - перемикання завдань. Процесор автоматично встановлює цей біт при перемиканні виконання іншого завдання; 4) am (Alignment Mask), біт 18 - маска вирівнювання. Цей біт дозволяє (am = 1) чи забороняє (am = 0) контроль вирівнювання; 5) cd (Cache Disable), біт 30 - заборона кеш-па-м'яті. За допомогою цього біта можна заборонити (cd=1) або дозволити (cd=0) використання внутрішньої кеш-пам'яті (кеш-пам'яті першого рівня); 6) pg (PaGing), біт 31 - роздільна здатність (pg = 1) або заборона (pg = 0) сторінкового перетворення. Прапор використовується при сторінки моделі пам'яті. Регістр cr2 використовується при сторінці оперативної пам'яті для реєстрації ситуації, коли поточна команда звернулася за адресою, що міститься в сторінці пам'яті, відсутньої в даний момент часу в пам'яті. У такій ситуації в мікропроцесорі виникає виняткова ситуація з номером 14, і лінійна 32-бітна адреса команди, що викликала цей виняток, записується в регістр cr2. Маючи цю інформацію, обробник виключення 14 визначає потрібну сторінку, здійснює її підкачування на згадку і відновлює нормальну роботу програми; Реєстр cr3 також використовується при сторінці пам'яті. Це так званий регістр каталогу сторінок першого рівня. Він містить 20-бітну фізичну базову адресу каталогу сторінок поточного завдання. Цей каталог містить 1024 32-бітових дескрипторів, кожен з яких містить адресу таблиці сторінок другого рівня. У свою чергу, кожна з таблиць сторінок другого рівня містить 1024 32-бітових дескрипторів, що адресують сторінкові кадри в пам'яті. Розмір сторінкового кадру – 4 Кбайти. 45. Реєстри системних адрес Ці регістри ще називають регістрами управління пам'яттю. Вони призначені для захисту програм та даних у мультизадачному режимі роботи мікропроцесора. При роботі в захищеному режимі мікропроцесора адресний простір поділяється на: 1) глобальне – загальне для всіх завдань; 2) локальне – окреме для кожного завдання. Цим поділом і пояснюється присутність в архітектурі мікропроцесора наступних системних регістрів: 1) регістра таблиці глобальних дескрипторів gdtr (Global Descriptor Table Register), що має розмір 48 біт і містить 32-бітову (біти 16-47) базову адресу глобальної дескрипторної таблиці GDT і 16-бітове (біти 0-15) значення межі, що представляє собою розмір у байтах таблиці GDT; 2) регістра таблиці локальних дескрипторів ldtr (Local Descriptor Table Register), що має розмір 16 біт і містить так званий селектор дескриптора локальної дескрипторної таблиці LDT. Цей селектор є покажчиком у таблиці GDT, який описує сегмент, що містить локальну дескрипторну таблицю LDT; 3) регістра таблиці дескрипторів переривань idtr (Interrupt Descriptor Table Register), що має розмір 48 біт і містить 32-бітовий (біти 16-47) базову адресу дескрипторної таблиці переривань IDT і 16-бітове (біти 0-15) значення межі, розмір у байтах таблиці IDT; 4) 16-бітового регістра задачі tr (Task Register), який подібно до регістра ldtr, містить селектор, тобто покажчик на дескриптор в таблиці GDT. Цей дескриптор визначає поточний сегмент стану завдання (TSS - Task Segment Status). Цей сегмент створюється для кожного завдання у системі, має жорстко регламентовану структуру та містить контекст (поточний стан) завдання. Основне призначення сегментів TSS - зберігати поточний стан завдання у момент перемикання інше завдання. 46. Реєстри налагодження Це дуже цікава група регістрів, призначених для апаратного налагодження. Засоби апаратного налагодження вперше з'явилися в мікропроцесорі i486. Апаратно мікропроцесор містить вісім регістрів налагодження, але реально з них використовуються лише шість. Регістри dr0, dr1, dr2, dr3 мають розрядність 32 біта і призначені для завдання лінійних адрес чотирьох точок переривання. Використовуваний при цьому механізм наступний: будь-який формується адресою, що формується поточною програмою, порівнюється з адресами в регістрах dr0 ... dr3, і при збігу генерується виключення налагодження з номером 1. Регістр dr6 називається регістром стану налагодження. Біти цього регістру встановлюються відповідно до причин, що викликали виникнення останнього виключення з номером 1. Перерахуємо ці біти та їх призначення: 1) b0 - якщо цей біт встановлено в 1, то останній виняток (переривання) виникло в результаті досягнення контрольної точки, визначеної в регістрі dr0; 2) b1 - аналогічно b0, але для контрольної точки в регістрі dr1; 3) b2 - аналогічно b0, але для контрольної точки в регістрі dr2; 4) b3 - аналогічно b0, але для контрольної точки в регістрі dr3; 5) bd (біт 13) – служить для захисту регістрів налагодження; 6) bs (біт 14) - встановлюється в 1, якщо виняток 1 був викликаний станом прапора tf = 1 в регістрі eflags; 7) bt (біт 15) встановлюється в 1, якщо виняток 1 було викликано перемиканням на завдання з встановленим бітом пастки TSS t = 1. Всі інші біти в цьому регістрі заповнюються нулями. Обробник виключення 1 за вмістом dr6 повинен визначити причину, за якою стався виняток, та виконати необхідні дії. Регістр dr7 називається регістром управління налагодженням. У ньому для кожного з чотирьох регістрів контрольних точок налагодження є поля, що дозволяють уточнити такі умови, за яких слід згенерувати переривання: 1) місце реєстрації контрольної точки - тільки в поточному завданні або будь-якому завданні. Ці біти займають молодші 8 біт регістра dr7 (по 2 біти на кожну контрольну точку (фактично точку переривання), що задається регістрами dr0, drl, dr2, dr3 відповідно). Перший біт з кожної пари - це так званий локальний дозвіл; його установка свідчить, що точка переривання діє, якщо вона перебуває у межах адресного простору поточного завдання. Другий біт у кожній парі визначає глобальне дозвіл, яке свідчить, що дана контрольна точка діє межах адресних просторів всіх завдань, що у системі; 2) тип доступу, за яким ініціюється переривання: тільки під час вибірки команди, під час запису чи під час запису / читання даних. Біти, що визначають подібну природу виникнення переривання, локалізуються у старшій частині цього регістру. Більшість із системних регістрів програмно доступна. 47. Структура програми на асемблері Програма на асемблері є сукупність блоків пам'яті, званих сегментами пам'яті. Програма може складатися з одного або кількох блоків-сегментів. Кожен сегмент містить сукупність речень мови, кожна з яких займає окремий рядок коду програми. Пропозиції асемблера бувають чотирьох типів. Команди або інструкції, що є символічними аналогами машинних команд. У процесі трансляції інструкції асемблера перетворюються на відповідні команди системи команд мікропроцесора. Одна команда асемблера, як правило, відповідає одній команді мікропроцесора, що, взагалі кажучи, є характерним для низькорівневих мов. Наведемо приклад інструкції, яка здійснює збільшення двійкового числа, що зберігається в реєстрі eax, на одиницю: inc eax ▪ макрокоманди - оформлюються певним чином пропозиції тексту програми, які замінюються під час трансляції іншими пропозиціями. Прикладом макрокоманди може бути наступний макрос кінця програми: exit macro mov ax,4c00h int 21h endm ▪ директиви, які є вказівкою транслятора асемблера на виконання деяких дій. У директив немає аналогів у машинному поданні; Як приклад наведемо директиву TITLE, яка задає заголовок файлу лістингу: %TITLE "Лістинг 1" ▪ рядки коментарів, що містять будь-які символи, у тому числі літери російського алфавіту. Коментарі ігноруються транслятором. Приклад: ; цей рядок є коментарем 48. Синтаксис асемблера Пропозиції, що становлять програму, можуть бути синтаксичною конструкцією, що відповідає команді, макрокоманді, директиві або коментарю. Для того, щоб транслятор асемблера міг розпізнати їх, вони повинні формуватися за певними синтаксичними правилами. Для цього найкраще використовувати формальний опис синтаксису мови на кшталт правил граматики. Найбільш поширені способи подібного опису мови програмування – синтаксичні діаграми та розширені форми Бекуса-Наура. При роботі з синтаксичними діаграмами звертайте увагу на напрямок обходу, що вказується стрілками. Синтаксичні діаграми відбивають логіку роботи транслятора під час аналізу вхідних пропозицій програми. Допустимі символи: 1) всі латинські літери: A – Z, a – z; 2) цифри від 0 до 9; 3) знаки? @, $, &; 4) роздільники. Лексемами є такі. 1. Ідентифікатори - послідовності допустимих символів, що використовуються для позначення кодів операцій, імен змінних та назв міток. Ідентифікатор не може починатись цифрою. 2. Ланцюжки символів – послідовності символів, укладені в одинарні чи подвійні лапки. 3. Цілі числа. Можливі типи операторів асемблера. 1. Арифметичні оператори. До них відносяться: 1) унарні "+" та "-"; 2) бінарні "+" та "-"; 3) множення "*"; 4) цілісного розподілу "/"; 5) отримання залишку від розподілу "mod". 2. Оператори зсуву виконують зсув виразу на вказану кількість розрядів. 3. Оператори порівняння (повертають значення "істина" або "брехня") призначені для формування логічних виразів. 4. Логічні оператори виконують над виразами побітові операції. 5. Індексний оператор []. 6. Оператор перевизначення типу ptr застосовується для перевизначення або уточнення типу мітки або змінної, що визначаються виразом. 7. Оператор перевизначення сегмента ":" (двокрапка) змушує обчислювати фізичну адресу щодо конкретно задається сегментної складової. 8. Оператор іменування типу структури "." (точка) також змушує транслятор робити певні обчислення, якщо він зустрічається у виразі. 9. Оператор отримання сегментної складової адреси виразу seg повертає фізичну адресу сегмента для вираження, якою можуть виступати мітка, змінна, ім'я сегмента, ім'я групи або деяке символічне ім'я. 10. Оператор отримання зміщення виразу offset дозволяє отримати значення зміщення виразу в байтах щодо початку сегмента, в якому вираз визначено. 49. Директиви сегментації p align="justify"> Сегментація є частиною більш загального механізму, пов'язаного з концепцією модульного програмування. Вона передбачає уніфікацію оформлення об'єктних модулів, створюваних компілятором, зокрема з різних мов програмування. Це дозволяє об'єднувати програми, написані різними мовами. Саме для реалізації різних варіантів такого об'єднання призначені операнди в директиві SEGMENT. Розглянемо їх докладніше. 1. Атрибут вирівнювання сегмента (тип вирівнювання) повідомляє компонувальнику про те, що потрібно забезпечити розміщення початку сегмента на заданому кордоні: 1) BYTE – вирівнювання не виконується; 2) WORD - сегмент починається за адресою, кратною двом, тобто останній (молодший) значний біт фізичної адреси дорівнює 0 (вирівнювання на межу слова); 3) DWORD - сегмент починається за адресою, кратною чотирьом; 4) PARA - сегмент починається за адресою, кратною 16; 5) PAGE - сегмент починається за адресою, кратною 256; 6) MEMPAGE – сегмент починається за адресою, кратною 4 Кбайт. 2. Атрибут комбінування сегментів (комбінаторний тип) повідомляє компонувальнику, як потрібно комбінувати сегменти різних модулів, що мають одне й те саме ім'я: 1) PRIVATE - сегмент не об'єднуватиметься з іншими сегментами з тим же ім'ям поза цим модулем; 2) PUBLIC – змушує компонувальник з'єднати всі сегменти з однаковими іменами; 3) COMMON - має у своєму розпорядженні всі сегменти з одним і тим же ім'ям за однією адресою; 4) AT xxxx - має у своєму розпорядженні сегмент за абсолютною адресою параграфа; 5) STACK – визначення сегмента стека. 3. Атрибут класу сегмента (тип класу) - це укладений у лапки рядок, що допомагає компонувальнику визначити відповідний порядок проходження сегментів при збиранні програми із сегментів кількох модулів. 4. Атрибут розміру сегмента: 1) USE16 - це означає, що сегмент допускає 16-розрядну адресацію; 2) USE32 – сегмент буде 32-розрядним. Необхідно якось компенсувати неможливість безпосередньо управляти розміщенням та комбінуванням сегментів. Для цього почали використовувати директиву вказівки моделі пам'яті MODEL. Ця директива пов'язує сегменти, які у разі використання спрощених директив сегментації мають зумовлені імена, із сегментними регістрам (хоча явно ініціалізувати ds все одно доведеться). Обов'язковим параметром директиви є модель пам'яті. Цей параметр визначає модель сегментації пам'яті програмного модуля. Передбачається, що програмний модуль може мати лише певні типи сегментів, які визначаються згаданими раніше спрощеними директивами опису сегментів. 50. Структура машинної команди Машинна команда є закодована за певними правилами вказівка мікропроцесору на виконання деякої операції або дії. Кожна команда містить елементи, що визначають: 1) що робити? 2) об'єкти, з яких треба щось робити (ці елементи називаються операндами); 3) як робити? Максимальна довжина машинної команди – 15 байт. 1. Префікси. Необов'язкові елементи машинної команди, кожен з яких складається з 1 байта або може бути відсутнім. У пам'яті префікси передують команді. Призначення префіксів - модифікувати операцію, яку виконує команда. Прикладна програма може використовувати такі типи префіксів: 1) префікс заміни сегмента; 2) префікс розрядності адреси уточнює розрядність адреси (32- або 16-розрядна); 3) префікс розрядності операнда аналогічний префіксу розрядності адреси, але вказує на розрядність операндів (32- або 16-розрядні), з якими працює команда; 4) префікс повторення використовують із ланцюжковими командами. 2. Код операції. Обов'язковий елемент, що описує операцію, яку виконує команда. 3. Байт режиму адресації modr/m. Значення цього байта визначає форму адреси операндів, що використовується. Операнди можуть бути в пам'яті в одному або двох регістрах. Якщо операнд перебуває у пам'яті, то байт modr/m визначає компоненти (зсув, базовий і індексний регістри), використовуються для обчислення його ефективної адреси. Байт modr/m складається з трьох полів: 1) поле mod визначає кількість байт, що займаються в команді адресою операнда; 2) поле reg/коп визначає або регістр, що у команді дома першого операнда, або можливе розширення коду операції; 3) поле r/m використовується спільно з полем mod і визначає або регістр, що знаходиться в команді на місці першого операнда (якщо mod = 11), або використовувані для обчислення ефективної адреси (спільно з полем усунення в команді) базові та індексні регістри. 4. Байт масштаб – індекс – база (байт sib). Використовується для розширення можливостей адресації операндів. Байт sib складається із трьох полів: 1) поля масштабу ss. У цьому полі розміщується масштабний множник для індексного компонента index, що займає 3 біти байта sib; 2) поля index. Використовується для зберігання номера індексного регістру, який застосовується для обчислення ефективної адреси операнда; 3) поля base. Використовується для зберігання номера базового регістру, який також застосовується для обчислення ефективної адреси операнда. 5. Поле усунення у команді. 8-, 16- або 32-розрядне ціле число зі знаком, що є, повністю або частково (з урахуванням вищенаведених міркувань), значення ефективної адреси операнда. 6. Поле безпосереднього операнда. Необов'язкове поле, що є 8-, 16- або 32-розрядний безпосередній операнд. Наявність цього поля, звісно, відбивається на значенні байта modr/m. 51. Способи завдання операндів команди Операнд задається неявно на мікропрограмному рівні У цьому випадку команда не містить операндів. Алгоритм виконання команди використовує деякі об'єкти за замовчуванням (реєстри, прапори в eflags тощо). Операнд задається у самій команді (безпосередній операнд) Операнд перебуває у коді команди, т. е. є частиною. Для зберігання такого операнда у команді виділяється поле завдовжки до 32 біт. Безпосередній операнд може лише другим операндом (джерелом). Операнд-одержувач може бути або у пам'яті, або у регістрі. Операнд перебуває у одному з регістрів Реєстрові операнди вказуються іменами регістрів. Як регістри можуть використовуватися: 1) 32-розрядні регістри EAX, EBX, ECX, EDX, ESI, EDI, ESP, EBP; 2) 16-розрядні регістри AX, BX, CX, DX, SI, DI, SP, ВР; 3) 8-розрядні регістри AH, AL, BH, BL, CH, CL, DH, DL; 4) сегментні регістри CS, DS, SS, ES, FS, GS. Наприклад, команда add ax, bx складає вміст регістрів ax і bx і записує результат bx. Команда dec si зменшує вміст si на 1. Операнд знаходиться в пам'яті Це найбільш складний і в той же час найбільш гнучкий спосіб завдання операндів. Він дозволяє реалізувати такі два основні види адресації: пряму та непряму. У свою чергу непряма адресація має такі різновиди: 1) непряму базову адресацію; інша її назва – регістрова непряма адресація; 2) непряму базову адресацію зі зміщенням; 3) непряму індексну адресацію зі зміщенням; 4) непряму базову індексну адресацію; 5) непряму базову індексну адресацію зі зміщенням. Операндом є порт введення/виводу Крім адресного простору оперативної пам'яті, мікропроцесор підтримує адресний простір вводу-виводу, який використовується для доступу до пристроїв введення-виводу. Обсяг адресного простору введення-виведення становить 64 Кбайт. Для будь-якого пристрою комп'ютера у цьому просторі виділяються адреси. Конкретне значення адреси не більше цього простору називається портом ввода-вывода. Фізично порту введення-виведення відповідає апаратний регістр (не плутати з регістром мікропроцесора), доступ до якого здійснюється за допомогою спеціальних команд асемблера in і out. Операнд знаходиться у стеку Команди можуть зовсім не мати операнда, мати один або два операнда. Більшість команд вимагають двох операндів, одна з яких є операндом-джерелом, а друга - операндом призначення. Важливо те, що один операнд може розташовуватися в регістрі або пам'яті, а другий операнд обов'язково повинен знаходитися в регістрі або безпосередньо в команді. Безпосередній операнд може бути лише операндом-джерелом. У двооперандній машинній команді можливі такі поєднання операндів: 1) регістр – регістр; 2) регістр – пам'ять; 3) пам'ять – регістр; 4) безпосередній операнд – регістр; 5) безпосередній операнд – пам'ять. 52. Способи адресації Пряма адресація Це найпростіший вид адресації операнда у пам'яті, оскільки ефективна адреса міститься у самій команді та її формування немає ніяких додаткових джерел чи регістрів. Ефективна адреса береться безпосередньо з поля усунення машинної команди, яке може мати розмір 8, 16, 32 біт. Це значення однозначно визначає байт, слово чи подвійне слово, розташовані в сегменті даних. Пряма адресація може бути двох типів. Відносна пряма адресація Використовується для команд умовних переходів для вказівки відносної адреси переходу. Відносність такого переходу полягає в тому, що в полі зміщення машинної команди міститься 8-, 16- або 32-бітове значення, яке в результаті роботи команди складатиметься з вмістом регістру покажчика команд ip/eip. Через війну такого додавання виходить адресу, яким і здійснюється перехід. Абсолютна пряма адресація У цьому випадку ефективна адреса є частиною машинної команди, але формується ця адреса тільки значення поля зміщення в команді. Для формування фізичної адреси операнда в пам'яті мікропроцесор складає поле зі зрушеним на 4 біта значенням сегментного регістру. У команді асемблера можна використовувати кілька форм такої адресації. Непряма базова (реєстрова) адресація При такій адресації ефективна адреса операнда може знаходитись у будь-якому з регістрів загального призначення, крім sp/esp та bp/ebp (це специфічні регістри для роботи з сегментом стека). Синтаксично у команді цей режим адресації виражається укладанням імені регістру в квадратні дужки []. Непряма базова (реєстрова) адресація зі зміщенням Цей вид адресації є доповненням попереднього та призначений для доступу до даних з відомим зміщенням щодо деякої базової адреси. Цей вид адресації зручно використовуватиме доступу до елементів структур даних, коли зміщення елементів відомо заздалегідь, на стадії розробки програми, а базова (початкова) адреса структури має обчислюватися динамічно, на стадії виконання програми. Непряма індексна адресація зі зміщенням Цей вид адресації дуже схожий на непряму базову адресацію зі зміщенням. Тут також для формування ефективної адреси використовується один із регістрів загального призначення. Але індексна адресація має одну цікаву особливість, яка дуже зручна для роботи з масивами. Вона пов'язана з можливістю так званого масштабування вмісту індексного регістру. Непряма базова індексна адресація При цьому виді адресації ефективна адреса формується як сума вмісту двох регістрів загального призначення: базового та індексного. Як ці регістри можуть застосовуватися будь-які регістри загального призначення, при цьому часто використовується масштабування вмісту індексного регістру. Непряма базова індексна адресація зі зміщенням Цей вид адресації є доповненням непрямої індексної адресації. Ефективна адреса формується як сума трьох складових: вмісту базового регістру, вмісту індексного регістру та значення поля усунення в команді. 53. Команди пересилання даних Команди пересилання даних загального призначення До цієї групи належать такі команди: 1) mov – це основна команда пересилання даних; 2) xchg - застосовують для двонаправленого пересилання даних. Команди введення-виведення в порт Важливо керувати пристроями безпосередньо через порти нескладно: 1) in акумулятор, номер порту - введення в акумулятор із порту з номером номер порту; 2) out порт, акумулятор - виведення вмісту акумулятора в порт із номером номер порту. Команди перетворення даних До цієї групи можна віднести безліч команд мікропроцесора, але більшість із них має ті чи інші особливості, які вимагають віднести їх до інших функціональних груп. Команди роботи зі стеком Ця група є набір спеціалізованих команд, орієнтованих на організацію гнучкої та ефективної роботи зі стеком. Стек - це область пам'яті, що спеціально виділяється для тимчасового зберігання даних програми. Для роботи зі стеком призначені три регістри: 1) ss – сегментний регістр стека; 2) sp/esp - регістр покажчика стека; 3) bp/ebp - регістр покажчика бази кадру стека. Для організації роботи зі стеком існують спеціальні команди запису та читання. 1. push джерело - запис значення джерела на вершину стека. 2. pop призначення - запис значення з вершини стека за місцем, вказаним операндом призначення. Значення у своїй " знімається " з вершини стека. 3. pusha – команда групового запису в стек. 4. pushaw – майже синонім команди pusha. Атрибут розрядності може набувати значення use16 або use32. Р 5. pushad - виконується аналогічно до команди pusha, але є деякі особливості. Наступні три команди виконують дії, обернені до вищеописаних команд: 1) popa; 2) popaw; 3) popad. Група команд, описана нижче, дозволяє зберегти в стеку регістр прапорів та записати слово чи подвійне слово у стеку. 1. pushf – зберігає регістр прапорів у стеку. 2. pushfw - збереження у стеку регістру прапорів розміром слово. Завжди працює як pushf з атрибутом use16. 3. pushfd - збереження в стеку регістру прапорів flags чи eflags залежно від атрибуту розрядності сегмента (тобто, що й pushf). Аналогічно, наступні три команди виконують дії, обернені до розглянутих вище операцій: 1) popf; 2) popfw; 3) popfd. 54. Арифметичні команди Такі команди працюють із двома типами: 1) цілими двійковими числами, тобто із числами, закодованими в двійковій системі числення. Десяткові числа - спеціальний вид подання числової інформації, основою якого покладено принцип кодування кожної десяткової цифри числа групою з чотирьох біт. Мікропроцесор виконує складання операндів за правилами складання двійкових чисел. У системі команд мікропроцесора є три команди двійкового додавання: 1) inc операнд – збільшення значення операнда; 2) add операнд1, операнд2 - додавання; 3) adc операнд1,операнд2 - додавання з урахуванням прапора перенесення cf. Віднімання двійкових чисел без знака Якщо зменшуване більше віднімається, то різниця позитивна. Якщо зменшуване менше віднімається, виникає проблема: результат менше 0, а це вже число зі знаком. Після віднімання чисел без знака слід аналізувати стан прапора CF. Якщо він встановлений в 1, то відбулася позика зі старшого розряду і результат вийшов у додатковому коді. Віднімання двійкових чисел зі знаком Але для віднімання способом складання чисел зі знаком у додатковому коді необхідно представляти обидва операнди - і зменшуване, і віднімається. Результат теж потрібно розглядати як значення додаткового коду. Але тут виникають складнощі. Насамперед вони пов'язані з тим, що старший біт операнда сприймається як знаковий. Вміст прапора переповнення of. Його установка в 1 говорить про те, що результат вийшов за діапазон уявлення знакових чисел (тобто змінився старший біт) для операнда даного розміру, і програміст повинен передбачити дії коригування результату. Принцип віднімання чисел з діапазоном уявлення, що перевищує стандартні розрядні сітки операндів, той же, що і при додаванні, тобто використовується прапор переносу cf. Потрібно тільки уявляти процес віднімання в стовпчик і правильно комбінувати команди мікропроцесора з командою sbb. Для множення чисел без знака призначено команду mul сомножитель_1 Для множення чисел зі знаком призначена команда [imul операнд_1, операнд_2, операнд_3] Для поділу чисел без знака призначена команда div дільник Для поділу чисел зі знаком призначена команда idiv дільник 55. Логічні команди Відповідно до теорії, над висловлюваннями (над бітами) можуть виконуватися такі логічні операції. 1. Заперечення (логічне НЕ) - логічна операція над одним операндом, результатом якої є величина, обернена до значення вихідного операнда. 2. Логічне складання (логічне включає АБО) - логічна операція над двома операндами, результатом якої є "істина" (1), якщо один або обидва операнда мають значення "істина" (1), і "брехня" (0), якщо обидва операнда мають значення "брехня" (0). 3. Логічне множення (логічне І) - логічна операція над двома операндами, результатом якої є "істина" (1) тільки в тому випадку, якщо обидва операнди мають значення "істина" (1). У решті випадків значення операції "брехня" (0). 4. Логічне виключне додавання (логічне виключне АБО) - логічна операція над двома операндами, результатом якої є "істина" (1), якщо тільки один з двох операндів має значення "істина" (1), і брехня (0), якщо обидва операнда мають значення "брехня" (0) або "істина" (1). 4. Логічне виключне додавання (логічне виключне АБО) - логічна операція над двома операндами, результатом якої є "істина" (1), якщо тільки один з двох операндів має значення "істина" (1), і брехня (0), якщо обидва операнда мають значення "брехня" (0) або "істина" (1). Наступний набір команд, що підтримують роботу з логічними даними: 1) and операнд_1, операнд_2 – операція логічного множення; 2) or операнд_1, операнд_2 - операція логічного складання; 3) xor операнд_1, операнд_2 - операція логічного виключає додавання; 4) test операнд_1, операнд_2 - операція "перевірити" (спосібом логічного множення) 5) not операнд – операція логічного заперечення. а) для встановлення певних розрядів (біт) 1 застосовується команда or операнд_1, операнд_2; б) для скидання певних розрядів (біт) 0 застосовується команда and операнд_1, операнд_2; в) команда xor операнд_1, операнд_2 застосовується: ▪ для з'ясування того, які біти в операнд_1 та операнд_2 різняться; ▪ для інвертування стану заданих біт в операнд_1. Для перевірки стану заданих біт застосовується команда test операнд_1, операнд_2 (перевірити операнд_1). Результатом команди є встановлення значення прапора нуля zf: 1) якщо zf = 0, то в результаті логічного множення вийшов нульовий результат, тобто один одиничний біт маски, який не збігся з відповідним одиничним бітом операнд1; 2) якщо zf = 1, то в результаті логічного множення вийшов ненульовий результат, тобто хоча один одиничний біт маски збігся з відповідним одиничним бітом операнд1. Усі команди зсуву переміщують біти в полі операнда ліворуч або праворуч залежно від коду операції. Усі команди зсуву мають однакову структуру – коп операнд, лічильник зрушень. 56. Команди передачі управління Те, яка команда програми має виконуватися наступною, мікропроцесор дізнається за вмістом кількох регістрів cs:(e)ip: 1) cs - сегментний регістр коду, в якому знаходиться фізична адреса поточного сегмента коду; 2) eip/ip - регістр покажчика команди, у ньому перебуває значення усунення у пам'яті наступної команди, підлягає виконанню. Безумовні переходи Що має бути модифіковано, залежить: 1) від типу операнда у команді безумовного переходу (ближній чи далекий); 2) від вказівки перед адресою переходу модифікатора; при цьому сама адреса переходу може бути або безпосередньо в команді (прямий перехід), або в регістрі пам'яті (непрямий перехід). Значення модифікатора: 1) near ptr – прямий перехід на мітку; 2) far ptr – прямий перехід на мітку в іншому сегменті коду; 3) word ptr – непрямий перехід на мітку; 4) dword ptr – непрямий перехід на мітку в іншому сегменті коду. Команда безумовного переходу jmp jmp [модифікатор] адреса_переходу Процедура чи підпрограма - це основна функціональна одиниця декомпозиції деякого завдання. Процедура є групою команд. Умовні переходи Мікропроцесор має 18 команд умовного переходу. Ці команди дозволяють перевірити: 1) відношення між операндами зі знаком ("більше - менше"); 2) відношення між операндами без знака ("вище нижче"); 3) стан арифметичних прапорів ZF, SF, CF, OF, PF (але не AF). Команди умовного переходу мають однаковий синтаксис: jcc Команда порівняння cmp має цікавий принцип роботи. Він абсолютно такий самий, як і у команди віднімання - sub операнд_1, операнд_2. Команда cmp так само, як і команда sub, виконує віднімання операндів і встановлює прапори. Єдине, чого вона не робить – це запис результату віднімання на місце першого операнда. Синтаксис команди cmp - cmp операнд_1, операнд_2 (compare) - порівнює два операнди і за результатами порівняння встановлює прапори. Організація циклів Організувати циклічне виконання певної ділянки програми можна, наприклад, використовуючи команди умовної передачі або команду безумовного переходу jmp: 1) loop міткапереходу (Loop) - повторити цикл. Команда дозволяє організувати цикли, подібні до циклів for у мовах високого рівня з автоматичним зменшенням лічильника циклу; 2) loope/loopz міткапереходу Команди loope та loopz - абсолютні синоніми; 3) loopne/loopnz міткапереходу Команди loopne та loopnz також абсолютні синоніми. Команди loope/loopz та loopne/loopnz за принципом своєї роботи є взаємозворотними. Автор: Цвєткова А.В.
▪ Контроль та ревізія. Шпаргалка ▪ Теорія держави і права. Конспект лекцій ▪ Російська література ХІХ століття короткому викладі. Шпаргалка
Запрацювала найвища у світі астрономічна обсерваторія
04.05.2024 Управління об'єктами за допомогою повітряних потоків
04.05.2024 Породисті собаки хворіють не частіше, ніж безпородні
03.05.2024
▪ Захищений смартфон Oukitel WP21 ▪ Передача даних з мозку до комп'ютера з вен ▪ Лазер завбільшки з вірусну частинку ▪ Протимікробна плівка для побутових поверхонь
▪ Розділ сайту Афоризми знаменитих людей. Добірка статей ▪ стаття Порядок підготовки та вступу до військових освітніх установ. Основи безпечної життєдіяльності ▪ стаття У якій країні заборонено працювати надто худим топ-моделям? Детальна відповідь ▪ стаття Електропровідний клей. Поради радіоаматорам ▪ стаття Конструкції гучномовців. Енциклопедія радіоелектроніки та електротехніки
Головна сторінка | Бібліотека | Статті | Карта сайту | Відгуки про сайт
www.diagram.com.ua |


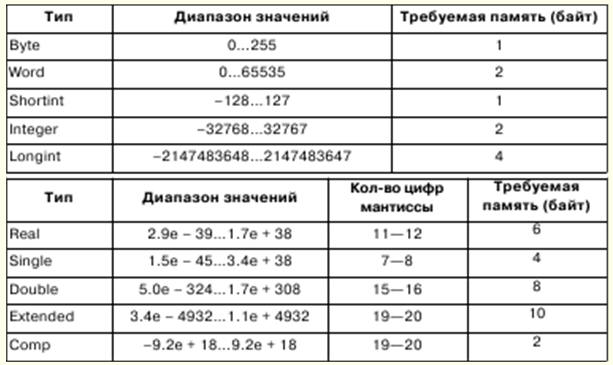

 Дивіться інші статті розділу
Дивіться інші статті розділу 