|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese
КОНСПЕКТИ ЛЕКЦІЙ, ШПАРГАЛКИ
Бази даних. Конспект лекцій: коротко, найголовніше
Довідник / Конспекти лекцій, шпаргалки Зміст
Лекція №1. 1. Системи управління базами даних Системи управління базами даних (СУБД) - це спеціалізовані програмні продукти, що дозволяють: 1) постійно зберігати скільки завгодно великі (але не нескінченні) обсяги даних; 2) вилучати і змінювати ці дані, що зберігаються в тому чи іншому аспекті, використовуючи при цьому так звані запити; 3) створювати нові бази даних, тобто описувати логічні структури даних та задавати їх структуру, тобто надають інтерфейс програмування; 4) звертатися до даних, що зберігаються, з боку декількох користувачів одночасно (тобто надають доступ до механізму управління транзакціями). Відповідно, бази даних - це набори даних, які під контролем систем управління. Нині системи управління базами даних є найскладнішими програмними продуктами над ринком і становлять його основу. Надалі передбачається вести розробки щодо поєднання звичайних систем управління базами даних з об'єктно-орієнтованим програмуванням (ООП) та інтернет-технологіями. Спочатку СУБД були засновані на ієрархічних и мережевих моделях даних, Т. е. дозволяли працювати тільки з деревоподібними та графовими структурами. У процесі розвитку 1970 р. з'явилися системи управління базами даних, запропоновані Коддом (Codd), засновані на реляційної моделі даних. 2. Реляційні бази даних Термін "реляційний" походить від англійського слова "relation" - "ставлення". У найзагальнішому математичному сенсі (як можна пам'ятати з класичного курсу алгебри множин) відношення - це безліч R = {(x1,..., xn) | x1 ∈ A1,...,xn ∈ An}, де A1,..., An - множини, що утворюють декартове твір. Таким чином, відношення R - це підмножина декартового твору множин: A1 x... x An : R ⊆ A 1 x... x An. Наприклад, розглянемо бінарні відносини суворого порядку "більше" і "менше" на безлічі впорядкованих пар чисел A 1 = A2 = {3, 4, 5}: R> = {(3, 4), (4, 5), (3, 5)} ⊂ A1 х А2; R< = {(5, 4), (4, 3), (5, 3)} ⊂ A1 х А2. Ці ж відносини можна у вигляді таблиць. Відношення "більше" R>:
Відношення "менше" R<:
Отже, бачимо, що у реляційних базах даних різні дані організовуються як відносин і може бути представлені у вигляді таблиць. Потрібно зауважити, що ці два розглянуті нами відносини R> і R< не еквівалентні між собою, іншими словами, таблиці, що відповідають цим відносинам, не рівні одна одній. Отже, форми представлення даних у реляційних БД можуть бути різними. У чому виявляється ця можливість різного уявлення у нашому випадку? Відносини R> і R< - це безлічі, а безліч - структура невпорядкована, отже, у таблицях, відповідних цим відносинам, рядки можна міняти між собою місцями. Але водночас елементи цих множин - це впорядковані набори, у разі - впорядковані пари чисел 3, 4, 5, отже, стовпці міняти місцями не можна. Отже, ми показали, що уявлення відносини (в математичному сенсі) як таблиці з довільним порядком рядків і фіксованим числом стовпців є прийнятною, правильної формою уявлення відносин. Але якщо розглядати відносини R> і R< з погляду закладеної у яких інформації, зрозуміло, що вони еквівалентні. Тому в реляційних базах даних поняття "відношення" має дещо інший зміст, ніж відношення до загальної математики. А саме воно не пов'язане з упорядкованістю по стовпцях у табличній формі уявлення. Натомість вводяться звані схеми відносин " рядок - заголовок стовпців " , т. е. кожному стовпцю дається заголовок, після чого їх можна безперешкодно міняти місцями. Ось як виглядатимуть наші відносини R> і R< у реляційній базі даних. Відношення суворого порядку (замість відношення R>):
Відношення суворого порядку (замість відношення R<):
Обидві таблиці-відносини одержують нове (у даному випадку однакове, оскільки введенням додаткових заголовків ми стерли різницю між відносинами R> і R<) Назва. Отже, бачимо, що з допомогою такого нескладного прийому, як доповнення таблиць необхідними заголовками, ми приходимо до того що, що R> і R< стають еквівалентними один одному. Таким чином, робимо висновок, що поняття "відношення" у загальному математичному та в реляційному сенсі збігаються не повністю, не є тотожними. Нині реляційні системи управління базами даних становлять основу ринку інформаційних технологій. Подальші дослідження ведуться у напрямку поєднання того чи іншого ступеня реляційної моделі. Лекція №2. Відсутні дані У системах управління базами даних для визначення відсутніх даних описано два види значень: порожні (або Empty-значення) та невизначені (або Null-значення). У деякій (переважно комерційної) літературі на Null-значення іноді посилаються як у порожні чи нульові значення, проте це неправильно. Сенс порожнього та невизначеного значення принципово відрізняється, тому необхідно уважно стежити за контекстом вживання того чи іншого терміну. 1. Порожні значення (Empty-значення) Порожнє значення - це одне з безлічі можливих значень якогось цілком певного типу даних. Перерахуємо найбільш "природні", безпосередні порожні значення (тобто порожні значення, які ми могли б виділити самостійно, не маючи жодної додаткової інформації): 1) 0 (нуль) – нульове значення є порожнім для числових типів даних; 2) false (неправильно) – є порожнім значенням для логічного типу даних; 3) B'' - порожній рядок біт для рядків змінної довжини; 4) "" - порожній рядок для рядків символів змінної довжини. У наведених вище випадках визначити, чи порожнє значення ні, можна шляхом порівняння наявного значення з константою порожнього значення, визначеної для кожного типу даних. Але системи управління базами даних з реалізованих у яких схем довгострокового зберігання даних можуть працювати з рядками постійної довжини. Через це порожнім рядком біт можна назвати рядок двійкових нулів. Або рядок, що складається з пробілів або інших керуючих символів, - порожнім рядком символів. Ось кілька прикладів порожніх рядків постійної довжини: 1) B'0'; 2) B'000'; 3) ''. Як же у цих випадках визначити, чи є рядок порожнім? У системах управління базами даних для перевірки на порожнечу застосовується логічна функція, тобто предикат IsEmpty (<вираз>)що буквально означає "є порожній". Цей предикат зазвичай вбудований у систему управління базами даних і може застосовуватися до виразу будь-якого типу. Якщо такого предикату в системах управління базами даних немає, можна написати логічну функцію самим і включити її до списку об'єктів проектованої бази даних. Розглянемо ще один приклад, коли не так просто визначити, чи порожнє ми маємо значення. Дані типу "дата". Яке значення в цьому типі вважати порожнім значенням, якщо дата може змінюватись в діапазоні від 01.01.0100. до 31.12.9999? Для цього в СУБД вводиться спеціальне позначення для константи порожньої дати {...}, якщо значення цього записується: {ДД. ММ. РР} або {РР. ММ. ДД}. З цим значенням відбувається порівняння при перевірці значення на порожнечу. Воно вважається цілком певним, "повноправним" значенням висловлювання цього типу, причому найменшим із можливих. При роботі з базами даних порожні значення часто використовуються як значення за промовчанням або застосовуються, якщо значення виразів відсутні. 2. Невизначені значення (Null-значення) Слово Null використовується для позначення невизначених значень у базах даних. Щоб краще зрозуміти, які значення розуміються під невизначеними, розглянемо таблицю, яка є фрагментом бази даних:
Отже, невизначене значення або Null-значення - це: 1) невідоме, але звичайне, тобто застосовне значення. Наприклад, у пана Хайретдінова, який є номером один у нашій базі даних, безсумнівно, є якісь паспортні дані (як у людини 1980 р. народження та громадянина країни), але вони не відомі, отже, не занесені до бази даних. Тому у відповідну графу таблиці буде записано значення Null; 2) незастосовне значення. У пана Карамазова (№ 2 у нашій базі даних) просто не може бути жодних паспортних даних, тому що на момент створення цієї бази даних або внесення до неї даних він був дитиною; 3) значення будь-якої комірки таблиці, якщо ми не можемо сказати застосовне воно чи ні. Наприклад, у пана Коваленка, який займає третю позицію у складеній нами базі даних, невідомий рік народження, тому ми не можемо з упевненістю говорити про наявність чи відсутність у нього паспортних даних. Отже, значеннями двох осередків у рядку, присвяченому пану Коваленко буде Null-значення (перше - як невідоме взагалі, друге - як значення, природа якого невідома). Як і будь-які інші типи даних, Null-значення теж мають певні властивості. Перерахуємо найістотніші з них: 1) з часом розуміння Null-значення може змінюватися. Наприклад, у пана Карамазова (№ 2 у нашій базі даних) у 2014 р., тобто після досягнення повноліття, Null-значення зміниться на якесь конкретне цілком певне значення; 2) Null-значення може бути присвоєно змінної чи константі будь-якого типу (числового, рядкового, логічного, дати, часу тощо); 3) результатом будь-яких операцій над виразами з Null-значеннями як операнда є Null-значення; 4) винятком із попереднього правила є операції кон'юнкції та диз'юнкції в умовах законів поглинання (докладніше про закони поглинання дивіться у п. 4 лекції № 2). 3. Null-значення та загальне правило обчислення виразів Поговоримо докладніше про дії над виразами, що містять значення Null. Загальне правило роботи з Null-значеннями (те, що результат операцій над Null-значеннями є Null-значення) застосовується до наступних операцій: 1) до арифметичних; 2) до побитих операцій заперечення, кон'юнкції та диз'юнкції (крім законів поглинання); 3) до операцій із рядками (наприклад, конкотинації – зчеплення рядків); 4) до операцій порівняння (<, ≤, ≠, ≥, >). Наведемо приклади. В результаті застосування наступних операцій будуть отримані Null-значення: 3 + Null, 1/ Null, (Іванов' + '' + Null) ≔ Null Тут замість звичайної рівності використано операція підстановки "≔" через особливий характер роботи з Null-значеннями. Далі в подібних ситуаціях також використовуватиметься цей символ, який означає, що вираз праворуч від символу підстановки може замінити собою будь-який вираз зі списку ліворуч від символу підстановки. Характер Null-значень призводить до того, що часто в деяких виразах замість очікуваного нуля виходить Null-значення, наприклад: (x - x), y * (x - x), x * 0 ≔ null при x = null. Вся справа в тому, що при підстановці, наприклад, у виразі (x - x) значення x = Null, ми отримуємо вираз (Null - Null), і в силу набуває загальне правило обчислення значення виразу, що містить Null-значення, та інформація про тому, що тут Null-значення відповідає одній і тій же змінній втрачається. Можна дійти невтішного висновку, що з обчисленні будь-яких операцій, крім логічних, Null-значения інтерпретуються як незастосовні, І тому в результаті виходить теж Null-значення. Не менш несподіваними результатами призводить використання Null-значень в операціях порівняння. Наприклад, у наступних виразах також виходять Null-значення замість очікуваних логічних значень True або False: (Null <Null); (Null ≤ Null); (Null = Null); (Null ≠ Null); (Null > Null); (Null ≥ Null) ≔ Null; Таким чином, робимо висновок, що не можна говорити про те, що Null-значення одно чи не дорівнює самому собі. Кожне нове входження Null-значення сприймається як незалежне, і щоразу Null-значення сприймаються як різні невідомі значення. Цим Null-значення кардинально відрізняються від усіх інших типів даних, адже ми знаємо, що про всі пройдені раніше величини та їх типи з упевненістю можна було говорити, що вони рівні чи не рівні один одному. Отже, бачимо, що Null-значения є значеннями змінних у звичайному значенні цього терміну. Тому стає неможливим порівнювати значення змінних або вирази, що містять Null-значення, оскільки в результаті ми отримуватимемо не логічні значення True або False, а Null-значення, як у таких прикладах: (x <Null); (x ≤ Null); (x = Null); (x ≠ Null); (x > Null); (x ≥ Null) ≔ Null; Тому за аналогією з порожніми значеннями для перевірки виразу на Null-значення необхідно використовувати спеціальний предикат: IsNull (<вираз>)що буквально означає "є Null". Логічна функція повертає значення True, якщо у виразі є Null або воно дорівнює Null, і False - в іншому випадку, але ніколи не повертає значення Null. Предикат IsNull може застосовуватися до змінних та виразів будь-якого типу. Якщо застосовувати його до виразів порожнього типу, предикат завжди повертатиме False. Наприклад:
Отже, бачимо, що у першому випадку, коли предикат IsNull взяли від нуля, на виході вийшло значення False. У всіх випадках, у тому числі в другому і третьому, коли аргументи логічної функції виявилися рівними Null-значенню, і в четвертому випадку, коли сам аргумент і був спочатку дорівнює Null-значенню, предикат видав значення True. 4. Null-значення та логічні операції Зазвичай у системах управління базами даних безпосередньо підтримуються лише три логічні операції: заперечення ¬, кон'юнкція & та диз'юнкція ∨. Операції ⇒ і рівносильності ⇔ виражаються через них за допомогою підстановок: (x ⇒ y) ≔ (¬x ∨ y); (x ⇔ y) ≔ (x ⇒ y) & (y ⇒ x); Зауважимо, що ці підстановки повністю зберігаються при використанні Null-значень. Цікаво, що за допомогою операції заперечення "¬" будь-яка з операцій кон'юнкція & або диз'юнкція ∨ може бути виражена одна через іншу таким чином: (x & y) ≔¬ (¬x ∨¬y); (x ∨ y) ≔ ¬ (¬x & ¬y); На ці підстановки, як і попередні, Null-значения впливу не надають. А тепер наведемо таблиці істинності логічних операцій заперечення, кон'юнкції та диз'юнкції, але крім звичних значень True і False, використовуємо також Null-значення як операнди. Для зручності введемо такі позначення: замість True писатимемо t, замість False - f, а замість Null - n. 1. Заперечення ¬x.
Варто відзначити такі цікаві моменти щодо операції заперечення з використанням Null-значень: 1) ¬x ≔ x - закон подвійного заперечення; 2) Null ≔ Null - Null-значення є нерухомою точкою. 2. Кон'юнкція x&y.
Ця операція також має свої властивості: 1) x & y ≔ y & x - комутативність; 2) x & x ≔ x – ідемпотентність; 3) False & y ≔ False, тут False - поглинаючий елемент; 4) True & y ≔ y, тут True – нейтральний елемент. 3. Диз'юнкція x ∨ y.
властивості: 1) x ∨ y ≔ y ∨ x - комутативність; 2) x ∨ x ≔ x – ідемпотентність; 3) False ∨ y ≔ y, тут False – нейтральний елемент; 4) True ∨ y ≔ True, тут True - поглинаючий елемент. Виняток із загального правила становлять правила обчислення логічних операцій кон'юнкція & та диз'юнкція ∨ в умовах дії законів поглинання: (False & y) ≔ (x & False) ≔ False; (True ∨ y) ≔ (x ∨ True) ≔ True; Ці додаткові правила формулюються для того, щоб при заміні Null-значення значеннями False або True результат все одно не залежав би від цього значення. Як і раніше було показано для інших типів операцій, застосування Null-значень у логічних операціях можуть призвести до несподіваних значень. Наприклад, логіка на перший погляд порушена в законі виключення третього (x ∨ ¬x) та в законі рефлексивності (x = x), оскільки при x ≔ Null маємо: (x ∨ ¬x), (x = x) ≔ Null. Закони не виконуються! Пояснюється це так само, як і раніше: при підстановці Null-значення у виразі інформація про те, що це значення повідомляється однією і тією ж змінною втрачається, а в силу набуває загальне правило роботи з Null-значеннями. Таким чином, робимо висновок: при виконанні логічних операцій з Null-значеннями як операнда ці значення визначаються системами управління базами даних як застосовне, але невідоме. 5. Null-значення та перевірка умов Отже, з усього вищесказаного можна дійти невтішного висновку, що у логіці систем управління базами даних є два логічних значення (True і False), а три, адже Null-значение також сприймається як одне з можливих логічних значень. Саме тому на нього часто посилаються як на невідоме значення Unknown. Проте, попри це, у системах управління базами даних реалізується лише двозначна логіка. Тому умова з Null-значенням (невизначена умова) має інтерпретуватися машиною або як True, або як False. У мові СУБД за замовчуванням встановлено впізнання умови з значенням Null як значення False. Проілюструємо це наступними прикладами реалізації в системах управління базами даних умовних операторів If та While: If P then A else B; Цей запис означає: якщо P набуває значення True, то виконується дія A, а якщо P набуває значення False або Null, то виконується дія B. Тепер застосуємо до цього оператора операцію заперечення, отримаємо: If ¬P then B else A; У свою чергу, цей оператор означає наступне: якщо P приймає значення True, то виконується дія B, а в тому випадку, якщо P приймає значення False або Null, то виконуватиме дію A. І знову, як бачимо, з появою Null-значения ми зіштовхуємося з несподіваними результатами. Справа в тому, що два оператори If у цьому прикладі не еквівалентні! Хоча один із них отриманий з іншого запереченням умови та перестановкою гілок, тобто стандартною операцією. Такі оператори загалом еквівалентні! Але в нашому прикладі бачимо, що Null-значенню умови P у першому випадку відповідає команда B, а у другому - A. А тепер розглянемо дію умовного оператора While: While P do A; B; Як працює оператор? Поки змінна P має значення True, виконуватиметься дія A, а як тільки P прийме значення False або Null, виконається дія B. Не завжди Null-значения інтерпретуються як False. Наприклад, в обмеженнях цілісності невизначені умови пізнаються як True (обмеження цілісності - це умови, що накладаються на вхідні дані та забезпечують їхню коректність). Це відбувається тому, що в таких обмеженнях відкинути потрібно лише свідомо неправдиві дані. І знову-таки в системах управління базами даних існує спеціальна функція заміни IfNull (обмеження цілісності, True), за допомогою якої Null-значення та невизначені умови можна подати у явному вигляді. Перепишемо умовні оператори If та While з використанням цієї функції: 1) If IfNull (P, False) then A else B; 2) While IfNull (P, False) do A; B; Отже, функція заміни IfNull (вираз 1, вираз 2) повертає значення першого виразу, якщо воно не містить Null-значення, і значення другого виразу - інакше. Треба зауважити, що на тип виразу, що повертається функцією IfNull, ніяких обмежень не накладається. Тому за допомогою цієї функції можна явно перевизначити будь-які правила роботи з значеннями Null. Лекція №3. Реляційні об'єкти даних 1. Вимоги до табличної форми подання відносин 1. Найперша вимога, що пред'являється до табличній формі уявлення відносин, - це кінцівка. Працювати з нескінченними таблицями, відносинами або будь-якими іншими уявленнями та організаціями даних незручно, рідко виправдовуються витрачені зусилля, і, крім того, подібний напрямок має практичний додаток. Але, крім цього, цілком очікуваного, існують й інші вимоги. 2. Заголовок таблиці, що становить ставлення, повинен обов'язково складатися з одного рядка - заголовка стовпців, причому з унікальними іменами. Багатоярусних заголовків не допускається. Наприклад, таких:
Усі багатоярусні заголовки замінюються одноярусними шляхом підбору відповідних заголовків. У нашому прикладі таблиця після зазначених перетворень виглядатиме так:
Ми бачимо, що ім'я кожного стовпця унікальне, тому їх можна як завгодно міняти місцями, тобто їхній порядок стає несуттєвим. А це дуже важливо, оскільки є третьою властивістю. 3. Порядок рядків має бути несуттєвим. Однак ця вимога також не є строго обмежувальною, оскільки можна легко привести будь-яку таблицю до необхідного вигляду. Наприклад, можна ввести додатковий стовпець, який визначатиме порядок рядків. У цьому випадку від перестановки рядків також нічого не зміниться. Ось приклад такої таблиці:
4. У таблиці, яка представляє відношення, не повинно бути рядків-дублікатів. Якщо ж у таблиці зустрічаються рядки, що повторюються, це можна легко виправити введенням додаткового стовпця, що відповідає за кількість дублікатів кожного рядка, наприклад:
Наступна властивість також є цілком очікуваною, тому що лежить в основі всіх принципів програмування та проектування реляційних баз даних. 5. Дані у всіх стовпцях повинні бути одного й того самого типу. І крім того, вони повинні бути простого типу. Пояснимо, що таке простий та складний типи даних. Простий тип даних - це такий тип, значення даних якого є складовими, т. е. не містять складових частин. Таким чином, у стовпцях таблиці не повинні бути присутні ні списки, ні масиви, ні дерева, ні подібні до названих складові об'єкти. Такі об'єкти - складовий тип даних - у реляційних системах управління базами даних самі представляються як самостійних таблиць-отношений. 2. Домени та атрибути Домени та атрибути - базові поняття в теорії створення баз даних та управління ними. Пояснимо, що це таке. Формально, домен атрибуту (позначається dom(a)), де а - якийсь атрибут, визначається як безліч допустимих значень одного й того самого типу відповідного атрибуту а. Цей тип має бути простим, тобто: dom(a) ⊆ {x | type(x) = type(a)}; Атрибут (позначається а), своєю чергою, визначається як упорядкована пара, що складається з імені атрибуту name(a) і домену атрибуту dom(a), тобто: a = (name(a): dom(a)); У цьому вся визначенні замість звичного знака "," (як у стандартних визначеннях упорядкованих пар) використовується ":". Це робиться для того, щоб підкреслити асоціацію домену атрибуту та типу даних атрибуту. Наведемо кілька прикладів різних атрибутів: а1 = (Курс: {1, 2, 3, 4, 5}); а2 = (МассаКг: {x | type(x) = real, x 0}); а3 = (Довжина Див: {x | type(x) = real, x 0}); Зауважимо, що атрибути а2 і а3 домени формально збігаються. Але семантичне значення цих атрибутів по-різному, адже порівнювати значення маси і довжини безглуздо. Тому домен атрибута асоціюється не лише з типом припустимих значень, а й з семантичним значенням. У табличній формі подання відносин атрибут відображається як заголовок стовпця таблиці, і при цьому домен атрибуту не вказується, але мається на увазі. Це виглядає так:
Неважко помітити, що тут кожен із заголовків a1, то2, то3 стовпців таблиці, що представляє якесь відношення, є окремим атрибутом. 3. Схеми відносин. Іменовані значення кортежів У теорії та практиці СУБД поняття схеми відношення та іменованого значення кортежу на атрибуті є базовими. Наведемо їх. Схема відношення (позначається S) визначається як кінцева множина атрибутів з унікальними іменами, тобто: S = {a | a ∈ S}; У кожній таблиці, що становить відношення, всі заголовки стовпців (усі атрибути) об'єднуються у схему цього відношення. Кількість атрибутів у схемі відносин визначає ступінь цього відносини і позначається як потужність множини: |S|. Схема відносин може порівнюватися з ім'ям схеми відносин. У табличній формі уявлення відносин, як неважко помітити, схема відношення - це не що інше, як рядок заголовків стовпців.
S = {a1, то2, то3, то4} - Схема відносин цієї таблиці. Ім'я відношення зображується як схематичний заголовок таблиці. У текстовій формі подання схема відносин може бути представлена як іменований список імен атрибутів, наприклад: Студенти (№ залікової книжки, Прізвище, Ім'я, По-батькові, Дата народження). Тут, як і в табличній формі уявлення, домени атрибутів не вказуються, але маються на увазі. З визначення випливає, що схема відношення може бути порожньою (S = ∅). Щоправда, можливо це лише теоретично, оскільки практично система управління базами даних будь-коли допустить створення порожньої схеми відносини. Іменоване значення кортежу на атрибуті (позначається t(a)) визначається за аналогією з атрибутом як упорядкована пара, що складається з імені атрибута і значення атрибута, тобто: t(a) = (name(a) : x), x ∈ dom(a); Бачимо, що значення атрибута береться із домену атрибута. У табличній формі уявлення відношення кожне іменоване значення кортежу на атрибуті - це відповідний осередок таблиці:
Тут t(a1), t(a2), t(a3) - іменовані значення кортежу t на атрибутах а1, а2, а3. Найпростіші приклади іменованих значень кортежів на атрибутах: (Курс: 5), (Балл: 5); Тут відповідно Курс і Бал – імена двох атрибутів, а 5 – це одне з їх значень, взяте з їхніх доменів. Зрозуміло, хоч ці значення в обох випадках рівні один одному, семантично вони різні, тому що безліч цих значень в обох випадках відрізняються один від одного. 4. Кортежі. Типи кортежів Поняття кортежу в системах управління базами даних може бути інтуїтивно знайдено вже з попереднього пункту, коли ми говорили про іменоване значення кортежу на різних атрибутах. Отже, кортеж (позначається t, від англ. tuple - "кортеж") зі схемою відносини S визначається як безліч іменованих значень цього кортежу на всіх атрибутах, що входять до цієї схеми відносин S. Іншими словами, атрибути беруться з області визначення кортежу, def(t), Т. е.: t ≡ t(S) = {t(a) | a ∈ def(t) ⊆ S;. Важливо, що одному імені атрибута обов'язково має відповідати трохи більше значення атрибута. У табличній формі запису відношення кортежем буде будь-який рядок таблиці, тобто:
Тут t1(S) = {t(a1), t(a2), t(a3), t(a4)} і t2(S) = {t(a5), t(a6), t(a7), t(a8)} - Кортежі. Кортежі в СУБД розрізняються за типам залежно від своєї галузі визначення. Кортежі називаються: 1) частковимиякщо їх область визначення включається або збігається зі схемою відношення, тобто def(t) ⊆ S. Це загальний випадок у практиці баз даних; 2) повними, Якщо їх область визначення повністю збігається, дорівнює схемі відношення, тобто def(t) = S; 3) неповними, якщо область визначення повністю включається до схеми відносин, тобто def(t) ⊂ S; 4) ніде не визначеними, якщо їх область визначення дорівнює порожній множині, тобто def(t) = ∅. Пояснимо на прикладі. Нехай ми маємо відношення, задане наступною таблицею.
Нехай тут t1 = {10, 20, 30}, t2 = {10, 20, Null}, t3 = {Null, Null, Null}. Тоді легко помітити, що кортеж t1 - повний, оскільки його область визначення def(t1) = {a, b, c} = S. Кортеж t2 - неповний, def(t2) = { a, b} ⊂ S. І, нарешті, кортеж t3 - ніде не визначений, оскільки його def(t3) = ∅. Слід зазначити, що ніде не певний кортеж - це пусте безліч, проте асоційоване зі схемою відносин. Іноді ніде не визначений кортеж позначається: ∅(S). Як ми вже бачили в наведеному прикладі, такий кортеж є рядком таблиці, що складається тільки з Null-значень. Цікаво, що порівнянними, Т. е. можливо рівними, є лише кортежі з однією і тією ж схемою відносин. Тому, наприклад, два ніде не визначені кортежі з різними схемами відносин не будуть рівними, як могло очікуватися. Вони будуть різними так само, як їхні схеми відносин. 5. Відносини. Типи відносин І нарешті дамо визначення ставлення, як до якоїсь вершині піраміди, що складається з усіх попередніх понять. Отже, відношення (позначається r, від англ. relation - "відношення") зі схемою відносин S визначається як обов'язково кінцева множина кортежів, що мають ту ж схему відносини S. Таким чином: r ≡ r(S) = {t(S) | t ∈r}; За аналогією зі схемами відносин кількість кортежів щодо називають потужністю відносин і позначають як потужність множини: |r|. Відносини, як і кортежі, різняться за типами. Отже, відносини називаються: 1) частковими, якщо для будь-якого кортежу, що входить у відношення, виконується наступна умова: [def(t) ⊆ S]. Це (як і з кортежами) загальний випадок; 2) повними, в тому випадку якщо ∀t ∈ r(S) виконується: [def(t) = S]; 3) неповнимиякщо ∃t ∈ r(S) def(t) ⊂ S; 4) ніде не визначенимиякщо ∀t ∈ r(S) [def(t) = ∅]. Звернімо окрему увагу на ніде не певні стосунки. На відміну від кортежів робота з такими відносинами включає невелику тонкість. Справа в тому, що ніде не певні відносини можуть бути двох видів: вони можуть бути порожніми, або можуть містити єдиний ніде не певний кортеж (такі відносини позначаються {∅(S)}). Порівняними (за аналогією з кортежами), тобто, можливо рівними, є лише відносини з однією схемою відносини. Тому відносини із різними схемами відносин є різними. У табличній формі уявлення, відношення - це тіло таблиці, якому відповідає рядок - заголовок стовпців, тобто буквально - вся таблиця, разом з першим рядком, що містить заголовки. Лекція №4. Реляційна алгебра. Унарні операції Реляційна алгебра, Як неважко здогадатися, - це особливий різновид алгебри, в якій всі операції виробляються над реляційними моделями даних, тобто над відносинами. У табличних термінах відношення включає рядки, стовпці і рядок - заголовок стовпців. Тому природними унарними операціями є операції вибору певних рядків чи стовпців, і навіть зміни заголовків стовпців - перейменування атрибутів. 1. Унарна операція вибірки Першою унарною операцією, яку ми розглянемо, є операція вибірки - операція вибору рядків з таблиці, що представляє відношення, за яким-небудь принципом, тобто вибір рядків-кортежів, що задовольняють певну умову чи умови. Оператор вибірки позначається σ , умова вибірки - P , тобто оператор σ береться завжди з певною умовою на кортежі P, а сама умова P записується залежним від схеми відношення S. З урахуванням всього цього сама операція вибірки над схемою відношення S стосовно r буде виглядати наступним чином: σ r(S) ≡ σ r = {t(S) | t ∈ r & P t } = {t (S) | Результатом цієї операції буде нове відношення з тією ж схемою відношення S, що складається з кортежів t(S) вихідного відношення-операнда, які задовольняють умові вибірки P t. Зрозуміло, що для того, щоб застосувати якусь умову до кортежу, необхідно підставити атрибути кортежу замість імен атрибутів. Щоб краще зрозуміти принцип цієї операції, наведемо приклад. Нехай дана наступна схема відношення: S: Сесія (№ залікової книжки, Прізвище, Предмет, Оцінка). Умову вибірки візьмемо таке: P = (Предмет = 'Інформатика' and Оцінка > 3). Нам необхідно з вихідного відношення-операнда виділити ті кортежі, в яких міститься інформація про студентів, які здали предмет "Інформатика" не нижче ніж на три бали. Нехай також дано наступний кортеж із цього відношення: t0(S) ∈ r(S): {(№ залікової книжки: 100), (Прізвище: 'Іванів'), (Предмет: 'Бази даних'), (Оцінка: 5)}; Застосовуємо нашу умову вибірки до кортежу t0, Отримуємо: P t0 = ('Бази даних' = 'Інформатика' and 5 > 3); На даному конкретному кортежі умова вибірки не виконується. А взагалі результатом цієї конкретної вибірки σ<Предмет = 'Інформатика' and Оцінка > 3 > Сесія буде таблиця "Сесія", в якій залишено рядки, що задовольняють умову вибірки. 2. Унарна операція проекції Ще одна стандартна унарна операція, яку ми вивчимо, – це операція проекції. Операція проекції - це операція вибору стовпців з таблиці, що становить відношення, за якоюсь ознакою. А саме машина вибирає ті атрибути (тобто буквально ті стовпці) вихідного відношення-операнда, які були вказані у проекції. Оператор проекції позначається [S'] або π . Тут S' - підсхема вихідної схеми відношення S, тобто її деякі стовпці. Що це означає? Це означає, що у S' атрибутів менше, ніж у S, тому що у S' залишилися тільки ті з них, для яких виконалася умова проекції. А в таблиці, що представляє відношення r(S' ), рядків стільки ж, скільки їх у таблиці r(S), а стовпців - менше, так як залишилися тільки відповідні атрибутам, що залишилися. Таким чином, оператор проекції π< S'> стосовно r(S) дає в результаті нове відношення з іншою схемою відношення r(S' ), що складається з проекцій t(S) [S' ] кортежів вихідного відношення. Як визначаються ці проекції кортежів? проекція будь-якого кортежу t(S) вихідного відношення r(S) на підсхему S' визначається такою формулою: t(S) [S'] = {t(a)|a ∈ def(t) ∩ S'}, S' ⊆S. Важливо зауважити, що дублікати кортежів з результату виключаються, тобто в таблиці, що представляє нове, результуюче відношення рядків, що повторюються, не буде. З урахуванням всього вищесказаного, операція проекції в термінах систем управління базами даних буде виглядати так: π r(S) ≡ π r ≡ r(S) [S'] ≡ r [S'] = {t(S) [S'] | t ∈ r}; Розглянемо приклад, що ілюструє принцип роботи операції вибірки. Нехай дано відношення "Сесія" та схема цього відношення: S: Сесія (№ залікової книжки, Прізвище, Предмет, Оцінка); Нас цікавитимуть лише два атрибути з цієї схеми, а саме "№ залікової книжки" та "Прізвище" студента, тому підсхема S' виглядатиме так: S': (№ залікової книжки, Прізвище). Потрібне вихідне відношення r(S) спроектувати на підсхему S'. Далі, нехай нам дано кортеж t0(S) з вихідного відношення: t0(S) ∈ r(S): {(№ залікової книжки: 100), (Прізвище: 'Іванів'), (Предмет: 'Бази даних'), (Оцінка: 5)}; Отже, проекція цього кортежу на цю підсхему S' виглядатиме так: t0(S) S': {(№ залікової книжки: 100), (Прізвище: 'Іванів')}; Якщо говорити про операцію проекції в термінах таблиць, то проекція Сесія [№ залікової книжки, Прізвище] вихідного відношення - це таблиця Сесія, з якої викреслено всі стовпці, крім двох: № залікової книжки та Прізвище. Крім того, всі рядки, що дублюються, також видалені. 3. Унарна операція перейменування І остання унарна операція, яку ми розглянемо, – це операція перейменування атрибутів. Якщо говорити про ставлення як таблиці, то операція перейменування потрібна у тому, щоб змінити назви всіх чи деяких стовпців. Оператор перейменування виглядає так: ρ<φ>, тут φ - функція перейменування. Ця функція встановлює взаємно-однозначну відповідність між іменами атрибутів схем S та Ŝ, де відповідно S – схема вихідного відношення, а Ŝ – схема відношення з перейменованими атрибутами. Таким чином, оператор ρ<φ> у застосуванні до відношення r(S) дає нове відношення зі схемою Ŝ, що складається з кортежів вихідного відношення тільки з перейменованими атрибутами. Запишемо операцію перейменування атрибутів у термінах систем управління базами даних: ρ<φ> r(S) ≡ ρ<φ>r = {ρ<φ> t(S)| t ∈ r}; Наведемо приклад використання цієї операції: Розглянемо вже знайоме нам ставлення Сесія зі схемою: S: Сесія (№ залікової книжки, Прізвище, Предмет, Оцінка); Введемо нову схему відносини Ŝ, з іншими іменами атрибутів, які ми хотіли б бачити замість наявних: Ŝ : (№ ЗК, Прізвище, Предмет, Бал); Наприклад, замовник бази даних захотів у вашому готовому відношенні бачити інші назви. Щоб втілити це замовлення, необхідно спроектувати наступну функцію перейменування: φ : (№ залікової книжки, Прізвище, Предмет, Оцінка) → (№ ЗК, Прізвище, Предмет, Бал); Фактично потрібно змінити ім'я тільки у двох атрибутів, тому законно буде записати наступну функцію перейменування замість наявної: φ : (№ залікової книжки, Оцінка) → (№ ЗК, Бал); Далі, нехай дано також вже знайомий нам кортеж, що належить відношенню Сесія: t0(S) ∈ r(S): {(№ залікової книжки: 100), (Прізвище: 'Іванів'), (Предмет: 'Бази даних'), (Оцінка: 5)}; Застосуємо оператор перейменування до цього кортежу: ρ<φ> t0(S): {(№ ЗК: 100), (Прізвище: 'Іванів'), (Предмет: 'Бази даних'), (Балл: 5)}; Отже, це один із кортежів нашого відношення, у якого перейменували атрибути. У табличних термінах відношення ρ < № залікової книжки, Оцінка → "№ ЗК, Бал > Сесія - це нова таблиця, отримана із таблиці відносини "Сесія", перейменуванням зазначених атрибутів. 4. Властивості унарних операцій Унарні операції, як і будь-які інші, мають певні властивості. Розглянемо найважливіші їх. Першим властивістю унарних операцій вибірки, проекції та перейменування є властивість, що характеризує співвідношення потужностей відносин. (Нагадаємо, що потужність - це кількість кортежів у тому чи іншому відношенні.) Зрозуміло, що тут розглядається відповідно відношення вихідне та відношення, отримане в результаті застосування тієї чи іншої операції. Зауважимо, що всі властивості унарних операцій випливають безпосередньо з їх визначень, тому їх можна легко пояснити і навіть за бажання вивести самостійно. Отже: 1) співвідношення потужностей: а) для операції вибірки: | σ r | ≤ | r |; б) для операції проекції: | r[S'] | ≤ |r|; в) для операції перейменування: | ρ<φ>r | = | r |; Отже, бачимо, що з двох операторів, саме для оператора вибірки і оператора проекції, потужність вихідних відносин - операндів більше, ніж потужність відносин, одержуваних з вихідних застосуванням відповідних операцій. Це тому, що з виборі, супутньому дії цих двох операцій вибірки і проекції, відбувається виключення деяких рядків чи стовпців, які задовольнили умовам вибору. У тому випадку, коли умовам задовольняють усі рядки чи стовпці, зменшення потужності (тобто кількості кортежів) не відбувається, тому у формулах нерівність не сувора. У разі операції перейменування потужність відносини не змінюється, за рахунок того, що при зміні імен ніякі кортежі з відношення не виключаються; 2) властивість ідемпотентності: а) для операції вибірки: σ r = σ ; б) для операції проекції: r [S'] [S'] = r [S']; в) для операції перейменування у випадку властивість ідемпотентності неприменимо. Ця властивість означає, що подвійне послідовне застосування одного і того ж оператора до будь-якого відношення рівносильне його одноразовому застосуванню. Для операції перейменування атрибутів відносини, взагалі кажучи, ця властивість може бути застосована, але обов'язково зі спеціальними застереженнями та умовами. Властивість ідемпотентності дуже часто використовується для спрощення виду вираження та приведення його до більш економічного, актуального вигляду. І остання властивість, яку ми розглянемо, – це властивість монотонності. Цікаво помітити, що за будь-яких умов усі три оператори монотонні; 3) властивість монотонності: а) для операції вибірки: r1 ⊆ r2 ⇒ σ r1 ⇒ σ r2; б) для операції проекції: r1 ⊆ r2 ⇒ r1[S'] ⊆ r2 [S']; в) для операції перейменування: r1 ⊆ r2 ⇒ ρ<φ>r1 ⊆ ρ <φ>r2; Поняття монотонності в реляційній алгебрі аналогічне до цього ж поняття з алгебри звичайної, загальної. Пояснимо: якщо спочатку відношення r1 та r2 були пов'язані між собою таким чином, що r ⊆ r2, то після застосування будь-якого з трьох операторів вибірки, проекції чи перейменування це співвідношення збережеться. Лекція №5. Реляційна алгебра. Бінарні операції 1. Операції об'єднання, перетину, різниці У будь-яких операцій є свої правила застосування, яких необхідно дотримуватися, щоб вирази і дії не втрачали сенсу. Бінарні теоретико-множинні операції об'єднання, перетинів та різниці можуть бути застосовані тільки до двох відносин обов'язково з однією і тією ж схемою відношення. Результатом таких бінарних операцій будуть стосунки, що складаються з кортежів, що задовольняють умовам операцій, але з такою самою схемою відношення, як і в операндів. 1. Результатом операції об'єднання двох відносин r1(S) та r2(S) буде нове ставлення r3(S), що складається з тих кортежів відносин r1(S) та r2(S), які належать хоча б одному з вихідних відносин та з такою ж схемою відношення. Таким чином, перетин двох відносин - це: r3(S) = r1(S) ∪ r2(S) = {t(S) | t ∈r1 ∪t ∈r2}; Для наочності наведемо приклад у термінах таблиць: Нехай дані два відносини: r1(S):
r2(S):
Ми бачимо, що схеми першого та другого відносин однакові, тільки мають різну кількість кортежів. Об'єднанням цих двох відносин буде відношення r3(S), якому відповідатиме наступна таблиця: r3(S) = r1(S) ∪ r2(S):
Отже, схема відношення S не змінилася, тільки зросла кількість кортежів. 2. Перейдемо до розгляду наступної бінарної операції операції перетину двох відносин. Як ми знаємо ще зі шкільної геометрії, в результуюче ставлення увійдуть ті кортежі вихідних відносин, які присутні одночасно в обох відносинах r1(S) та r2(S) (знову звертаємо увагу на однакову схему відношення). Операція перетину двох відносин виглядатиме так: r4(S) = r1(S) ∩ r2(S) = {t(S) | t ∈ r1 & t ∈ r2}; І знову розглянемо дію цієї операції над відносинами, поданими у вигляді таблиць: r1(S):
r2(S):
Згідно з визначенням операції перетином відносин r1(S) та r2(S) буде нове ставлення r4(S), табличне уявлення якого виглядатиме наступним чином: r4(S) = r1(S) ∩ r2(S):
Дійсно, якщо подивитися на кортежі першого та другого вихідних відносин, загальний серед них лише один: {b, 2}. Він і став єдиним кортежем нового відношення.4(S). 3. Операція різниці двох відносин визначається аналогічним з попередніми операціями. Відносини-операнди, так само, як і в попередніх операціях, повинні мати однакові схеми відношення, тоді в результуюче ставлення увійдуть всі ті кортежі першого відношення, яких немає в другому, тобто: r5(S) = r1(S) \r2(S) = {t(S) | t ∈ r1 & t ∉ r2}; Вже добре знайомі нам стосунки r1(S) та r2(S), у табличному поданні виглядають наступним чином: r1(S):
r2(S):
Ми розглянемо як операнди в операції перетину двох відносин. Тоді, за цим визначенням, результуюче відношення r5(S) буде виглядати наступним чином: r5(S) = r1(S) \r2(S):
Розглянуті бінарні операції є базовими, ними грунтуються інші операції, складніші. 2. Операції декартового твору та природного з'єднання Операція декартового твору та операція природного з'єднання є бінарними операціями типу твору та ґрунтуються на операції об'єднання двох відносин, яку ми розглядали раніше. Хоча дію операції декартового твору багатьом може здатися знайомим, почнемо ми все-таки з операції природного твору, оскільки вона є загальнішим випадком, ніж перша операція. Отже, розглянемо операцію природної сполуки. Слід зазначити, що операндами цієї дії можуть бути відносини з різними схемами на відміну трьох бінарних операцій об'єднання, перетину і перейменування. Якщо розглянути два відносини з різними схемами відносин r1(S1) та r2(S2), то їх природною сполукою буде нове ставлення r3(S3), яке складатиметься лише з тих кортежів операндів, які збігаються на перетині схем відносин. Відповідно, схема нового відношення буде більшою за будь-яку зі схем відносин вихідних, оскільки є їх з'єднанням, "склеюванням". До речі, кортежі, однакові у двох відносинах-операндах, якими і відбувається це "склеювання", називаються сполучними. Запишемо визначення операції природного з'єднання мовою формул систем управління базами даних: r3(S3) = r1(S1) xr2(S2) = {t(S1 ∪S2) | t[S1] ∈ r1 & t(S2) ∈ r2}; Розглянемо приклад, який добре ілюструє роботу природного з'єднання, його "склеювання". Нехай дано два стосунки r1(S1) та r2(S2), у табличній формі подання відповідно рівні: r1(S1):
r2(S2):
Ми бачимо, що у цих відносин є кортежі, що збігаються при перетині схем S1 і S2 відносин. Перерахуємо їх: 1) кортеж {a, 1} відношення r1(S1) збігається з кортежем {1, x} відношення r2(S2); 2) кортеж {b, 1} із r1(S1) також збігається з кортежем {1, x} з r2(S2); 3) кортеж {c, 3} збігається з кортежем {3, z}. Отже, при природному поєднанні нове ставлення r3(S3) Виходить "склеюванням" саме на цих кортежах. Таким чином, r3(S3) у табличному поданні буде виглядати наступним чином: r3(S3) = r1(S1) xr2(S2):
Виходить за визначенням: схема S3 не збігається ні зі схемою S1, ні зі схемою S2, ми "склеили" дві вихідні схеми по кортежах, що перетинаються, щоб отримати їх природне з'єднання. Покажемо схематично, як відбувається з'єднання кортежів під час застосування операції природного з'єднання. Нехай відношення r1 має умовний вигляд:
А відношення r2 - Вид:
Тоді їх природне з'єднання виглядатиме так:
Бачимо, що "склеювання" відносин-операндів відбувається за тією самою схемою, що ми наводили раніше, розглядаючи приклад. Операція декартового з'єднання є окремим випадком операції природного з'єднання. Якщо конкретніше, то, розглядаючи дію операції декартового твору на відносини, ми свідомо обмовляємо, що в цьому випадку може йтися лише про схеми відносин, що не перетинаються. Через війну застосування обох операцій виходять відносини зі схемами, рівними об'єднанню схем відносин-операндов, лише декартово твір двох відносин потрапляють всілякі пари їх кортежів, оскільки схеми операндів в жодному разі повинні перетинатися. Таким чином, виходячи зі всього сказаного вище запишемо математичну формулу для операції декартового твору: r4(S4) = r1(S1) xr2(S2) = {t(S1 ∪ S2) | t [S1] ∈ r1 & t(S2) ∈ r2}, S1 ∩ S2= ∅; Тепер розглянемо приклад, щоб показати, який вигляд матиме результуюча схема відношення при застосуванні операції декартового твору. Нехай дані два відносини r1(S1) та r2(S2), які у табличному вигляді надаються таким чином: r1(S1):
r2(S2):
Отже, бачимо, що жоден з кортежів відносин r1(S1) та r2(S2), дійсно, не збігається у їхньому перетині. Тому в результуюче відношення r4(S4) потраплять всілякі пари кортежів першого та другого відносин-операндів. Вийде: r4(S4) = r1(S1) xr2(S2):
Вийшла нова схема відношення r4(S4) не "склеюванням" кортежів як у попередньому випадку, а перебором всіх можливих різних пар несупадних у перетині вихідних схем кортежів. Знову, як і у разі природної сполуки, наведемо схематичний приклад роботи операції декартового твору. Нехай r1 поставлено наступним умовним чином:
А відношення r2 поставлено:
Тоді їх декартове твір схематично можна зобразити так:
Саме таким чином і виходить результуюче відношення під час застосування операції декартового твору. 3. Властивості бінарних операцій З наведених вище визначень бінарних операцій об'єднання, перетину, різниці, декартового твору та природної сполуки випливають властивості. 1. Перша властивість, як і у разі унарних операцій, ілюструє співвідношення потужностей відносин: 1) для операції об'єднання: |r1 ∪ r2| ≤ |r1| + |r2|; 2) для операції перетину: |r1 ∩ r2 | ≤ min(|r1|, |r2|); 3) для операції різниці: |r1 \r2| ≤ |r1|; 4) для операції декартового твору: |r1 xr2| = | r1| · | r2|; 5) для операції природного з'єднання: |r1 xr2| ≤ |r1| · | r2|. Співвідношення потужностей, як пам'ятаємо, характеризує, як змінюється кількість кортежів у відносинах після застосування тієї чи іншої операції. Отже, що бачимо? Потужність об'єднання двох відносин r1 та r2 менше суми потужностей вихідних відносин-операндів. Чому це відбувається? Вся справа в тому, що при об'єднанні кортежі, що збігаються, зникають, накладаючись один на одного. Так, звернувшись до прикладу, який ми розглядали після проходження цієї операції, можна помітити, що в першому відношенні було два кортежі, у другому - три, а в результуючому - чотири, тобто менше, ніж п'ять (сума потужностей відносин-операндів ). За збігається кортежу {b, 2} ці відносини "склеилися". Потужність результату перетину двох відносин менше або дорівнює мінімальній потужності вихідних відносин-операндів. Звернемося до визначення цієї операції: у результуюче ставлення потрапляють лише ті кортежі, які є в обох відносинах вихідних. А отже, потужність нового відношення ніяк не може перевищувати потужності того відношення-операнда, число кортежів якого є найменшим з двох. А рівної цієї мінімальної потужності потужність результату може бути, оскільки завжди допускається випадок, коли всі кортежі відносини з меншою потужністю збігаються з якимись кортежами другого відносини-операнда. У разі операції різниці все досить очевидно. Справді, якщо з першого відносини-операнда "відняти" всі кортежі, присутні також у другому відношенні, то їх кількість (а отже, потужність) зменшиться. У тому випадку, якщо жоден кортеж першого відношення не співпаде з жодним кортежем відношення другого, тобто "вичитати" нічого не буде, потужність його не зменшиться. Цікаво, що у разі застосування операції декартового твору потужність результуючого відношення точно дорівнює твору потужностей двох відносин-операндів. Зрозуміло, що це відбувається тому, що результат записуються всі можливі пари кортежів вихідних відносин, а нічого не виключається. І, нарешті, операцією природного з'єднання виходить відношення, потужність якого більша або дорівнює добутку потужностей двох вихідних відносин. Знов-таки це відбувається тому, що відносини-операнди "склеюються" по кортежах, що збігаються, а незбігаючі - з результату виключаються зовсім. 2. Властивість ідемпотентності: 1) для операції об'єднання: r ∪ r = r; 2) для операції перетину: r ∩ r = r; 3) для операції різниці: r \ r ≠ r; 4) для операції декартового твору (загалом, властивість не застосовується); 5) для операції природної сполуки: rxr = r. Цікаво, що властивість ідемпотентності вірно не для всіх операцій з наведених, а для операції декартового твору воно і не застосовується. Справді, якщо об'єднати, перетнути чи природно поєднати будь-яке ставлення саме із собою, воно зміниться. А от якщо відібрати від відношення точно рівне йому ставлення, в результаті вийде порожнє ставлення. 3. Властивість комутативності: 1) для операції об'єднання: r1 ∪ r2 = r2 ∪ r1; 2) для операції перетину: r ∩ r = r ∩ r; 3) для операції різниці: r1 \r2 ≠ r2 \r1; 4) для операції декартового твору: r1 xr2 = r2 xr1; 5) для операції природного з'єднання: r1 xr2 = r2 xr1. Властивість комутативності виконується всім операцій, крім операції різниці. Це легко зрозуміти, адже від перестановки відносин місцями їхній склад (кортежі) не змінюється. А при застосуванні операції різниці важливо, яке з відносин-операндів стоїть на першому місці, тому що від цього залежить, кортежі якого відношення візьмуться за еталонні, тобто з якими кортежами порівнюватимуть інші кортежі щодо виключення. 4. Властивість асоціативності: 1) для операції об'єднання: (r1 ∪ r2) ∪ r3 = r1 ∪(r2 ∪ r3); 2) для операції перетину: (r1 ∩ r2) ∩ r3 = r1 ∩ (r2 ∩ r3); 3) для операції різниці: (r1 \r2) \ r3 ≠ r1 \ (r2 \r3); 4) для операції декартового твору: (r1 xr2) xr3 = r1 x (r2 xr3); 5) для операції природного з'єднання: (r1 xr2) xr3 = r1 x (r2 xr3). І знову бачимо, що властивість виконується всім операцій, крім операції різниці. Пояснюється це так само, як і у разі застосування властивості комутативності. За великим рахунком, операціям об'єднання, перетину, різниці та природної сполуки все одно в якому порядку стоять відносини-операнди. Але за "віднімання" відносин друг від друга порядок грає чільну роль. На підставі вищенаведених властивостей і міркувань можна зробити наступний висновок: три останні властивості, а саме властивість ідемпотентності, комутативності та асоціативності, вірні для всіх розглянутих нами операцій, крім операції різниці двох відносин, для якої не виконалося взагалі жодна з трьох зазначених властивостей, і Тільки одному випадку властивість виявилося неприменимым. 4. Варіанти операцій з'єднання Використовуючи як основу розглянуті раніше унарні операції вибірки, проекції, перейменування та бінарні операції об'єднання, перетину, різниці, декартового твору та природного з'єднання (всі вони в загальному випадку називаються операціями з'єднання), ми можемо запровадити нові операції, виведені за допомогою перерахованих понять та визначень. Подібна діяльність називається упорядкуванням варіантів операцій з'єднання. Першим таким варіантом операцій з'єднання є операція внутрішнього з'єднання за заданою умовою з'єднання. Операція внутрішнього з'єднання за певною умовою визначається як похідна операція від операцій декартового твору і вибірки. Запишемо формульне визначення цієї операції: r1(S1) х P r2(S2) = σ (r1 xr2), вул1 ∩ S2 = ∅; Тут P = P <S1 ∪ S2> - умова, що накладається об'єднання двох схем вихідних відносин-операндов. Саме за цією умовою і відбувається відбір кортежів із відносин r1 та r2 у результуюче ставлення. Слід зазначити, що операція внутрішньої сполуки може застосовуватися до відносин із різними схемами відносин. Ці схеми можуть бути будь-якими, але вони в жодному разі не повинні перетинатися. Кортежі вихідних відносин-операнда, що потрапили в результат операції внутрішнього з'єднання, називаються сполучними кортежами. Для наочного ілюстрування роботи операції внутрішнього з'єднання наведемо наступний приклад. Нехай нам дано два стосунки r1(S1) та r2(S2) з різними схемами відносини: r1(S1):
r2(S2):
Наступна таблиця дасть результат застосування операції внутрішньої сполуки за умовою P = (b1 = b2). r1(S1) х P r2(S2):
Отже, бачимо, що справді " злипання " двох таблиць, що представляють відносини, відбулося саме з тих кортежах, у яких виконується умова операції внутрішнього з'єднання P = (b1 = b2). Тепер на підставі вже введеної операції внутрішнього з'єднання ми можемо запровадити операцію лівого зовнішнього з'єднання и правого зовнішнього з'єднання. Пояснимо. Результатом операції ліве зовнішнє з'єднання є результатом внутрішнього з'єднання, поповнений непоєднуваними кортежами лівого вихідного відношення-операнда. Аналогічно результат операції правого зовнішнього з'єднання визначається як результат операції внутрішнього з'єднання, поповнений непоєднуваними кортежами вихідного відношення-операнда, що стоїть праворуч. Питання, чим поповнюються результуючі відносини операцій лівого і правого зовнішнього з'єднання, цілком очікуємо. Кортежі одного відносини-операнда доповнюються на схемі іншого відносини-операнда Null-значеннями. Варто зауважити, що введені таким чином операції лівої та правої зовнішньої сполуки є похідними операціями від операції внутрішньої сполуки. Щоб записати загальні формули для операцій лівого та правого зовнішнього з'єднань, проведемо деякі додаткові побудови. Нехай нам дано два стосунки r1(S1) та r2(S2) з різними схемами відносин S1 і S2, що не перетинаються один з одним. Оскільки ми вже говорили, що операції лівої та правої внутрішньої сполуки є похідними, ми можемо отримати такі допоміжні формули для визначення операції лівої зовнішньої сполуки: 1) r3 (S2 ∪ S1) ≔ r1(S1) х Pr2(S2); r 3 (S2 ∪ S1) - це просто результат внутрішнього з'єднання відносин r1(S1) та r2(S2). Ліва зовнішня сполука є похідною операцією саме від операції внутрішньої сполуки, тому ми і починаємо наші побудови з неї; 2) r4(S1) ≔ r 3(S2 ∪S1) [S1]; Таким чином, за допомогою унарної операції проекції, ми виділили всі сполучні кортежі лівого вихідного відношення-операнда r1(S1). Результат позначили r4(S1) для зручності застосування; 3) r5 (S1) ≔ r1(S1) \ r4(S1); Тут r1(S1) - всі кортежі лівого вихідного відношення-операнда, а r4(S1) - його кортежі, тільки сполучні. Таким чином, за допомогою бінарної операції різниці щодо r5(S1) у нас вийшли всі непоєднувані кортежі лівого відношення-операнда; 4) r6(S2)≔ {∅(S2)}; {∅(S2)} - це нове відношення зі схемою (S2), що містить лише один кортеж, причому складений з Null-значень. Для зручності ми позначили це ставлення r6(S2); 5) r7 (S2 ∪ S1) ≔ r5(S1) xr6(S2); Тут ми взяли отримані у пункті три, непоєднувані кортежі лівого відношення-операнда (r5(S1)) і доповнили їх на схемі другого відношення-операнда S2 Null-значеннями, тобто декартово помножили відношення, що складається з цих найбільш непоєднуваних кортежів на відношення r6(S2), визначене у пункті чотири; 6) r1(S1) →x P r2(S2) ≔ (r1 x P r2) ∪ r7 (S2 ∪ S1); Це і є ліве зовнішнє з'єднанняотримане, як можна бачити, об'єднанням декартового твору вихідних відносин-операндів r1 та r2 та відносини r7 (S2 ∪ S1), визначеного у пункті п'ятому. Тепер ми маємо всі необхідні викладки для визначення не тільки операції лівого зовнішнього з'єднання, але за аналогією і для визначення операції правого зовнішнього з'єднання. Отже: 1) операція лівого зовнішнього з'єднання у строгому формулярному вигляді виглядає так: r1(S1) →x P r2(S2) ≔ (r1 x P r2) ∪ [(r1 \ (r1 x P r2) [S1]) x {∅(S2)}]; 2) операція правого зовнішнього з'єднання визначається подібним чином операції лівого зовнішнього з'єднання і має такий вигляд: r1(S1) →x P r2(S2) ≔ (r1 x P r2) ∪ [(r2 \ (r1 x P r2) [S2]) x {∅(S1)}]; Ці дві похідні операції мають лише дві властивості, гідні згадки. 1. Властивість комутативності: 1) для операції лівого зовнішнього з'єднання: r1(S1) →x P r2(S2) ≠ r2(S2) →x P r1(S1); 2) для операції правої зовнішньої сполуки: r1(S1) ←x P r2(S2) ≠ r2(S2) ←x P r1(S1) Отже, ми бачимо, що властивість комутативності не виконується для цих операцій у загальному вигляді, але при цьому операції лівого та правого зовнішнього з'єднання взаємно обернені один до одного, тобто виконується: 1) для операції лівого зовнішнього з'єднання: r1(S1) →x P r2(S2) = r2(S2) →x P r1(S1); 2) для операції правої зовнішньої сполуки: r1(S1) ←x P r2(S2) = r2(S2) ←x Pr1(S1). 2. Основною властивістю операцій лівого та правого зовнішнього з'єднання є те, що вони дозволяють відновити вихідне відношення-операнд за кінцевим результатом тієї чи іншої операції з'єднання, тобто виконуються: 1) для операції лівого зовнішнього з'єднання: r1(S1) = (r1 →x P r2) [S1]; 2) для операції правої зовнішньої сполуки: r2(S2) = (r1 ←x P r2) [S2]. Таким чином, ми бачимо, що перше вихідне відношення-операнд можна відновити з результату операції лівого правого з'єднання, а якщо конкретніше, то застосуванням до цього з'єднання (r1 xr2) унарної операції проекції на схему S1, [S1]. І аналогічно друге вихідне відношення-операнд можна відновити застосуванням до результату операції правої зовнішньої сполуки (r1 xr2) унарної операції проекції на схему відношення S2. Наведемо приклад докладнішого розгляду роботи операцій лівого і правого зовнішніх соединений. Введемо вже знайомі нам відносини r1(S1) та r2(S2) з різними схемами відносини: r1(S1):
r2(S2):
Нез'єднаний кортеж лівого відношення-операнда r2(S2) - це кортеж {d, 4}. Дотримуючись визначення, саме їм слід доповнити результат внутрішньої сполуки двох вихідних відносин-операндів. Умова внутрішнього з'єднання відносин r1(S1) та r2(S2) також залишимо колишнє: P = (b1 = b2). Тоді результатом операції лівого зовнішнього з'єднання буде наступна таблиця: r1(S1) →x P r2(S2):
Справді, як бачимо, внаслідок впливу операції лівого зовнішнього з'єднання, відбулося поповнення результату операції внутрішнього з'єднання непоєднуваними кортежами лівого, т. е. у разі першого отношения-операнда. Поповнення кортежу на схемі другого (правого) вихідного відношення-операнда за визначенням відбулося за допомогою Null-значень. І аналогічно результатом правого зовнішнього з'єднання за тим самим, що й раніше, умовою P = (b1 = b2) вихідних відносин-операндів r1(S1) та r2(S2) є наступна таблиця: r1(S1) ←x P r2(S2):
Справді, у разі поповнювати результат операції внутрішнього з'єднання слід несоединимыми кортежами правого, у разі другого вихідного отношения-операнда. Такий кортеж, як не важко бачити, у другому відношенні r2(S2) один, а саме {2, y}. Далі діємо за визначенням операції правого зовнішнього з'єднання, доповнюємо кортеж першого (лівого) операнда на схемі першого операнда Null-значеннями. І, нарешті, розглянемо третій варіант наведених раніше операцій з'єднання. Операція повного зовнішнього з'єднання. Цю операцію цілком можна розглядати не тільки як операцію, похідну від операцій внутрішнього з'єднання, але і як поєднання операцій лівого та правого зовнішнього з'єднання. Операція повного зовнішнього з'єднання визначається як результат поповнення того ж самого внутрішнього з'єднання (як і у разі визначення лівого та правого зовнішніх з'єднань) непоєднуваними кортежами одночасно і лівого, і правого вихідних відносин-операндів. Виходячи з цього визначення дамо формулярний вид цього визначення: r1(S1) ↔x P r2(S2) = (r1 →x P r2) ∪ ( r1 ←x P r2); У операції повного зовнішнього з'єднання також є властивість, схожа з аналогічною властивістю операцій лівого та правого зовнішніх сполук. Тільки за рахунок початкової взаємно-зворотної природи операції повного зовнішнього з'єднання (адже вона була визначена як об'єднання операцій лівого та правого зовнішніх з'єднань) для неї виконується властивість комутативності: r1(S1) ↔x P r2(S2)= r2(S2) ↔ x P r1(S1); І для завершення розгляду варіантів операцій з'єднання розглянемо приклад, що ілюструє роботу операції повного зовнішнього з'єднання. Введемо два відносини r1(S1) та r2(S2) та умова з'єднання. Нехай r1(S1)
r2(S2):
І нехай умовою поєднання відносин r1(S1) та r2(S2) буде: P = (b1 = b2), як і в попередніх прикладах. Тоді результатом операції повного зовнішнього з'єднання відносин r1(S1) та r2(S2) за умовою P = (b1 = b2) буде наступна таблиця: r1(S1) ↔x P r2(S2):
Отже, бачимо, що операція повного зовнішнього з'єднання наочно виправдала своє визначення як поєднання результатів операцій лівого і правого зовнішніх сполук. Результуюче відношення операції внутрішнього з'єднання доповнено одночасно не з'єднувальним кортежами як лівого (першого, r1(S1)), так і правого (другого, r2(S2)) вихідного відношення-операнда. 5. Похідні операції Отже, ми розглянули різні варіанти операцій з'єднання, а саме операції внутрішнього з'єднання, лівого, правого та повного зовнішнього з'єднання, які є похідними восьми вихідних операцій реляційної алгебри: унарних операцій вибірки, проекції, перейменування та бінарних операцій об'єднання, перетину, різниці, декартового твору та природного з'єднання. Але серед цих вихідних операцій є свої приклади похідних операцій. 1. Наприклад, операція перетину двох відносин є похідною від операції різниці цих двох відносин. Покажемо це. Операцію перетину можна виразити такою формулою: r1(S) ∩ r2(S) = r1 \r1 \r2 або, що дає той самий результат: r1(S) ∩ r2(S) = r2 \r2 \r1; 2. Ще одним прикладом, похідної базової операції від восьми вихідних операцій є операція природного з'єднання. У найзагальнішому вигляді ця операція є похідною від бінарної операції декартового твору та унарних операцій вибірки, проекції та перейменування атрибутів. Проте, своєю чергою, операція внутрішнього з'єднання є похідною операцією від тієї ж операції декартового твору відносин. Тому, щоб показати, що операція природної сполуки - похідна операція, розглянемо наступний приклад. Порівняємо наведені раніше приклади для операцій природного та внутрішнього з'єднань. Нехай нам дано два стосунки r1(S1) та r2(S2) які виступатимуть як операнди. Вони рівні: r1(S1):
r2(S2):
Як ми вже отримували раніше, результатом операції природного з'єднання цих відносин буде таблиця такого виду: r3(S3) ≔ r1(S1) xr2(S2):
А результатом внутрішньої сполуки цих відносин r1(S1) та r2(S2) за умовою P = (b1 = b2) буде наступна таблиця: r4(S4) ≔ r1(S1) х P r2(S2):
Порівняємо ці два результати, що вийшли нові відносини r3(S3) та r4(S4). Зрозуміло, що операція природної сполуки виражається через операцію внутрішньої сполуки, але, що головне, з умовою сполуки спеціального виду. Запишемо математичну формулу, що описує дію операції природної сполуки як похідну операції внутрішньої сполуки. r1(S1) xr2(S2) = { ρ <ϕ1> r1 x E ρ< ϕ2>r2}[S1 ∪ S2], де E - умова з'єднання кортежів; E= ∀a ∈S1 ∩ S2 [IsNull (b1) & IsNull (2) ∪b1 = b2]; b1 = ϕ1 (name(a)), b2 = ϕ2 (name(a)); Тут одна з функцій перейменування ϕ1 є тотожною, а інша функція перейменування (а саме - ϕ2) перейменовує атрибути, у яких наші схеми перетинаються. Умова з'єднання E для кортежів записується в загальному вигляді з урахуванням можливих появ Null-значень, адже операція внутрішнього з'єднання (як уже було сказано вище) є похідною операцією від операції декартового твору двох відносин і унарної операції вибірки. 6. Вирази реляційної алгебри Покажемо, як можна використовувати розглянуті раніше вирази та операції реляційної алгебри у практичній експлуатації різних баз даних. Нехай, наприклад, у нашому розпорядженні є фрагмент якоїсь комерційної бази даних: Постачальники (код постачальника, Ім'я постачальника, Місто постачальника); Інструменти (Код інструменту, Ім'я інструменту,...); Постачання (код постачальника, Код деталі); Підкреслені імена атрибутів є ключовими (тобто ідентифікаційними) атрибутами, причому кожен у своєму відношенні. Припустимо, що до нас, як розробникам цієї бази даних та зберігачам інформації з цього питання, надійшло замовлення отримати найменування постачальників (Ім'я Постачальника) та місце їх розташування (Місто Постачальника) у разі, коли ці постачальники не постачають будь-яких інструментів із родовим ім'ям "Плоскогубці". Щоб у нашій, можливо, досить широкій базі даних визначити всіх постачальників, що відповідають цій вимогі, запишемо кілька виразів реляційної алгебри. 1. утворюємо природне з'єднання відносин " Постачальники " і " Постачання " у тому, щоб зіставити з кожним постачальником коди поставляються їм деталей. Нове відношення - результат застосування операції природної сполуки - для зручності подальшого застосування позначимо через r1. Постачальники x Постачання ≔ r1 (Код постачальника, Ім'я постачальника, Місто постачальника, У дужках ми перерахували всі атрибути відносин, що у цій операції природного з'єднання. Ми бачимо, що атрибут "Код постачальника" дублюється, але в підсумковому записі операції кожне ім'я атрибута має бути тільки один раз, тобто: Постачальники x Постачання ≔ r1 (Код постачальника, Ім'я постачальника, Місто постачальника, Код інструменту); 2. знову утворюємо природне з'єднання, тільки на цей раз відносини, що вийшло в пункті один і відносини Інструменти. Робимо це для того, щоб з кожним кодом інструмента, що вийшов у попередньому пункті, - зіставити ім'я цього інструмента. r1 x Інструменти [Код інструменту, Ім'я інструменту] ≔ r2 (Код постачальника, Ім'я постачальника, Місто постачальника, Результат, що вийшов, позначимо r2, що дублюються атрибути виключаємо: r1 x Інструменти [Код інструменту, Ім'я інструменту] ≔ r2 (Код постачальника, Ім'я постачальника, Місто постачальника, Код інструменту, Ім'я інструменту); Зауважимо, що з відношення Інструменти ми беремо лише два атрибути: "Код інструменту" та "Ім'я інструменту". Щоб це здійснити ми, як можна помітити із запису відношення r2, застосували унарну операцію проекції: Інструменти [Код інструменту, Ім'я інструменту], тобто, якби відношення Інструменти було представлено у вигляді таблиці, результатом цієї операції проекції стали б два перші стовпці із заголовками відповідно "Код інструменту" та "Ім'я інструменту" ". Цікаво зауважити, що два перші кроки, нами вже розглянуті, є досить загальними, тобто вони можуть бути використані і для реалізації будь-яких інших запитів. А ось два наступні пункти, у свою чергу, є конкретними кроками для досягнення поставленого перед нами конкретного завдання. 3. Напишемо унарну операцію вибірки за умовою <"Ім'я інструмента" = "Плоскогубці"> стосовно r2отриманому в попередньому пункті. А до результату цієї операції застосуємо, у свою чергу, унарну операцію проекції [Код постачальника, Ім'я постачальника, Місто постачальника] для того, щоб отримати всі значення цих атрибутів, тому що саме цю інформацію нам і потрібно отримати виходячи із замовлення. Отже: (σ<Ім'я інструменту = "Плоскогубці"> r2) [Код постачальника, Ім'я постачальника, Місто постачальника] ≔ r3 (Код постачальника, Ім'я постачальника, Місто постачальника, Код інструменту, Ім'я інструмента). У результуючому відношенні, позначеному через r3, виявилися лише ті постачальники (з усіма своїми розпізнавальними даними), які постачають інструменти з родовим ім'ям "Плоскогубці". Але нам через замовлення необхідно виділити тих постачальників, які, навпаки, не поставляють таких інструментів. Тому перейдемо до наступної дії нашого алгоритму і запишемо останнє вираження реляційної алгебри, яке дасть нам потрібну інформацію. 4. Спочатку складемо різницю відносини "Постачальники" та відносини r3, а після застосування цієї бінарної операції застосуємо унарну операцію проекції на атрибути "Ім'я постачальника" та "Місто постачальника". (Постачальники \ r3) [Ім'я постачальника, Місто постачальника] ≔ r4 (Код постачальника, Ім'я постачальника, Місто постачальника); Результат позначили r4, у це ставлення і увійшли саме ті кортежі вихідного відношення "Постачальники", які відповідають умові нашого замовлення. Отже, ми показали, як можна за допомогою виразів та операцій реляційної алгебри здійснювати всілякі дії з довільними базами даних, виконувати різні замовлення тощо. Лекція №6. Мова SQL Дамо спочатку невелику історичну довідку. Мова SQL, призначений для взаємодії з базами даних, з'явилася в середині 1970-х років. (перші публікації датуються 1974) і був розроблений в компанії IBM в рамках проекту експериментальної реляційної системи управління базами даних. Вихідна назва мови - SEQUEL (Structured English Query Language) - лише частково відбивало суть цієї мови. Спочатку, відразу після його винаходу та в первинний період експлуатації мови SQL, його назва була абревіатурою від словосполучення Structured Query Language, що перекладається як "Мова структурованих запитів". Звичайно, мова була орієнтована головним чином на зручне і зрозуміле користувачам формулювання запитів до реляційних баз даних. Але, насправді, він майже з самого початку був повною мовою баз даних, що забезпечує, крім засобів формулювання запитів та маніпулювання базами даних, такі можливості: 1) засоби визначення та маніпулювання схемою бази даних; 2) засоби визначення обмежень цілісності та тригерів (про які буде згадано пізніше); 3) засоби визначення уявлень баз даних; 4) засоби визначення структур фізичного рівня, які підтримують ефективне виконання запитів; 5) засоби авторизації доступу до відносин та їх полів. У мові були відсутні засоби явної синхронізації доступу до об'єктів баз даних із боку паралельно виконуваних транзакцій: від початку передбачалося, що синхронізацію неявно виконує система управління базами даних. В даний час SQL – це вже не абревіатура, а назва самостійної мови. Також в даний час мова структурованих запитів реалізована у всіх комерційних реляційних системах управління базами даних та майже у всіх СУБД, які спочатку ґрунтувалися не на реляційному підході. Всі компанії-виробники проголошують відповідність реалізації стандарту SQL, і насправді реалізовані діалекти мови структурованих запитів дуже близькі. Цього вдалося досягти не відразу. Особливістю більшості сучасних комерційних систем управління базами даних, що ускладнює порівняння існуючих діалектів SQL, є одноманітного опису мови. Зазвичай опис розкиданий по різних посібниках і перемішаний з описом специфічних для даної системи мовних засобів, які не мають прямого відношення до мови структурованих запитів. Проте можна сказати, що базовий набір операторів SQL, що включає оператори визначення схеми баз даних, вибірки та маніпулювання даними, авторизації доступу до даних, підтримки вбудовування SQL у мови програмування та оператори динамічного SQL, у комерційних реалізаціях устоявся і більш-менш відповідає стандарту . З часом та роботи над мовою структурованих запитів вдалося досягти стандарту чіткої стандартизації синтаксису та семантики операторів вибірки даних, маніпулювання даними та фіксації засобів обмеження цілісності баз даних. Були специфіковані засоби визначення первинного і зовнішніх ключів відносин і про перевірочних обмежень цілісності, які є підмножина негайно перевіряються обмежень цілісності SQL. Засоби визначення зовнішніх ключів дозволяють легко формулювати вимоги так званої цілісності посилань баз даних (про яку ми поговоримо пізніше). Це поширене в реляційних базах даних вимога можна було сформулювати і основі загального механізму обмежень цілісності SQL, але формулювання з урахуванням поняття зовнішнього ключа простіша і зрозуміла. Отже, з огляду на все це в даний час мова структурованих запитів - це назва не просто однієї мови, а назва цілого класу мов, оскільки, незважаючи на наявні стандарти, в різних системах управління базами даних реалізуються різні діалекти мови структурованих запитів, що мають, зрозуміло, одну загальну основу. 1. Оператор Select – базовий оператор мови структурованих запитів Центральне місце у мові структурованих запитів SQL займає оператор Select, з допомогою якого реалізується найзатребуваніша операція під час роботи з базами даних - запити. Оператор Select здійснює обчислення виразів як реляційної, і псевдореляційної алгебри. В даному курсі ми розглянемо реалізацію тільки вже пройдених нами унарних та бінарних операцій реляційної алгебри, а також здійснення запитів за допомогою так званих підзапитів. До речі, слід зазначити, що у разі роботи з операціями реляційної алгебри в результуючих відносинах можуть з'являтися дублюючі кортежі. У правилах мови структурованих запитів немає суворої заборони на присутність рядків у відносинах, що повторюються (на відміну від звичайної реляційної алгебри), тому виключати дублікати з результату не обов'язково. Отже, розглянемо базову структуру оператора Select. Вона досить проста і включає наступні стандартні обов'язкові фрази: Виберіть ... Від ... Where... ; На місці крапки в кожному рядку повинні стояти відносини, атрибути та умови конкретної бази даних та завдання до неї. У загальному випадку базова структура Select має виглядати так: Select вибрати такі атрибути Від з таких відносин де з такими умовами вибірки кортежів Таким чином, вибираємо ми атрибути зі схеми відносин (заголовки деяких стовпців), при цьому вказуючи, з яких відносин (а їх, очевидно, може бути кілька) ми робимо нашу вибірку і, нарешті, на підставі яких умов ми зупиняємо свій вибір на тих чи інших кортежах. Важливо зауважити, що посилання на атрибути відбуваються за допомогою їхніх імен. Таким чином, виходить наступний алгоритм роботи цього базового оператора Select: 1) запам'ятовуються умови вибірки кортежів із відношення; 2) перевіряється, які кортежі задовольняють зазначеним властивостям. Такі кортежі запам'ятовуються; 3) на вихід виводяться перелічені у першому рядку базової структури оператора Select атрибути зі своїми значеннями. (Якщо говорити про табличній формі запису відносини, то виведуть ті стовпці таблиці, заголовки яких було перераховано як необхідні атрибути; зрозуміло, стовпці виведуть в повному обсязі, у кожному їх залишаться ті кортежі, які задовольнили названим умовам.) Розглянемо приклад. Нехай нам дано таке відношення r1як фрагмент якоїсь бази даних книгарні:
Нехай також нам дано наступний вираз із оператором Select: Select Назва книги, Автор книги Від r1 де Ціна книги > 200; Результатом цього оператора буде наступний фрагмент кортежу: (Мобільник, С. Кінг). (Надалі ми розглянемо безліч прикладів реалізації запитів з використанням цієї базової структури і її застосування вивчимо дуже докладно.) 2. Унарні операції мовою структурованих запитів У цьому параграфі ми розглянемо, як реалізуються мовою структурованих запитів за допомогою оператора Select вже знайомі нам унарні операції вибірки, проекції та перейменування. Важливо зауважити, що коли ми могли працювати тільки з окремими операціями, то навіть один оператор Select у загальному випадку дозволяє визначити ціле вираження реляційної алгебри, а не якусь одну операцію. Отже, перейдемо безпосередньо до аналізу подання унарних операцій мовою структурованих запитів. 1. Операція вибірки. Операція вибірки мовою SQL реалізується оператором Select наступного виду: Select усі атрибути Від ім'я відносини де умова вибірки; Тут замість того, щоб писати всі атрибути, можна використовувати значок *. Теоретично мови структурованих запитів цей значок означає вибір всіх атрибутів зі схеми відносини. Умова вибірки тут (і у решті реалізаціях операцій) записується як логічного висловлювання зі стандартними зв'язками not (не), and (і), or (чи). На атрибути відносини посилаємось за допомогою їхніх імен. Розглянемо приклад. Визначимо таку схему відношення: Успішність (№ залікової книжки, Семестр, Код предмета, Оцінка, Дата); Тут, як згадувалося раніше, підкреслені атрибути утворюють ключ відносини. Складемо оператор Select наступного виду, що реалізує унарну операцію вибірки: Select * From Успішність Where № залікової книжки = 100 and Семестр = 6; Зрозуміло, що результат цього оператора машина виведе успішність студента з номером заліковки сто за шостий семестр. 2. Операція проекції. Операція проекції мовою структурованих запитів реалізується навіть простіше, ніж операція вибірки. Нагадаємо, що при застосуванні операції проекції вибираються не рядки (як при застосуванні операції вибірки), а стовпці. Тому достатньо перерахувати заголовки необхідних стовпців (тобто імена атрибутів), без зазначення будь-яких сторонніх умов. Отже, отримуємо оператор наступного виду: Select список імен атрибутів Від ім'я відношення; Після застосування цього оператора машина видасть ті стовпці таблиці-відносини, імена яких були вказані в першому рядку цього оператора Select. Як ми вже згадували раніше, рядки, що повторюються, і стовпці виключати з результуючого відношення не обов'язково. Але якщо в замовленні або в завдання потрібно обов'язково елімінувати дублікати, слід використовувати спеціальну опцію мови структурованих запитів - чіткий. Ця опція задає автоматичне виключення дублікатів кортежів із відношення. Із застосуванням цієї опції оператор Select виглядатиме так: Select distinct список імен атрибутів Від ім'я відношення; У мові SQL існує спеціальне позначення для необов'язкових виразів - квадратні дужки [...]. Тому в найзагальнішому вигляді операція проекції виглядатиме так: Select [distinct] список імен атрибутів Від ім'я відношення; Однак якщо результат застосування операції гарантовано не містить дублікатів або дублікати все-таки допустимі, то опцію чіткий краще не вказувати, щоб не захаращувати запис, тобто з міркувань продуктивності роботи оператора. Розглянемо приклад, що ілюструє можливість стовідсоткової впевненості у відсутності дублікатів. Нехай дана вже відома нам схема відносин: Успішність (№ залікової книжки, Семестр, Код предмета, Оцінка, Дата). Нехай даний оператор Select: Select № залікової книжки, Семестр, Код предмета Від Успішність; Тут, як легко бачити, три атрибути, що повертаються оператором, утворюють ключ відношення. Саме тому опція чіткий стає зайвою, адже дублікатів гарантовано не буде. Це випливає з вимоги, що накладається на ключі, що називається обмеженням унікальності. Докладніше цю властивість ми розглянемо далі, але якщо атрибут ключовий, то дублікатів у ньому немає. 3. Операція перейменування. Операція перейменування атрибутів мовою структурованих запитів здійснюється досить легко. А саме втілюється насправді наступним алгоритмом: 1) у списку імен атрибутів фрази Select перераховуються атрибути, які необхідно перейменувати; 2) до кожного вказаного атрибуту додається спеціальне ключове слово as; 3) після кожного входження слова as вказується те ім'я відповідного атрибута, на яке необхідно змінити вихідне ім'я. Таким чином, з урахуванням всього вищесказаного, оператор, відповідний операції перейменування атрибутів, буде виглядати так: Select ім'я атрибута 1 як нове ім'я атрибута 1,... Від ім'я відношення; Покажемо роботу цього оператора з прикладу. Нехай дана вже знайома нам схема відношення: Успішність (№ залікової книжки, Семестр, Код предмета, Оцінка, Дата); Нехай ми маємо замовлення поміняти імена деяких атрибутів, а саме замість "№ залікової книжки" має стояти "№ заліковки" і замість "Оцінка" - "Балл". Запишемо, як виглядатиме оператор Select, який реалізує цю операцію перейменування: Select залікової книжки as № заліковки, Семестр, Код предмета, Оцінка as Бал, Дата Від Успішність; Таким чином, результатом застосування цього оператора буде нова схема відношення, що відрізняється від вихідної схеми відношення "Успішність" іменами двох атрибутів. 3. Бінарні операції мовою структурованих запитів Як і унарні операції, операції бінарні також мають свою реалізацію мовою структурованих запитів або SQL. Отже, розглянемо здійснення цією мовою вже пройдених нами бінарних операцій, а саме - операцій об'єднання, перетину, різниці, декартового твору, природної сполуки, внутрішньої та лівої, правої, повної зовнішньої сполуки. 1. Операція об'єднання. Щоб реалізувати операцію об'єднання двох відносин доводиться використовувати одночасно два оператора Select, кожен із яких відповідає якомусь одному з вихідних відносин-операндов. І до цих двох базових операторів Select необхідно застосувати спеціальну операцію Union. Враховуючи все сказане вище, запишемо, як же операція об'єднання виглядатиме з використанням семантики мови структурованих запитів: Select список імен атрибутів відносини 1 Від ім'я відносини 1 Union Select список імен атрибутів відносини 2 Від ім'я відношення 2; Важливо зауважити, що списки імен атрибутів двох відносин, що об'єднуються, повинні посилатися на атрибути сумісних типів і бути перераховані в узгодженому порядку. Якщо цієї вимоги не дотримуватись, ваш запит не зможе бути виконаний, і комп'ютер видасть повідомлення про помилку. Але, що цікаво відзначити, самі імена атрибутів у цих відносинах можуть бути різними. У такому разі результуючому відношенню приписуються імена атрибутів, зазначені у першому операторі Select. Також необхідно знати, що використання операції Union передбачає автоматичне виключення із результуючого відношення всіх дублікатів кортежів. Тому, якщо вам потрібно, щоб всі рядки, що повторюються, в кінцевому результаті збереглися, замість операції Union слід застосовувати модифікацію цієї операції - операцію Союз ус. У такому разі операція об'єднання двох відносин виглядатиме так: Select список імен атрибутів відносини 1 Від ім'я відносини 1 Союз ус Select список імен атрибутів відносини 2 Від ім'я відношення 2; У цьому випадку з результуючого відношення дублікати кортежів не видалятимуться. Використовуючи згадуване раніше позначення для необов'язкових елементів та опцій в операторах Select, запишемо найзагальніший вид операції об'єднання двох відносин мовою структурованих запитів: Select список імен атрибутів відносини 1 Від ім'я відносини 1 Union [All] Select список імен атрибутів відносини 2 Від ім'я відношення 2; 2. Операція перетину. Операція перетину та операція різниці двох відносин мовою структурованих запитів реалізуються схожим чином (ми розглядаємо найпростіший спосіб уявлення, оскільки, чим простіше метод, тим економічніше, актуальніше і, отже, найбільш затребуваний). Отже, ми розберемо спосіб реалізації операції перетину з використанням ключів. Цей спосіб передбачає участь двох конструкцій Select, але вони не рівноправні (як у поданні операції об'єднання), одна з них є "підконструкцією", "підциклом". Такий оператор зазвичай називають підзапитом. Отже, нехай ми маємо дві схеми відносин (R1 і R2), приблизно визначені таким чином: R1 (ключ,...) та R2 (Ключ, ...); Скористаємося також під час запису цієї операції спеціальною опцією in, Що буквально означає "в" або (як у даному конкретному випадку) "міститься в". Отже, з урахуванням всього вищесказаного, операція перетину двох відносин за допомогою мови структурованих запитів запишеться так: Select * Від R1 де ключ in (Select ключ від R2); Таким чином, ми бачимо, що підзапитом у цьому випадку буде оператор у круглих дужках. Цей підзапит у нашому випадку повертає список значень ключа відношення R2. І, як випливає з нашого запису операторів, з аналізу умови вибірки, в результуюче відношення потраплять тільки ті кортежі відносини R1, ключ яких міститься у списку ключів відношення R2. Тобто у підсумковому відношенні, якщо згадати визначення перетину двох відносин, залишаться лише ті кортежі, які належать обом відносинам. 3. Операція різниці. Як було зазначено раніше, унарная операція різниці двох відносин реалізується аналогічно операції перетину. Тут також крім головного запиту з оператором Select використовується другий, допоміжний запит - так званий підзапит. Але на відміну від втілення в життя попередньої операції, при реалізації різниці операції необхідно використовувати інше ключове слово, а саме не в, Що в дослівному перекладі означає "не в" або (як доречно перекласти в нашому випадку) - "не міститься в". Отже, нехай, як і в попередньому прикладі, ми маємо дві схеми відносин (R1 і R2), приблизно задані: R1 (ключ,...) та R2 (Ключ, ...); Як бачимо, серед атрибутів цих відносин знову задано ключові атрибути. Таким чином, отримуємо наступний вид для подання у мові структурованих запитів операції різниці: Select * Від R1 де ключ не в (Select ключ Від R2); Таким чином, в результуюче ставлення вибираються ті кортежі відношення R1, ключ яких не міститься у списку ключів відношення R2. Якщо розглядати запис буквально, то справді виходить, що із відношення R1 "відняли" відношення R2. Звідси робимо висновок, що умова вибірки у цьому операторі записано правильно (адже визначення різниці двох відносин виконується) та використання ключів, як і у разі реалізації операції перетину, цілком виправдано. Два випадки застосування "методу ключів", які ми розглянули, є найпоширенішими. На цьому вивчення використання ключів у складанні операторів, які представляють відносини, завершимо. Усі бінарні операції реляційної алгебри, що залишилися, записуються іншими способами. 4. Операція декартового твору Як ми пам'ятаємо з попередніх лекцій, декартове твір двох відносин-операндів складається як набір всіх можливих пар іменованих значень кортежів на атрибутах. Тому мовою структурованих запитів операція декартового твору реалізується за допомогою перехресного з'єднання, яке позначається ключовим словом cross joinщо буквально і перекладається "перехресне об'єднання" або "перехресне з'єднання". Оператор Select у конструкції, що представляє операцію декартового твору мовою структурованих запитів, присутній тільки один і має такий вигляд: Select * Від R1 cross join R2 Тут R1 і R2 - Імена вихідних відносин-операндів. Опція cross join забезпечує, що в результуюче ставлення запишуться всі атрибути (все, тому що в першому рядку оператора поставлено значок "*"), що відповідають усім парам кортежів відносин R1 і R2. Дуже важливо пам'ятати одну особливість втілення в життя операції декартового твору. Ця особливість є наслідком визначення бінарної операції декартового твору. Нагадаємо його: r4(S4) = r1(S1) xr2(S2) = {t(S1 ∪ S2) | t[S1] ∈ r1 & t(S2) ∈ r2}, S1 ∩ S2= ∅; Як видно з наведеного визначення, пари кортежів утворюються при обов'язково непересічних схемах відносин. Тому й під час роботи мовою структурованих запитів SQL обов'язково обумовлюється, що вихідні відносини-операнди нічого не винні мати збігаються імен атрибутів. Але якщо ці відносини все ж мають однакові імена, ситуацію можна легко вирішити за допомогою операції перейменування атрибутів, тобто в подібних випадках необхідно просто використовувати опцію as, Про яку згадувалося раніше. Розглянемо приклад, де потрібно знайти декартово твір двох відносин, мають деякі імена своїх атрибутів збігаються. Отже, нехай дані такі відносини: R1 (A, B), R2 (B, C); Ми бачимо, що атрибути R1.B і R2.B мають однакові імена. З урахуванням цього оператор Select, що реалізує мовою структурованих запитів цю операцію декартового твору, виглядатиме так: Select А, R1.B as B1, R2.B as B2, C Від R1 cross join R2; Таким чином, з використанням опції перейменування as, у машини не виникне "питань", з приводу імен двох вихідних відносин-операндів, що збігаються. 5. Операції внутрішньої сполуки На перший погляд може здатися дивним, що ми розглядаємо операцію внутрішньої сполуки раніше операції природної сполуки, адже коли ми проходили бінарні операції, все було навпаки. Але аналізуючи вираз операцій мовою структурованих запитів, можна дійти висновку, що операція природного з'єднання є окремим випадком операції внутрішньої сполуки. Саме тому раціонально розглянути ці операції якраз у такому порядку. Отже, спочатку згадаємо визначення операції внутрішнього з'єднання, яке ми проходили раніше: r1(S1) х P r2(S2) = σ (r1 xr2), вул1 ∩ S2 = ∅. Для нас у цьому визначенні особливо важливо те, що схеми відносин-операндів S1 і S2 не повинні перетинатися. Для реалізації операції внутрішнього з'єднання у мові структурованих запитів існує спеціальна опція inner joinяка перекладається з англійської буквально "внутрішнє об'єднання" або "внутрішнє з'єднання". Оператор Select у разі здійснення операції внутрішнього з'єднання буде виглядати так: Select * Від R1 inner join R2; Тут, як і раніше, R1 і R2 - Імена вихідних відносин-операндів. При реалізації цієї операції не можна допускати перетину схем відносин-операндів. 6. Операція природного з'єднання Як ми вже говорили, операція природного з'єднання є окремим випадком операції внутрішнього з'єднання. Чому? Та тому, що при дії природного з'єднання кортежі вихідних відносин-операндів з'єднуються за особливою умовою. А саме за умовою рівності кортежів на перетині відносин-операндів, тоді як за дії операції внутрішньої сполуки такої ситуації допускати було б не можна. Оскільки операція природного з'єднання, що розглядається нами, є окремим випадком операції внутрішньої сполуки, для її реалізації використовується та ж опція, що і для попередньої розглянутої операції, тобто опція inner join. Але оскільки при складанні оператора Select для операції природного з'єднання необхідно ще врахувати умову рівності кортежів вихідних відносин-операндів на перетині їх схем, додатково до зазначеної опції застосовується ключове слово on. У перекладі з англійської, це буквально означає "на", а стосовно нашого сенсу, можна перекласти як "за умови". Загальний вигляд оператора Select для виконання операції природного з'єднання наступний: Select * Від ім'я відносини 1 inner join ім'я відносини 2 on умова рівності кортежів; Розглянемо приклад. Нехай дані два відносини: R1 (A, B, C), R2 (B, C, D); Операцію природного з'єднання цих відносин можна реалізувати за допомогою наступного оператора: Select А, R1.B, R1.C, D Від R1 inner join R2 on R1.B = R2.B and R1.C = R2.C В результаті цієї операції в результат виведуть атрибути, вказані в першому рядку оператора Select, що відповідають кортежам, рівним на вказаному перетині. Слід зазначити, що тут ми звертаємося до загальних атрибутів В і С не просто на ім'я. Це потрібно робити не з тієї причини, що й у разі реалізації операції декартового твору, а тому, що в іншому випадку буде не зрозуміло, до якого ставлення вони належать. Цікаво, що використане формулювання умови з'єднання (R1.B = R2.B and R1.C = R2.C) передбачає, що загальні атрибути сполучених відносин Null-значень не допускають. Це спочатку вбудовано у систему мови структурованих запитів. 7. Операція лівого зовнішнього з'єднання Вираз мовою структурованих запитів SQL операції лівого зовнішнього з'єднання виходить із реалізації операції природного з'єднання заміною ключового слова внутрішній на ключове слово left outer. Таким чином, мовою структурованих запитів ця операція запишеться так: Select * Від ім'я відносини 1 left outer join ім'я відносини 2 on умова рівності кортежів; 8. Операція правого зовнішнього з'єднання Вираз для операції правого зовнішнього з'єднання мовою структурованих запитів виходить із здійснення операції природного з'єднання заміною ключового слова внутрішній на ключове слово right outer. Отже, отримуємо, що мовою структурованих запитів SQL операція правого зовнішнього з'єднання запишеться так: Select * Від ім'я відносини 1 right outer join ім'я відносини 2 on умова рівності кортежів; 9. Операція повного зовнішнього з'єднання Вираз мовою структурованих запитів операції повного зовнішнього з'єднання виходить, як й у попередніх випадках, з висловлювання для операції природного з'єднання шляхом заміни ключового слова внутрішній на ключове слово full outer. Таким чином, мовою структурованих запитів ця операція запишеться так: Select * Від ім'я відносини 1 full outer join ім'я відносини 2 on умова рівності кортежів; Дуже зручно, що в семантику мови структурованих запитів SQL спочатку вбудовані ці опції, адже інакше кожному програмісту доводилося виводити їх самостійно і вводити в кожну нову базу даних. 4. Використання підзапитів Як можна було зрозуміти з пройденого матеріалу, поняття "підзапит" у мові структурованих запитів є поняттям базовим і досить широко застосовним (іноді, до речі, їх ще називають SQL-запитами. Дійсно, практика програмування та роботи з базами даних показує, що складання системи підзапитів Для вирішення різних супутніх завдань - діяльність набагато більш вдячна порівняно з іншими прийомами роботи зі структурованою інформацією, тому розглянемо приклад для кращого розуміння дій з підзапитами, їх складанням і використанням. Нехай є наступний фрагмент якоїсь бази даних, яка цілком може використовуватись у якомусь навчальному закладі: Предмети (Код предмета, ім'я предмета); Студенти (№ залікової книжки, Прізвище ім'я по батькові); Сесія (Код предмета № залікової книжки, оцінка); Сформулюємо SQL-запит, який повертає відомості із зазначенням номера залікової книжки, прізвища та ініціалів студента та оцінки для предмета з найменуванням "Бази даних". Таку інформацію в університетах необхідно отримувати завжди і своєчасно, тому наведений далі запит є чи не найбільш затребуваною одиницею програмування з використанням таких баз даних. Для зручності роботи, припустимо, що атрибути "Прізвище", "Ім'я" та "По батькові" не допускають Null-значень і не є порожніми. Ця вимога цілком зрозуміла і закономірна, адже в базу даних будь-якого навчального закладу першими з даних нового учня вводяться саме дані про його прізвище, ім'я та по батькові. І зрозуміло, що не може бути запису в подібній базі даних, в якій присутні дані на учня, але при цьому невідомо його ім'я. Зауважимо, що атрибут "Ім'я предмета" схеми відношення "Предмети" є ключем, тому, як випливає з визначення (докладніше про це буде сказано далі), найменування предметів є унікальними. Це теж зрозуміло і без пояснення уявлення ключа, адже всі предмети, що викладаються в навчальному закладі, повинні мати і мають різні імена. Тепер, перш ніж ми приступимо до складання тексту самого оператора, введемо до розгляду дві функції, які стануть нам у нагоді в міру нашої діяльності. По-перше, нам буде корисна функція Оздоблення, записується Trim ("рядок"), тобто аргументом цієї функції є рядок. Що робить ця функція? Вони повертають сам аргумент без прогалин, що стоять на початку і в кінці цього рядка, тобто, цю функцію застосовують, наприклад, у випадках: Trim ("Богучарників") або Trim ("Максиме-єнко"), коли після або до аргументи стоять за кілька зайвих прогалин. А по-друге, необхідно також розглянути функцію Left, яка записується Left (рядок, число), тобто функцію від двох аргументів, одним з яких є, як і раніше, рядок. Другий її аргумент - число, воно показує скільки символів з лівої частини рядка слід вивести в результат. Наприклад, результатом операції: Left ("Михайло, 1") + "." + Left ("Зіновійович, 1") будуть ініціали "М. З.". Саме для виведення ініціалів студентів ми будемо використовувати цю функцію в нашому запиті. Отже, почнемо складання шуканого запиту. Для початку складемо невеликий допоміжний запит, який потім використовуємо в основному, головному запиті: Select № залікової книжки, Оцінка Від сесія де Код предмета = (Select Код предмета Від предмети де Ім'я предмета = "Бази даних") as "Оцінки „Бази даних"; Застосування тут опції as означає, що ми надали цьому запиту псевдонім "Оцінки „Бази даних". Зробили ми це для зручності подальшої роботи із цим запитом. Далі, у цьому запиті підзапит: Select Код предмета Від предмети де Ім'я предмета = "Бази даних"; дозволяє виділити з відношення "Сесія" ті кортежі, які відносяться до предмета, що розглядається, тобто до баз даних. Цікаво, що це внутрішній підзапит може повертати трохи більше значення, оскільки атрибут " Ім'я предмета " є ключем відносини " Предмети " , т. е. всі його значення унікальні. А весь запит "Оцінки „Бази даних" дозволяє виділити зі стосунку "Сесія" дані про тих студентів (їх номери залікових книжок та оцінки), які задовольняють умову, обумовлену в підзапиті, тобто інформацію про предмет під назвою "База даних" . Тепер складемо основний запит, використовуючи вже отримані результати. Select Студенти. № залікової книжки, Оздоблення (Прізвище) + Ліве (Ім'я, 1) + "." + Ліве (По батькові, 1) + "."as ПІБ, Оцінки "Бази даних". Оцінка Від студенти inner join ( Select № залікової книжки, Оцінка Від сесія де Код предмета = (Select Код предмета Від предмети де Ім'я предмета = "Бази даних") ) як "Оцінки „Бази даних". on Студенти. № залікової книжки = Оцінки " Бази даних " . № залікової книжки. Отже, спочатку ми перераховуємо атрибути, які необхідно вивести, після закінчення роботи запиту. Необхідно згадати, що атрибут "№ залікової книжки" з відношення Студенти, звідти ж - атрибути "Прізвище", "Ім'я" та "По батькові". Щоправда, два останні атрибути виводимо не повністю, а лише перші літери. Також ми згадуємо атрибут "Оцінка" із запиту Оцінки "Бази даних", яке ввели раніше. Вибираємо всі ці атрибути з внутрішнього з'єднання відносини "Студенти" та запиту "Оцінки „Бази даних". Це внутрішнє з'єднання, як ми бачимо, береться нами за умовою рівності номерів залікової книжки. В результаті цієї операції внутрішнього з'єднання, до "Студенти" додаються оцінки. Слід зазначити, що оскільки атрибути "Прізвище", "Ім'я" та "По батькові" за умовою не допускають Null-значень і не є порожніми, то формула обчислення, що повертає атрибут "ПІБ" (Оздоблення (Прізвище) + Ліве (Ім'я, 1) + "." + Ліве (По батькові, 1) + "."as ПІБ), відповідно не вимагає додаткових перевірок, спрощується. Лекція №7. Як ми вже знаємо, бази даних - це своєрідний контейнер, основне призначення якого полягає в зберіганні даних, представлених у вигляді відносин. Необхідно знати, що залежно від своєї природи та структури, відносини поділяються на: 1) базові відносини; 2) віртуальні відносини. Відносини базового виду містять лише незалежні дані і не можуть бути виражені через будь-які інші відносини баз даних. У комерційних системах управління базами даних базові відносини зазвичай називаються просто таблицями на відміну уявлень, відповідних поняттю віртуальних відносин. У цьому курсі ми будемо докладно розглядати лише базові відносини, основні прийоми та принципи роботи з ними. 1. Базові типи даних Типи даних, як і відносини, поділяються на базові и віртуальні. (Про віртуальні типи даних ми поговоримо трохи пізніше, присвятимо цій темі окрему главу.) Базові типи даних - це будь-які типи даних, задані в системах управління базами даних спочатку, тобто присутні там за замовчуванням (на відміну від типу користувача даних, який ми проаналізуємо відразу після проходження типу даних базового). Перш ніж перейти до розгляду власне базових типів даних, перерахуємо, яких типів дані взагалі бувають: 1) числові дані; 2) логічні дані; 3) рядкові дані; 4) дані, що визначають дату та час; 5) ідентифікаційні дані. У системах управління базами даних за умовчанням запровадили кілька найпоширеніших типів даних, кожен із яких належить якомусь із перелічених типів даних. Назвемо їх. 1. В числовому тип даних виділяють: 1) Integer. Цим ключовим словом зазвичай означає цілий тип даних; 2) Real, відповідний речовому типу даних; 3) Decimal (n, m). Це десятковий тип даних. Причому в позначенні n - це число, що фіксує загальну кількість знаків числа, а m показує скільки символів з них коштує після десяткової точки; 4) Money або Currency, введений спеціально для зручного представлення даних грошового типу даних. 2. В логічному Тип даних зазвичай виділяють тільки один базовий тип, це Logical. 3. Рядковий тип даних налічує чотири базові типи (маються на увазі, зрозуміло, найбільш поширені): 1) Bit(n). Це рядки біт із фіксованою довжиною n; 2) Varbit(n). Це теж рядки біт, але зі змінною довжиною, що не перевищує n біт; 3) Char (n). Це рядки символів із постійною довжиною n; 4) Varchar (n). Це рядки символів, зі змінною довжиною, що не перевищує n символів. 4. Тип дата і час включає наступні базові типи даних: 1) Date – тип даних дати; 2) Time – тип даних, що виражають час доби; 3) Date-time - тип даних, що виражає одночасно і дату, і час. 5. Ідентифікаційний Тип даних містить лише один включений за умовчанням в систему управління базами даних тип, і це GUID (глобальний унікальний ідентифікатор). Необхідно зауважити, що всі базові типи даних можуть мати варіанти різного діапазону подання даних. Наведемо приклад: варіантами чотирибайтового типу даних integer можуть бути восьмибайтові (bigint) та двобайтові (smallint) типи даних. Поговоримо окремо про базовий тип даних GUID. Цей тип призначений для зберігання шістнадцятибайтових значень так званого глобального унікального ідентифікатора. Усі різні значення цього ідентифікатора генеруються автоматично при виклику спеціальної вбудованої функції NewId(). Це позначення походить від повного англійського словосполучення New Identification, що в перекладі буквально означає "нове значення ідентифікатора". Кожне значення ідентифікатора, що генерується на конкретному комп'ютері, унікально в межах всіх вироблених комп'ютерів. GUID-ідентифікатор використовується, зокрема, для організації реплікації баз даних, тобто при створенні копій якихось наявних баз даних. Такі ідентифікатори GUID можуть бути використані і розробниками баз даних нарівні з іншими базовими типами. Проміжне положення між типом GUID та іншими базовими типами займає ще один спеціальний базовий тип - тип лічильника. Для позначення даних цього типу використовується спеціальне ключове слово Counter (x0, ∆x), Що в буквальному перекладі з англійської і означає "лічильник". Параметр x0 задає початкове значення, а Δx - крок збільшення. Значення цього типу Counter обов'язково є цілими. Необхідно відзначити, що робота з цим базовим типом даних включає ряд дуже цікавих особливостей. Наприклад, значення цього типу Counter не задаються, як ми звикли при роботі з іншими типами даних, вони генеруються на вимогу, майже як для значень типу глобального унікального ідентифікатора. Також незвичайно, що тип лічильника може бути заданий лише при визначенні таблиці і лише тоді! У програмному коді цей тип не можна використовувати. Ще потрібно пам'ятати, що і при визначенні таблиці тип лічильника може бути заданий виключно для одного шпальти. Значення даних типу лічильник генеруються автоматично при вставці рядків. Причому ця генерація проводиться без повторень, тому лічильник завжди буде унікально ідентифікувати кожен рядок. Але це створює деякі незручності під час роботи з таблицями, що містять дані типу лічильник. Якщо, наприклад, дані щодо заданому таблицею зміняться і їх доведеться видалити або поміняти місцями, значення лічильника легко можуть "сплутати карти", особливо якщо працює недосвідчений програміст. Наведемо приклад, що ілюструє таку ситуацію. Нехай дана наступна таблиця, що представляє якесь відношення, в яку введено чотири рядки:
Лічильник кожного нового рядка автоматично дав унікальне ім'я. І нехай тепер необхідно видалити другий і четвертий рядки з таблиці, а потім додати один додатковий рядок. Ці операції призведуть до наступного перетворення вихідної таблиці:
Таким чином, лічильник видалив другий і четвертий рядки разом з їх унікальними іменами, а не став "перепривласнювати" їх новим рядкам, як можна було очікувати. Причому змінити вручну значення лічильника система управління базами даних будь-коли дозволить, як і вона дозволить оголосити у одній таблиці кілька лічильників одночасно. Зазвичай лічильник використовується як сурогатний, тобто штучний ключ у таблиці. Цікаво знати, що унікальних значень четирехбайтового лічильника при швидкості генерації одне значення в секунду вистачить більш ніж на 100 років. Покажемо, як це підраховано: 1 рік = 365 днів * 24 год * 60 с * 60 с < 366 днів * 24 год * 60 с * 60 с < 225 с. 1 секунда > 2-25 рік. 24*8 значень / 1 значення/секунду = 232 з > 27 рік> 100 років. 2. Користувальницький тип даних Тип користувача даних відрізняється від усіх базових типів тим, що він не був спочатку вшитий в систему управління базами даних, він не був описаний як тип даних за умовчанням. Цей тип може створити для себе будь-який користувач та програміст баз даних відповідно до власних запитів та вимог. Таким чином, тип користувача даних - це підтип деякого базового типу, тобто це базовий тип з деякими обмеженнями безлічі допустимих значень. У записі на псевдокоді, користувач тип даних створюється за допомогою наступного стандартного оператора: Create subtype ім'я підтипу тип ім'я базового типу As обмеження підтипу; Отже, в першому рядку ми повинні вказати ім'я нашого нового, користувача типу даних, в другому - який з наявних базових типів даних ми взяли за зразок, створюючи власний, і, нарешті, в третій - ті обмеження, які нам необхідно додати до вже наявних обмеження множини значень базового типу даних - зразка. Обмеження підтипу записуються як умова, що залежить від імені підтипу, що визначається. Щоб краще зрозуміти принцип дії оператора Create, розглянемо такий приклад. Нехай нам необхідно створити свій спеціалізований тип даних, наприклад, для роботи на пошті. Це буде тип роботи з даними виду чисел поштового індексу. Від звичайних десяткових шестизначних чисел наші числа відрізнятимуться тим, що вони можуть бути лише позитивними. Запишемо оператор, для створення потрібного нам підтипу: Create subtype Поштовий індекс тип decimal (6, 0) As Поштовий індекс >0. Чому ми взяли саме decimal (6, 0)? Згадуючи звичайний вид індексу, бачимо, що такі числа мають складатися з шести цілих чисел від нуля до дев'яти. Саме тому ми і взяли як базовий тип даних - десятковий тип. Цікаво зауважити, що в загальному випадку умова, що накладається на базовий тип даних, тобто обмеження підтипу, може містити логічні зв'язки not, and, or і взагалі бути будь-якою довільною складністю. Визначені таким чином підтипи даних користувача можуть безперешкодно використовуватися поряд з іншими базовими типами даних і в програмному коді, і при визначенні типів даних у стовпцях таблиці, тобто базові типи даних і користувальницькі при роботі з ними абсолютно рівноправні. У візуальному середовищі розробки з'являються у списках допустимих типів разом з іншими базовими типами даних. Імовірність того, що нам при проектуванні нової власної бази даних може знадобитися недокументований тип даних, досить велика. Адже за умовчанням у систему управління базами даних вшиті лише найзагальніші типи даних, придатні відповідно до вирішення найзагальніших завдань. При складанні предметних баз даних без проектування власних типів даних практично неможливо. Але, що цікаво, з рівною ймовірністю нам може знадобитися і видалити створений нами підтип, щоб не захаращувати та не ускладнювати код. Для цього в системах управління базами даних зазвичай вбудовано спеціальний оператор падіннящо означає "видалити". Загальний вигляд цей оператор видалення непотрібних типів користувача має наступний: Drop subtype ім'я користувача типу; Типи даних користувача, як правило, рекомендується вводити для підтипів досить загального призначення. 3. Значення за умовчанням Системи управління базами даних можуть мати можливість створення будь-яких довільних значень за промовчанням або, як їх ще називають, за замовчуванням. Ця операція в будь-якому середовищі програмування має досить велику вагу, адже практично в будь-якому завданні може виникнути необхідність запровадження констант, незмінних значень за умовчанням. Для створення замовчування в системах управління базами даних використовується вже знайома нам з проходження користувача типу даних функція Створювати. Тільки у разі створення значення за промовчанням використовується також додаткове ключове слово дефолт, що означає " умовчання " . Іншими словами, щоб створити в наявній базі даних значення за промовчанням, необхідно використовувати наступний оператор: Create default ім'я замовчування As константний вираз; Зрозуміло, що на місці константного значення при застосуванні цього оператора потрібно написати значення або вираз, який ми хочемо зробити за замовчуванням значенням або виразом. І, зрозуміло, треба вирішити, під яким ім'ям нам буде зручно його використовувати в нашій базі даних, і записати це ім'я в перший рядок оператора. Необхідно зауважити, що в даному конкретному випадку цей оператор Create відповідає синтаксису мови Transact-SQL, вбудованого в Microsoft SQL Server. Отже, що ми здобули? Ми вивели, що умовчання є іменовану константу, що зберігається в базах даних, як і її об'єкт. У візуальному середовищі розробки за замовчуванням з'являються у списку виділених значень за промовчанням. Наведемо приклад створення умовчання. Нехай для правильної роботи нашої бази даних необхідно, щоб у ній функціонувало значення зі змістом необмеженого терміну дії чогось. Тоді потрібно ввести до списку значень бази даних значення за замовчуванням, що відповідає даній вимогі. Це може бути необхідно хоча б тому, що кожного разу при зустрічі в тексті коду з цим досить громіздким виразом буде незручно виписувати його заново. Саме тому скористаємося зазначеним вище оператором Create для створення замовчування, із змістом необмеженого терміну дії чогось. Create default "термін не обмежений" As ‘9999-12-31 23: 59:59’ Тут також був використаний синтаксис мови Transact-SQL, згідно з яким значення констант типу "дата - час" (в даному випадку '9999-12-31 23: 59:59') записуються як рядки символів певного напрямку. Інтерпретація рядків символів як значень типу "дата - час" визначається контекстом використання цих рядків. Наприклад, у нашому конкретному випадку спочатку в константному рядку записано граничне значення року, а потім часу. Однак при всій своїй корисності замовчування, як і тип користувача даних, іноді теж можуть вимагати того, щоб їх видалили. У системи управління базами даних зазвичай є спеціальний вбудований предикат, аналогічний оператору, що видаляє непотрібний більш тип користувача даних. Це предикат Падіння і сам оператор виглядають так: Drop default ім'я замовчування; 4. Віртуальні атрибути Усі атрибути в системах управління базами даних діляться (за абсолютною аналогією з відносинами) на базові та віртуальні. Так звані базові атрибути - це атрибути, що зберігаються, які необхідно використовувати не один раз, а отже, доцільно зберегти. А, у свою чергу, віртуальні атрибути - це не зберігаються, а обчислювані атрибути. Що це означає? Це означає, що значення так званих віртуальних атрибутів реально не зберігаються, а обчислюються через базові атрибути на ходу за допомогою формул, що задаються. При цьому домени обчислюваних віртуальних атрибутів визначаються автоматично. Наведемо приклад таблиці, задає ставлення, у якій два атрибути - звичайні, базові, а третій атрибут - віртуальний. Він обчислюватиметься за спеціально введеною формулою.
Отже, бачимо, що атрибути " Вага Кг " і " Ціна Руб за Кг " - базові атрибути, оскільки вони мають прості значення і зберігаються у нашій базі даних. А ось атрибут "Вартість" - віртуальний атрибут, тому що він заданий формулою свого обчислення і реально в базі даних не зберігатиметься. Цікаво зауважити, що в силу своєї природи, віртуальні атрибути не можуть набувати значень за умовчанням, та й взагалі, саме поняття значення за умовчанням для віртуального атрибуту позбавлене сенсу, а отже, не застосовується. І ще необхідно знати, що, незважаючи на те, що домени віртуальних атрибутів визначаються автоматично, тип значень, що обчислюються, іноді потрібно замінити з наявного на який-небудь інший. Для цього в мові систем управління базами даних є спеціальний предикат Convert, за допомогою якого може бути перевизначений тип обчислюваного виразу. Convert – це так звана функція явного перетворення типів. Записується вона так: Конвертувати (Тип даних, вираз); Вираз, який стоїть другим аргументом функції Convert, вважатиметься і виведеться у вигляді таких даних, тип яких вказаний першим аргументом функції. Розглянемо приклад. Нехай нам необхідно порахувати значення виразу "2 * 2", але вивести це потрібно не у вигляді цілого числа "4", а рядком символів. Для виконання цього завдання запишемо наступну функцію Convert: Конвертувати (Char (1), 2*2). Таким чином, можна побачити, що цей запис функції Convert точно дасть необхідний нам результат. 5. Поняття ключів При оголошенні схеми базового відношення можуть бути задані кілька ключів. З цим ми вже не раз стикалися раніше. Нарешті настав час поговорити докладніше у тому, що таке ключі відносини, а чи не обмежуватися загальними фразами і наближеними визначеннями. Отже, дамо суворе визначення ключа відношення. Ключ схеми відношення - це підсхема вихідної схеми, що складається з одного або кількох атрибутів, для яких декларується умова унікальності значень у кортежах відносин. Щоб зрозуміти, що таке умова унікальності чи, як його ще називають, обмеження унікальності, Згадаймо для початку визначення кортежу та унарної операції проекції кортежу на підсхему. Наведемо їх: t = t(S) = {t(a) | a ∈ def( t) ⊆ S} - визначення кортежу, t(S) [S'] = {t(a) | a ∈ def(t) ∩ S'}, S' ⊆ S - визначення унарної операції проекції; Зрозуміло, що проекції кортежу на підсхему відповідає рядок рядка таблиці. Отже, що таке обмеження унікальності ключових атрибутів? Оголошення ключа До для схеми відношення S призводить до формулювання наступної інваріантної умови, яка називається, як ми вже говорили, обмеженням унікальності і позначається як: Inv < K → S > r(S): Inv < K → S > r(S) = ∀t1, Т2 ∈ r (t 1[K] = t2 [K] → t 1(S) = t2(S)), K ⊆ S; Отже, це обмеження унікальності Inv < K → S > r(S) ключа К означає, що якщо будь-які два кортежі t1 і t2, Що належать відношенню r(S), рівні в проекції на ключ До, то це неодмінно тягне за собою рівність цих двох кортежів і в проекції на всю схему відношення S. Іншими словами, всі значення кортежів, що належать ключовим атрибутам, унікальні, єдині у своєму відношенні. І друга важлива вимога до ключа ставлення - це вимога ненадмірності. Що це означає? Ця вимога означає, що для будь-якого суворого підмножини ключа вимога унікальності не пред'являється. На інтуїтивному рівні зрозуміло, що ключовий атрибут - це атрибут відносини, який однозначно і точно визначає кожен кортеж відносини. Наприклад, у такому відношенні, заданому таблицею:
ключовим атрибутом є атрибут "№ залікової книжки", тому що у різних студентів не може бути однакового номера залікової книжки, тобто для цього атрибута виконується обмеження унікальності. Цікаво, що в схемі будь-якого відношення можуть зустрітися різні ключі. Перерахуємо основні види ключів: 1) простий ключ - це ключ, що з одного і трохи більше атрибута. Наприклад, в екзаменаційній відомості з конкретного предмета простим ключем є номер заліковки, тому що можна однозначно ідентифікувати будь-якого студента; 2) складовий ключ - це ключ, що складається із двох і більше атрибутів. Наприклад, складовим ключем у списку навчальних аудиторій є номер корпусу та номер аудиторії. Адже якимось одним з цих атрибутів однозначно визначити кожну аудиторію неможливо, а їх сукупністю, тобто складовим ключем, це зробити досить легко; 3) суперключ - це будь-яке надмножина будь-якого ключа. Отже, сама схема відношення є суперключом. З цього можна дійти невтішного висновку, що будь-яке ставлення теоретично має, як мінімум, один ключ, а може мати їх і кілька. Однак оголошення суперключа замість звичайного ключа логічно неприпустиме, оскільки пов'язане з ослабленням автоматично контрольованого обмеження унікальності. Адже супер ключ хоч і має властивість унікальності, але не має властивості надмірності; 4) первинний ключ - це просто ключ, який при завданні базового відношення було оголошено першим. Важливо, що допустиме оголошення одного і лише одного первинного ключа. Крім того, атрибути первинного ключа в жодному разі не можуть приймати Null-значень. При створенні базового відношення у записі на псевдокоді первинний ключ позначається primary key і в дужках вказується ім'я атрибута, який є цим ключем; 5) кандидатні ключі - це решта ключів, оголошених після первинного ключа. У чому полягають основні відмінності кандидатних ключів від первинних ключів? По-перше, кандидатних ключів може бути кілька, тоді як первинний ключ, як було зазначено вище, може бути лише один. І, по-друге, якщо атрибути первинного ключа не можуть набувати Null-значень, то на атрибути кандидатних ключів ця умова не накладається. На псевдокоді за завдання базового ставлення кандидатні ключі оголошуються за допомогою слів candidate key і в дужках поруч, як і у разі оголошення первинного ключа, вказується ім'я атрибуту, який є даним кандидатним ключем; 6) зовнішній ключ - це ключ, оголошений у базовому відношенні, який при цьому посилається на первинний чи кандидатний ключ того самого чи якогось іншого базового відносини. При цьому відношення, на яке посилається зовнішній ключ, називається посилальним (або батьківським) ставленням. А відношення, що містить зовнішній ключ, називається дочірнім. У записі на псевдокоді зовнішній ключ позначається як зовнішній ключ, у дужках безпосередньо після цих слів вказується ім'я атрибута даного відношення, що є зовнішнім ключем, а потім записується ключове слово посилання ("посилається") та вказати ім'я базового відношення та ім'я атрибута, на який і посилається даний конкретний зовнішній ключ. Також при створенні базового відношення для кожного зовнішнього ключа записується умова обмеженням посилальної цілісностіале детально ми говоритимемо про це пізніше. Лекція №8. Створення базових відносин Предметом цієї лекції буде докладний розгляд оператора створення базового відносини. Ми розборимо сам оператор в записі на псевдокоді, проаналізуємо всі його складові та їх роботу, розберемо способи модифікації, тобто зміни базових відносин. 1. Металінгвістичні символи При описі синтаксичних конструкцій, що використовуються в записі оператора створення базового відношення на псевдокод, застосовуються різні металінгвістичні символи. Це всілякі дужки, що відкривають і закривають, різноманітні поєднання крапок і ком, словом, символи, що несуть кожен свій сенс і полегшують програмісту завдання написання коду. Введемо в розгляд і пояснимо зміст основних металінгвістичних символів, що найчастіше використовуються при проектуванні базових відносин. Отже: 1) металінгвістичний символ "{}". Синтаксичні конструкції у фігурних дужках є обов'язкові синтаксичні одиниці. При завданні базового відношення обов'язковими елементами є, наприклад, базові атрибути; без оголошення базових атрибутів жодне відношення може бути спроектовано. Тому при записі оператора створення базового відношення на псевдокод базові атрибути перераховуються у фігурних дужках; 2) металінгвістичний символ "[]". У цьому випадку все навпаки: синтаксичні конструкції у квадратних дужках є необов'язкові синтаксичних елементів. Необов'язковими синтаксичними одиницями в операторі створення базових відносин, у свою чергу, є віртуальні атрибути і первинний, і кандидатний, і зовнішній ключі. Тут, зрозуміло, теж є свої тонкощі, але про них ми поговоримо пізніше, коли перейдемо безпосередньо до проектування оператора створення базового ставлення; 3) металінгвістичний символ "|". Цей символ буквально означає "чи"як аналогічний символ в математиці. Застосування цього металінгвістичного символу означає, що необхідно вибрати між двома або більше конструкціями, розділеними відповідно до цього символу; 4) металінгвістичний символ "...". Багатокрапка, поставлена безпосередньо після будь-яких синтаксичних одиниць, означає можливість повторення цих попередніх металінгвістичного символу синтаксичних елементів; 5) металінгвістичний символ ",..". Цей символ означає майже те саме, що й попередній. Тільки у разі застосування металінгвістичного символу ",..", повторення синтаксичних конструкцій відбувається через кому, Що часто набагато зручніше. З урахуванням цього, можна говорити про еквівалентність наступних двох синтаксичних конструкцій: одиниця [, одиниця]... и одиниця,.. ; 2. Приклад створення базового відношення у записі на псевдокод Тепер, коли ми з'ясували значення основних металінгвістичних символів, що використовуються під час запису оператора створення базового відношення на псевдокоді, ми можемо перейти власне до розгляду цього оператора. Як можна було зрозуміти за згадками вище, оператор створення базового відношення в записі на псевдокоді включає оголошення базових і віртуальних атрибутів, первинного, кандидатних і зовнішніх ключів. Крім того, як буде показано і роз'яснено вище, цей оператор охоплює також обмеження значень атрибутів та обмеження кортежів, а також так звані обмеження цілісності посилання. Перші два обмеження, а саме обмеження значення атрибуту та обмеження кортежу, оголошуються після спеціального зарезервованого слова перевірка. Обмеження цілісності посилання можуть бути двох видів: on update, що означає "при оновленні", та on deleteщо означає "при видаленні". Що це означає? Це означає, що при оновленні або видаленні атрибутів відносин, на які посилається зовнішній ключ, необхідно підтримувати цілісність за станом. (Докладніше про це ми поговоримо пізніше.) Сам оператор створення базових відносин використовується нами вже вивчений - оператор Створювати, тільки для створення саме базових відносин додається ключове слово таблиця ("Ставлення"). І, зрозуміло, так як ставлення саме по собі більше і включає всі розглянуті раніше конструкції, а також нові додаткові конструкції, оператор створення вийде досить великого вигляду. Отже, запишемо на псевдокод загальний вигляд оператора, що використовується для створення базових відносин: Створити таблицю ім'я базового відношення {ім'я базового атрибута тип значень базового атрибуту перевірка (обмеження значення атрибуту) {Null | not Null} дефолт (значення за замовчуванням) },.. [ім'я віртуального атрибуту as (формула обчислення) ],.. [,перевірка (обмеження кортежу)] [,primary key (ім'я атрибута,..)] [,candidate key (ім'я атрибута,..)]... [,зовнішній ключ (ім'я атрибута,..) посилання ім'я посилання (ім'я атрибута,..) on update {Restrict | Cascade | Set Null} on delete {Restrict | Cascade | Set Null} ]... Отже, ми бачимо, що базових та віртуальних атрибутів, кандидатних та зовнішніх ключів може бути оголошено декілька, оскільки після відповідних синтаксичних конструкцій стоїть металінгвістичний символ ",..". Після оголошення первинного ключа цього символу немає, тому що базові відносини, як було зазначено раніше, допускають наявність лише одного первинного ключа. Далі розглянемо детальніше механізм оголошення базових атрибутів. При описі в операторі створення базового відношення будь-якого атрибуту в загальному випадку задаються його ім'я, тип, обмеження значень, прапорець допустимості Null-значень і значення за замовчуванням. Неважко зрозуміти, що тип атрибуту та обмеження його значень визначають його домен, тобто буквально безліч допустимих значень даного конкретного атрибуту. Обмеження значень атрибуту записується як умова, що залежить від імені атрибута. Ось невеликий приклад для полегшення розуміння цього матеріалу: Створити таблицю ім'я базового відношення Курс ціле перевірка (1 <= Курс and Курс <= 5; Тут умова "1 <= Курс and Курс <= 5" разом із визначенням цілого типу даних справді повністю зумовлюють безліч допустимих значень атрибута, т. е. буквально його домен. Прапорець допустимості Null-значень (Null | not Null) забороняє (not Null) чи, навпаки, дозволяє (Null) поява Null-значень серед значень атрибутів. Якщо взяти розглянутий щойно приклад, механізм застосування прапорців допустимості Null-значень виглядає наступним чином: Створити таблицю ім'я базового відношення Курс ціле перевірка (1 <= Курс and Курс <= 5); Not Null; Отже, порядковий номер курсу студента ніколи не може приймати Null-значення, не може бути невідомим упорядникам бази даних і не може не існувати. Значення за замовчуванням (дефолт (за замовчуванням)) використовуються при вставці кортежу у відносини, якщо в операторі вставки значення атрибутів явно не задані. Цікаво помітити, що значення за замовчуванням можуть бути і Null-значеннями, якщо тільки Null-значення для конкретного атрибута оголошені допустимими. Тепер розглянемо визначення віртуального атрибуту в операторі створення базових відносин. Як ми вже говорили раніше, завдання віртуального атрибуту полягає у завданні формул його обчислення через інші базові атрибути. Розглянемо приклад оголошення віртуального атрибуту "Вартість руб." у вигляді формули, яка залежить від базових атрибутів "Вага Кг" і "Ціна Руб. за Кг". Створити таблицю ім'я базового відношення Вага, кг тип значень базового атрибуту Вага Кг перевірка (Обмеження значення атрибуту Вага Кг) not Null дефолт (значення за замовчуванням) Ціна, руб. за Кг Тип значень базового атрибута Ціна руб. за Кг перевірка (обмеження значення атрибуту Ціна руб. за Кг) not Null дефолт (значення за замовчуванням) ... Вартість руб. as (Вага Кг * Ціна руб. за Кг) Трохи вище ми розглянули обмеження атрибутів, які записувалися як умови, що залежать від імен атрибутів. Тепер розглянемо другий вид обмежень, оголошених під час створення базового відносини, саме обмеження кортежу. Що таке обмеження кортежу, чим воно відрізняється від обмеження атрибуту? Обмеження кортежу теж записується як умова, що залежить від імені базового атрибута, але лише у разі обмеження кортежу, умова може залежати від кількох імен атрибутів одночасно. Розглянемо приклад, що ілюструє механізм роботи з обмеженнями кортежів: Створити таблицю ім'я базового відношення min Вага Кг тип значень базового атрибуту min Вага Кг перевірка (обмеження значення атрибуту min Вага Кг) not Null дефолт (значення за замовчуванням) max Вага Кг тип значень базового атрибуту max Вага Кг перевірка (Обмеження значення атрибуту max Вага Кг) not Null дефолт (значення за замовчуванням) перевірка (0 < min Вага Кг та min Вага Кг < max Вага Кг); Таким чином, застосування обмеження до кортежу зводиться до встановлення значень кортежу замість імен атрибутів. Просуваємось далі у розгляді оператора створення базового відносини. Після оголошення базових та віртуальних атрибутів можуть бути оголошені, а можуть і не оголошуватися ключі: первинний, кандидатні та зовнішні. Як ми вже говорили раніше, підсхема базового відношення, якій в іншому (або в тому самому) базовому відношенні відповідає первинний чи кандидатний ключ у контексті першого відношення називається зовнішнім ключем. Зовнішні ключі представляють механізм посилань кортежів одних відносин на кортежі інших відносин, тобто оголошення зовнішніх ключів пов'язані з нав'язуванням вже згадуваних так званих обмежень цілісності посилань. (Цим обмеженням буде присвячена вся наступна лекція, оскільки цілісність за станом (тобто цілісність, що забезпечується обмеженнями цілісності) - це вкрай важлива умова успішного функціонування базового відношення та всієї бази даних.) Оголошення первинних та кандидатних ключів, у свою чергу, нав'язує схемі базового відношення відповідні обмеження унікальності, про які ми вже говорили раніше. І, нарешті, слід сказати можливість видалення базового відносини. Нерідко в практиці проектування баз даних необхідно видалити старе непотрібне ставлення, щоб не захаращувати програмний код. Зробити це можна за допомогою вже знайомого нам оператора Падіння. У загальному вигляді оператор видалення базового відношення виглядає так: Скинути стіл ім'я базових відносин; 3. Обмеження цілісності за станом Обмеження цілісності реляційного об'єкта даних станом - Це так званий інваріант даних. При цьому цілісність слід впевнено відрізняти від безпеки, яка, своєю чергою, передбачає захист даних від несанкціонованого доступу до них з метою розкриття, зміни чи руйнування даних. У випадку обмеження цілісності реляційних об'єктів даних класифікуються за рівнями ієрархії цих самих реляційних об'єктів даних (ієрархія реляційних об'єктів даних - це послідовність вкладених один одного понять: " атрибут - кортеж - ставлення - база даних " ). Що це означає? Це означає, що обмеження цілісності залежать: 1) лише на рівні атрибута - від значень атрибута; 2) лише на рівні кортежу - від значень кортежу, т. е. від значень кількох атрибутів; 3) лише на рівні відносин - від відносини, т. е. від кількох кортежів; 4) лише на рівні бази даних - від кількох відносин. Отже, тепер нам залишається лише розглянути докладніше обмеження цілісності за станом кожного наведеного поняття. Але насамперед дамо поняття процедурної та декларативної підтримки обмежень цілісності за станом. Отже, підтримка обмежень цілісності може бути двох видів: 1) процедурною, Т. е. створеної за допомогою написання програмного коду; 2) декларативної, Т. е. створеної шляхом оголошень тих чи інших обмежень для кожного з названих вище вкладених понять. Декларативна підтримка обмежень цілісності реалізується у контексті оператора Create створення базового відносини. Поговоримо про це докладніше. Почнемо розгляд сукупності обмежень знизу наших ієрархічних сходів реляційних об'єктів даних, тобто з поняття атрибуту. Обмеження рівня атрибуту включає в себе: 1) обмеження типу значень атрибуту. Наприклад, умова цілісності значень, тобто умова integer для атрибута "Курс" з одного з розглянутого раніше базового відношення; 2) обмеження значень атрибута, що записується як умова, що залежить від імені атрибута. Наприклад, аналізуючи те саме базове відношення, що і в попередньому пункті, бачимо, що в цьому відношенні є і обмеження значень атрибуту з використанням опції перевірка, Т. е.: перевірка (1 <= Курс and Курс <= 5); 3) обмеження рівня атрибутів включає обмеження Null-значень, зумовлені вже знайомим нам прапорцем допустимості (Null) чи, навпаки, недопустимості (not Null) Null-значений. Як ми вже згадували раніше, перші два обмеження визначають обмеження домену атрибута, тобто значення його множини визначення. Далі згідно з ієрархічними сходами реляційних об'єктів даних, потрібно говорити про кортежі. Отже, обмеження рівня кортежу зводиться до обмеження кортежу і записується як умова, що залежить від імен декількох базових атрибутів схеми відношення, тобто це обмеження цілісності за станом значно менше і простіше аналогічного, тільки відповідного атрибуту. І знову доцільно буде згадати пройдений раніше приклад базового відносини, що має необхідне нам зараз обмеження кортежу, а саме: перевірка (0 < min Вага Кг та min Вага Кг < max Вага Кг); І, нарешті, останнє значиме у тих обмеження цілісності за станом поняття - це поняття рівня відносин. Як ми вже говорили раніше, обмеження рівня відношення включає обмеження значень первинного (primary key) та кандидатного (candidate key) ключів. Цікаво, що обмеження, що накладаються на бази даних, відносяться вже не до обмежень цілісності за станом, а до обмежень цілісності посилання. 4. Обмеження цілісності посилань Отже, обмеження рівня баз даних включає обмеження цілісності зовнішніх ключів (зовнішній ключ). Коротко ми вже згадували про це, коли говорили про обмеження цілісності посилань при створенні базового відношення та зовнішніх ключах. Тепер настав час поговорити про це більш детально. Як ми вже говорили раніше, зовнішній ключ базового відносини, що оголошується, посилається на первинний або кандидатний ключ якогось іншого (найчастіше) базового відносини. Нагадаємо, що при цьому ставлення, на яке посилається зовнішній ключ, називається посилальним або батьківським, тому що воно як би "породжує" один атрибут або кілька атрибутів у базовому відношенні, що посилається. А, своєю чергою, ставлення, що містить зовнішній ключ, називається дочірнім, теж із цілком зрозумілих причин. У чому полягає обмеження цілісності посилань? А полягає воно в тому, що кожному значенню зовнішнього ключа дочірнього відношення обов'язково має відповідати значення будь-якого ключа відношення батьківського, якщо тільки значення зовнішнього ключа не містить Null-значень у будь-яких атрибутах. Кортежі дочірнього відносини, що порушують цю умову, називаються висять. Справді, якщо зовнішній ключ дочірнього відносини посилається на атрибут, якого насправді в батьківському відношенні немає, він не посилається ні на що. Саме таких ситуацій і потрібно всіляко уникати, це і означає підтримувати цілісність посилань. Але, знаючи, що жодна база даних ніколи не допустить створення висить кортежу, розробники стежать за тим, щоб кортежів, що спочатку висять, в базі даних не було і всі наявні ключі посилалися на цілком реальний атрибут відносини батьківського. Проте бувають ситуації, коли кортежі, що висять, утворюються вже в процесі функціонування бази даних. Що за ситуації? Відомо, що при видаленні кортежів з батьківського відношення або при оновленні значення ключа кортежу батьківського відношення посилальна цілісність може порушитися, тобто можуть виникнути кортежі, що висять. Для виключення можливості їх появи при оголошенні значення зовнішнього ключа визначається одне з трьох наявних правил підтримки цілісності посилань, що застосовуються відповідно при оновленні значення ключа в батьківському відношенні (тобто, як ми вже згадували раніше, on update) або при видаленні кортежу з батьківського відношення (on delete). Необхідно відзначити, що додавання нового кортежу в батьківське ставлення не може порушити цілісність посилань з цілком зрозумілих причин. Адже, якщо цей кортеж щойно додали до базового ставлення, раніше на нього не міг посилатися жоден атрибут через його відсутність! Отже, що це за три правила, що застосовуються підтримки у базах даних посилальної цілісності? Перелічимо їх. 1. обмежувати, або правило обмеження. Якщо ми при завданні нашого базового відношення, при оголошенні зовнішніх ключів в обмеженні цілісності посилання застосували це правило її підтримки, то оновлення ключа в батьківському відношенні або видалення кортежу з батьківського відношення просто не може бути виконане в тому випадку, якщо на цей кортеж посилається хоча б один кортеж дочірнього відношення, тобто операція обмежувати банально забороняє робити будь-які дії, що можуть призвести до появи кортежів, що висять. Проілюструємо застосування цього правила наступним прикладом. Нехай дані два відносини: Батьківське ставлення
Дочірнє ставлення
Ми бачимо, що кортежі дочірнього відношення (2,...) і (2,...) посилаються на кортеж (..., 2) батьківського відношення, а кортеж (3,...) дочірнього відношення посилається на кортеж ( …, 3) батьківського відношення. Кортеж (100,...) дочірнього відношення є висить, він неприпустимий. Тут тільки кортежі батьківського відношення (..., 1) і (..., 4) допускають оновлення значень ключа та видалення кортежів, тому що на них не посилається жоден із зовнішніх ключів дочірнього відношення. Складемо оператор створення базового відношення, що включає оголошення всіх вищеназваних ключів: Створити таблицю Батьківське ставлення Primary_key Ціле число not Null primary key (Primary_key) Створити таблицю Дочірнє ставлення Foreign_key Ціле число Null зовнішній ключ (Foreign_key) посилання Батьківське ставлення (Primary_key) on update Restrict on delete Restrict 2. Каскад, або правило каскадної модифікації. Якщо при оголошенні зовнішніх ключів у нашому базовому відношенні ми використовували правило підтримки цілісності посилань Каскад, то оновлення ключа в батьківському відношенні або видалення кортежу з батьківського відношення викликає автоматичне оновлення або видалення відповідних ключів та кортежів дочірнього відношення. Розглянемо приклад, щоб краще зрозуміти механізм роботи правила каскадної модифікації. Нехай дані вже знайомі нам базові відносини з попереднього прикладу: Батьківське ставлення
и Дочірнє ставлення
Допустимо, ми в таблиці, що задає відношення "Батьківське ставлення", оновимо деякі кортежі, а саме замінимо кортеж (..., 2) на кортеж (..., 20), тобто отримаємо нове відношення: Батьківське ставлення
І нехай при цьому в операторі створення нашого базового відносини "Дочірнє ставлення" при оголошенні зовнішніх ключів ми використовували правило підтримки цілісності посилання Каскад, Т. е. Оператор створення наших базових відносин виглядає наступним чином: Створити таблицю Батьківське ставлення Primary_key Ціле число not Null primary key (Primary_key) Створити таблицю Дочірнє ставлення Foreign_key Ціле число Null зовнішній ключ (Foreign_key) посилання Батьківське ставлення (Primary_key) on update Cascade on delete Cascade Тоді що ж станеться із ставленням дочірнім при оновленні батьківського відношення вказаним вище чином? Воно набуде наступного вигляду: Дочірнє ставлення
Таким чином, дійсно, правило Каскад забезпечує каскадне оновлення всіх кортежів дочірнього відношення у відповідь на оновлення батьківського стосунку. 3. Set Null, або правило присвоєння Null-значень. Якщо ж ми в операторі створення нашого базового відносини при оголошенні зовнішніх ключів застосовуємо правило підтримки цілісності посилань Set Null, то оновлення ключа батьківського відношення або видалення кортежу з батьківського відношення спричиняє автоматичне присвоєння Null-значень тим атрибутам зовнішнього ключа дочірнього відношення, який Null-значення допускають. Отже, правило застосовується, якщо такі атрибути є. Розглянемо приклад, який ми використовували раніше. Нехай нам дано два базові відносини: "Батьківське ставлення"
Дочірнє ставлення
Як можна помітити, атрибути дочірнього відношення допускають Null-значення, отже, правило Set Null у цьому випадку застосовно. Допустимо тепер, що з батьківського відношення було видалено кортеж (..., 1), а кортеж (..., 2) оновлено, як і в попередньому прикладі. Таким чином, батьківське ставлення набуває такого вигляду: Батьківське ставлення
Тоді з урахуванням того, що при оголошенні зовнішніх ключів дочірнього відношення нами застосовувалося правило підтримки цілісності посилань Set Null, дочірнє ставлення набуде наступного вигляду: Дочірнє ставлення
На кортеж (..., 1) не посилався жоден ключ дочірнього відношення, тому його видалення не спричиняє жодних наслідків. Сам оператор створення базових відносин з використанням правила Set Null при оголошенні зовнішніх ключів відношення виглядає так: Створити таблицю Батьківське ставлення Primary_key Ціле число not Null primary key (Primary_key) Створити таблицю Дочірнє ставлення Foreign_key Ціле число Null зовнішній ключ (Foreign_key) посилання Батьківське ставлення (Primary_key) on update Set Null on delete Set Null Отже, бачимо, що наявність трьох різних правил підтримки цілісності посилань забезпечують те, що у фразах on update и on delete функції можуть бути різними. Необхідно пам'ятати і розуміти, що вставка кортежів у дочірнє відношення або оновлення значень ключа дочірніх відносин не будуть виконані, якщо це призводитиме до порушення цілісності посилання, тобто до появи так званих кортежів, що висять. Видалення ж кортежів з дочірнього відношення за жодних умов не може призвести до порушення цілісності посилання. Цікаво, що дочірнє ставлення одночасно може бути і батьківським зі своїми правилами підтримки цілісності, якщо зовнішні ключі інших базових відносин посилаються на якісь його атрибути, як на первинні ключі. Якщо у програмістів виникає бажання забезпечити виконання цілісності посилань якимись відмінними від наведених стандартних правил, то процедурна підтримка таких нестандартних правил підтримки цілісності забезпечується за допомогою так званих тригерів. На жаль, докладний розгляд цього поняття не сходить до нашого курсу лекцій. 5. Поняття індексів Створення ключів у базових відносинах автоматично пов'язане із створенням індексів. Дамо визначення поняття індексу. Індекс - це системна структура даних, у якій розміщується обов'язково впорядкований перелік значень будь-якого ключа з посиланнями ті кортежі відносини, у яких ці значення зустрічаються. Індекси в системах управління базами даних бувають двох видів: 1) прості. p align="justify"> Простий індекс береться для підсхеми схеми базового відношення з одного атрибуту; 2) складові. Відповідно складовий індекс - це індекс для підсхеми, що складається з кількох атрибутів. Але, крім розподілу на прості та складові індекси, у системах управління базами даних існує розподіл індексів на унікальні та неунікальні. Отже: 1) унікальні індекси - це індекси, які посилаються лише на один атрибут. Унікальні індекси, як правило, відповідають первинному ключові відносини; 2) неунікальні індекси - це індекси, які можуть відповідати кільком атрибутам одночасно. Неунікальні ключі, своєю чергою, найчастіше відповідають зовнішнім ключам відносини. Розглянемо приклад, що ілюструє розподіл індексів на унікальні та неунікальні, тобто розглянемо такі відносини, задані таблицями:
Тут відповідно Primary key – первинний ключ відношення, Foreign key – зовнішній ключ. Зрозуміло, що в цих відносинах індекс атрибуту Primary key - унікальний, тому що він відповідає первинному ключу, тобто одному атрибуту, а індекс атрибуту Foreign key - неунікальний, адже він відповідає ключам зовнішнім. І його значення "20" відповідає одночасно першому та третьому рядкам таблиці-відносини. Але інколи індекси можуть створюватися без відношення до ключів. Це робиться в системах управління базами даних для підтримки продуктивності операцій сортування та пошуку. Наприклад, дихотомічний пошук значення індексу в кортежах буде реалізовано у системах управління базами даних за двадцять ітерацій. Звідки отримано ці відомості? Вони були отримані шляхом нескладних обчислень, тобто таким чином: 106 = (103)2 = 220; Створюються індекси в системах управління базами даних за допомогою вже відомого нам оператора Create, але лише з додаванням ключового слова index. Виглядає такий оператор так: Створити індекс ім'я індексу On ім'я базового відношення (ім'я атрибута...); Тут ми бачимо знайомий нам металінгвістичний символ ",..", що означає можливість повторення аргументу через кому, тобто в цьому операторі може бути створений індекс, що відповідає кільком атрибутам. Якщо потрібно оголосити унікальний індекс, перед словом index додають ключове слово unique, тоді весь оператор створення в базовому відношенні індексу набуває наступного вигляду: Створіть унікальний індекс ім'я індексу On ім'я базового відношення (ім'я атрибуту); Тоді в загальному вигляді, якщо згадати правило позначення необов'язкових елементів (металінгвістичний символ []), оператор створення індексу в базовому відношенні буде виглядати так: Create [unique] index ім'я індексу On ім'я базового відношення (ім'я атрибута...); Якщо потрібно видалити з базового відношення вже наявний індекс, використовують оператор Drop, також відомий нам: Індекс падіння {ім'я базового відношення. Ім'я індексу},.. ; Чому тут використовується уточнене ім'я індексу "ім'я базового відношення. Ім'я індексу"? В операторі видалення індексу завжди використовується його уточнене ім'я, тому що ім'я індексу має бути унікальним у межах одного відношення, але не більше. 6. Модифікація базових відносин Для успішної та продуктивної роботи з різними базовими відносинами дуже часто розробникам необхідно якось модифікувати це базові відносини. Які основні необхідні варіанти модифікації зустрічаються найчастіше у практиці проектування баз даних? Перерахуємо їх: 1) вставлення кортежів. Дуже часто потрібно у вже сформоване базове ставлення вставити нові кортежі; 2) оновлення значень атрибутів. А необхідність цієї модифікації на практиці програмування зустрічається ще частіше, ніж попередня, адже при надходженні нової інформації про аргументи вашої бази даних неминуче доведеться якусь стару інформацію оновлювати; 3) видалення кортежів. І з приблизно рівною ймовірністю виникає необхідність видалити з базового відношення ті кортежі, присутність яких у вашій базі даних більше не потрібна через нову інформацію. Отже, ми окреслили основні моменти модифікації базових відносин. Як можна досягти кожної з поставлених цілей? У системах управління базами даних найчастіше існують убудовані, базові оператори модифікації відносин. Дамо їх опис у записі на псевдокод: 1) оператор вставки у базове відношення нових кортежів. Це оператор Insert. Виглядає він так: Вставити в ім'я базового відношення (ім'я атрибута,..) Цінності (Значення атрибута,..); Металінгвістичний символ ",..", поставлений після імені атрибуту та значення атрибута, говорить нам, що цей оператор допускає одночасне додавання кількох атрибутів до базового відношення. У цьому випадку необхідно імена атрибутів та значення атрибутів перераховувати через кому в узгодженому порядку. Ключове слово в у поєднанні із загальною назвою оператора Insert означає "вставити" і показує, в яке відношення необхідно вставити вказані в дужках атрибути. Ключове слово Цінності у цьому операторі і означає "значення", "величини", які і присвоюються цим оголошеним атрибутам; 2) тепер розглянемо оператор оновлення значень атрибутів у базовому відношенні. Цей оператор називається Оновити, що в перекладі з англійської мови і означає буквально "оновити". Дамо повний загальний вигляд цього оператора в записі на псевдокод і розшифруємо її: Оновити ім'я базового відношення Установка {ім'я атрибута - значення атрибута}. де умова; Отже, у першому рядку оператора після ключового слова Оновити записується ім'я базового відношення, в якому необхідно зробити оновлення. Ключове слово Set перекладається з англійської "задати", і в цьому рядку оператора вказуються імена атрибутів, які необхідно оновити, та відповідні нові значення атрибутів. В одному операторі можна оновити відразу кілька атрибутів, що випливає із застосування металінгвістичного символу ",..". У третьому рядку після ключового слова де записується умова, яка показує, які саме атрибути цього базового відношення необхідно оновити; 3) оператор видаляти, що дозволяє видаляти якісь кортежі з базового відношення. Запишемо його повний вид на псевдокод і роз'яснимо значення всіх окремих синтаксичних одиниць: Delete from ім'я базового відношення де умова; Ключове слово від у поєднанні з назвою оператора видаляти перекладається як "видалити з". І після цих ключових слів у першому рядку оператора вказується ім'я базового відношення, з якого необхідно видалити будь-які кортежі. А в другому рядку оператора після ключового слова де ("де") вказується умова, за якою відбираються кортежі, які більше не потрібні в нашому базовому відношенні. Лекція №9. Функціональні залежності 1. Обмеження функціональної залежності Обмеження унікальності, що накладаються оголошеннями первинного та кандидатних ключів відносини, є окремим випадком обмежень, пов'язаних з поняттям функціональних залежностей. Для пояснення поняття функціональної залежності розглянемо наступний приклад. Нехай нам дано відношення, що містить дані про результати якоїсь однієї конкретної сесії. Схема цього відношення виглядає так: Сесія (№ залікової книжки, Прізвище ім'я по батькові, Предмет, оцінка); Атрибути "№ залікової книжки" та "Предмет" утворюють складовий (оскільки ключем оголошено два атрибути) первинний ключ цього відношення. Дійсно, за двома цими атрибутами можна однозначно визначити значення всіх інших атрибутів. Однак, крім обмеження унікальності, пов'язаної з цим ключем, на ставлення неодмінно має бути накладена та умова, що одна залікова книжка видається обов'язково одній конкретній людині і, отже, у цьому відношенні кортежі з однаковим номером залікової книжки повинні містити однакові значення атрибутів "Прізвище" , "Ім'я" та "По батькові".
Якщо ми маємо наступний фрагмент якоїсь певної бази даних студентів навчального закладу після якоїсь сесії, то в кортежах з номером залікової книжки 100, атрибути "Прізвище", "Ім'я" та "По батькові" збігаються, а атрибути "Предмет" та "Оцінка" - не збігаються (що і зрозуміло, адже в них йдеться про різні предмети та успішність із них). Це означає, що атрибути "Прізвище", "Ім'я" та "По батькові" функціонально залежать від атрибута "№ залікової книжки", а атрибути "Предмет" та "Оцінка" функціонально не залежать. Таким чином, функціональна залежність - це однозначна залежність, затабульована у системах управління базами даних. Тепер дамо суворе визначення функціональної залежності. Визначення: нехай X, Y - підсхеми схеми відношення S, що визначають над схемою S схему функціональної залежності X → Y (Читається "X стрілка Y"). Визначимо обмеження функціональної залежності inv<X → Y> як твердження про те, що у відношенні зі схемою S будь-які два кортежі, що збігаються в проекції на підсхему X, повинні збігатися і в проекції на підсхему Y. Запишемо це ж визначення у формулярному вигляді: Inv<X → Y> r(S) = t1, Т2 ∈ r(t1[X] = t2[X] ⇒ t1[Y] = t2 [Y]), X, Y ⊆ S; Цікаво, що у цьому визначенні використано поняття унарної операції проекції, з яким ми стикалися раніше. Справді, як ще, якщо не використовувати цю операцію, показати рівність один одному двох стовпців таблиці-відносини, а не рядків? Тому ми й записали в термінах цієї операції, що збіг кортежів у проекції на якийсь атрибут або кілька атрибутів (підсхему X) неодмінно спричиняє збіг цих самих стовпців-кортежів і на підсхемі Y у тому випадку, якщо Y функціонально залежить від X . Цікаво помітити, що у разі функціональної залежності Y від X, кажуть також, що X функціонально визначає Y або що Y функціонально залежить від X. У схемі функціональної залежності X → Y підсхема X називається лівою частиною, а підсхема Y – правою частиною. На практиці проектування баз даних на схему функціональної залежності для стислості зазвичай посилаються як на функціональну залежність. Кінець визначення. В окремому випадку, коли права частина функціональної залежності, тобто підсхема Y, збігається з усією схемою відношення, обмеження функціональної залежності переходить в обмеження унікальності первинного або кандидатного ключа. Дійсно: Inv r(S) = ∀ t1, Т2 ∈ r(t1[K] = t2 [K] → t1(S) = t2(S)), K ⊆ S; Просто у визначенні функціональної залежності замість підсхеми X потрібно взяти позначення ключа K, а замість правої частини функціональної залежності, підсхеми Y взяти всю схему відносин S, тобто дійсно обмеження унікальності ключів відносин є окремим випадком обмеження функціональної залежності при рівності правої частини схеми функціональної залежності всієї схеми відношення. Наведемо приклади зображення функціональної залежності: {№ залікової книжки} → {Прізвище, Ім'я, По батькові}; {№ залікової книжки, Предмет} → {Оцінка}; 2. Правила виведення Армстронга Якщо якесь базове відношення задовольняє векторно певним функціональним залежностям, то за допомогою різних спеціальних правил виведення можна отримати інші функціональні залежності, яким дане базове відношення заздалегідь задовольнятиме. Хорошим прикладом таких спеціальних правил є правила виведення Армстронг. Але перш ніж приступати до аналізу самих правил виведення Армстронга, введемо до розгляду новий металінгвістичний символ "├", який називається символом метаствердження про виведення. Цей символ при формулюванні правил записується між двома синтаксичними виразами і свідчить про те, що з формули, що стоїть ліворуч від нього, виводиться формула, що стоїть праворуч від нього. Сформулюємо тепер самі правила виведення Армстронга як наступної теореми. Теорема. Справедливі такі правила, які називають правилами виведення Армстронга. Правило виведення 1. ├ X → X; Правило виведення 2. X → Y├ X ∪ Z → Y; Правило виведення 3. X → Y, Y ∪ W → Z ├ X ∪ W → Z; Тут X, Y, Z, W - довільні підсхеми схеми відношення S. Символ метаствердження про виведення поділяє списки посилок і списки тверджень (укладень). 1. Перше правило виведення називається "рефлексивність" і читається так: " виводиться правило: " X функціонально тягне у себе X " " . Це найпростіше з правил виведення Армстронга. Воно виводиться буквально з повітря. Цікаво помітити, що функціональна залежність, що має і ліву, і праву частини, називається рефлексивний. Відповідно до правила рефлексивності обмеження рефлексивної залежності виконується автоматично. 2. Друге правило виведення називається "поповненняі читається таким чином: "якщо X функціонально визначає Y, то виводиться правило: "об'єднання підсхем X і Z функціонально тягне за собою Y". Правило поповнення дозволяє розширювати ліву частину обмеження функціональних залежностей. 3. Третє правило виведення називається "псевдотранзитивністьі читається наступним чином: "якщо підсхема X функціонально тягне за собою підсхему Y і об'єднання підсхем Y і W функціонально тягнуть за собою Z, то виводиться правило: "об'єднання підсхем X і W функціонально визначають підсхему Z"". Правило псевдотранзитивності узагальнює правило транзитивності, що відповідає окремому випадку W: = 0. Наведемо формулярний запис цього правила: X → Y, Y → Z ├X → Z. Необхідно відзначити, що посилки та висновки, наведені раніше, були представлені у скороченій формі позначеннями схем функціональної залежності. У розширеній формі їм відповідають такі обмеження функціональних залежностей. Правило виведення 1. inv r(S); Правило виведення 2. inv r(S) ⇒ inv r(S); Правило виведення 3. inv r(S) & inv r(S) ⇒ inv r(S); Проведемо докази цих правил виведення. 1. Доказ правила рефлексивності слід безпосередньо з визначення обмеження функціональної залежності при підстановці замість підсхеми Y - підсхеми X. Дійсно, візьмемо обмеження функціональної залежності: Inv r(S) і підставимо в нього X замість Y, отримаємо: Inv r(S), а це і є правилом рефлексивності. Правило рефлексивності підтверджено. 2. Доказ правила поповнення проілюструємо на діаграмах функціональної залежності. Перша діаграма – це діаграма посилки: посилка: X → Y
Друга діаграма: висновок: X ∪ Z → Y
Нехай кортежі дорівнюють X ∪ Z. Тоді вони дорівнюють X. Відповідно до посилки вони дорівнюють і Y. Правило поповнення підтверджено. 3. Доказ правила псевдотранзитивності також проілюструємо на діаграмах, яких у цьому випадку буде три. Перша діаграма - перша посилка: посилка 1: X → Y
посилка 2: Y ∪ W → Z
І, нарешті, третя діаграма - діаграма укладання: висновок: X ∪ W → Z
Нехай кортежі рівні на X ∪ W. Тоді вони рівні і на X, і на W. Відповідно до Посилки 1, вони будуть рівні і на Y. Звідси, згідно з Посилкою 2, вони дорівнюватимуть і Z. Правило псевдотранзитивності підтверджено. Усі правила доведено. 3. Похідні правила виведення Іншим прикладом правил, за допомогою яких можна, за необхідності вивести нові правила функціональної залежності, є так звані похідні правила виведення. Що це за правила, як вони виходять? Відомо, що з одних правил, вже існуючих, законними логічними методами вивести інші, ці нові правила, звані похідними, можна використовувати поряд із вихідними правилами. Необхідно спеціально відзначити, що ці довільні правила є "похідними" саме від пройдених нами раніше правил виведення Армстронга. Сформулюємо похідні правила виведення функціональних залежностей у вигляді наступної теореми. Теорема. Наступні правила є похідними від правил виведення Армстронг. Правило виведення 1. ├ X ∪ Z → X; Правило виведення 2. X → Y, X → Z ├ X ∪ Y → Z; Правило виведення 3. X → Y ∪ Z ├ X → Y, X → Z; Тут X, Y, Z, W, як і й у попередньому випадку, - довільні підсхеми схеми відносини S. 1. Перше похідне правило називається правилом тривіальності і читається так: "Виводиться правило: "об'єднання підсхем X та Z функціонально тягне за собою X". Функціональна залежність з лівою частиною, що є підмножиною правої частини, називається тривіальною. Відповідно до правила тривіальності обмеження тривіальної залежності виконуються автоматично. Цікаво, що правило тривіальності є узагальненням правила рефлексивності і, як і останнє, могло бути отримано безпосередньо з визначення обмеження функціональної залежності. Той факт, що це правило є похідним, невипадковий і пов'язаний з повнотою системи правил Армстронга. Докладніше про повноту системи правил Армстронга ми поговоримо трохи згодом. 2. Друге похідне правило називається правилом адитивності і читається наступним чином: "Якщо підсхема X функціонально визначає підсхему Y, X одночасно функціонально визначає Z, то з цих правил виводиться наступне правило: "X функціонально визначає об'єднання підсхем Y і Z"". 3. Третє похідне правило називається правилом проективності чи правилом "звернення адитивності". Воно читається так: "Якщо підсхема X функціонально визначає об'єднання підсхем Y і Z, то з цього правила виводиться правило: "X функціонально визначає підсхему Y і одночасно X функціонально визначає підсхему Z"", тобто, дійсно, це похідне правило є зверненим правилом адитивності. Цікаво, що правила адитивності та проективності стосовно функціональних залежностей з однаковими лівими частинами дозволяють об'єднувати або, навпаки, розщеплювати праві частини залежності. При побудові ланцюжків виведення після формулювання всіх посилок застосовується правило транзитивності з метою, щоб включити функціональну залежність із правою частиною, що ув'язнення. Проведемо докази перерахованих довільних правил виведення. 1. Доказ правила тривіальності. Проведемо його, як і всі наступні докази, за кроками: 1) маємо: X → X (із правила рефлексивності виведення Армстронга); 2) маємо далі: X ∪ Z → X (отримуємо, застосовуючи спочатку правило поповнення висновку Армстронга, та був як наслідок першого кроку докази). Правило тривіальності підтверджено. 2. Проведемо покроковий доказ правила адитивності: 1) маємо: X → Y (це посилка 1); 2) маємо: X → Z (це посилка 2); 3) маємо: Y∪Z → Y∪Z (з правила рефлексивності виведення Армстронга); 4) маємо: X∪Z → Y∪Z (отримуємо за допомогою застосування правила псевдотранзитивності виведення Армстронга, а потім як наслідок першого та третього кроків доказу); 5) маємо: X ∪ X → Y ∪ Z (отримуємо, застосовуючи правило псевдотранзитивності виведення Армстронга, а потім випливає з другого та четвертого кроків); 6) маємо X → Y ∪ Z (випливає з п'ятого кроку). Правило адитивності підтверджено. 3. І, нарешті, проведемо побудову доказу правила проективності: 1) маємо: X → Y ∪ Z, X → Y ∪ Z (це посилка); 2) маємо: Y → Y, Z → Z (виводиться за допомогою правила рефлексивності виведення Армстронга); 3) маємо: Y ∪ z → y, Y ∪ z → Z (виходить із правила поповнення висновку Армстронга та наслідком з другого кроку доказу); 4) маємо: X → Y, X → Z (виходить, застосуванням правила псевдотранзитивності виведення Армстронга, а потім як наслідок з першого та третього кроків доказу). Правило проектності доведено. Усі похідні правила виведення доведені. 4. Повнота системи правил Армстронга Нехай F(S) - задана множина функціональних залежностей, заданих над схемою відношення S. Позначимо через фактура обмеження, що накладається цим безліччю функціональних залежностей. Розпишемо його: Inv r(S) = ∀X → Y ∈F(S) [inv r(S)]. Отже, це безліч обмежень, що накладається функціональними залежностями, розшифровується наступним чином: для будь-якого правила системи функціональних залежностей X → Y, що належить безлічі функціональних залежностей F(S), діє обмеження функціональних залежностей inv r(S), визначених над безліччю відношення r(S). Нехай якесь відношення r(S) задовольняє це обмеження. Застосовуючи правила виведення Армстронга до функціональних залежностей, визначених для безлічі F(S), можна отримати нові функціональні залежності, як було сказано і доведено нами раніше. І, що показово, обмеженням цих функціональних залежностей ставлення F(S) автоматично задовольнятиме, що видно з розширеної форми запису правил виведення Армстронга. Нагадаємо загальний вигляд цих розширених правил виведення: Правило виведення 1. inv < X → X > r(S); Правило виведення 2. inv r(S) ⇒ inv <X ∪ Z → Y> r(S); Правило виведення 3. inv r(S) & inv <Y ∪ W → Z> r(S) ⇒ inv <X ∪ W → Z>; Повертаючись до наших міркувань, поповнимо безліч F(S) новими, виведеними з нього за допомогою правил Армстронга залежностями. Застосовуватимемо цю процедуру поповнення доти, доки у нас не перестануть виходити нові функціональні залежності. В результаті цієї побудови ми отримаємо нову безліч функціональних залежностей, звану замиканням множини F(S) і позначається F+(S). Дійсно, така назва цілком логічна, адже ми власноруч шляхом тривалої побудови "замкнули" безліч наявних функціональних залежностей саму себе, додавши (звідси "+") все нові функціональні залежності, що виходять з наявних. Слід зазначити, що це процес побудови замикання кінцевий, адже кінцева сама схема відносини, де і проводяться всі ці побудови. Зрозуміло, що замикання є надмножиною замиканої множини (справді, воно більше!) і ні скільки не змінюється при своєму повторному замиканні. Якщо записати щойно сказане у формулярному вигляді, то отримаємо: F(S) ⊆ F+(S), [F+(S)]+= Ф+(S); Далі з доведеної істинності (тобто законності, правомірності) правил виведення Армстронга та визначення замикання слід, що будь-яке відношення, що задовольняє обмеженням заданої безлічі функціональних залежностей, задовольнятиме обмеження залежності, що належить замиканню. X → Y ∈ F+(S) ⇒ ∀r(S) [inv r(S) ⇒ inv r(S)]; Отже, теорема повноти системи правил виведення Армстронга стверджує, що зовнішня імплікація може цілком законно та обґрунтовано замінити еквівалентність. (Доказ цієї теореми ми розглядати не будемо, тому що сам процес доказу не такий важливий у нашому конкретному курсі лекцій.) Лекція №10. Нормальні форми 1. Сенс нормалізації схем баз даних Поняття, яке ми розглядатимемо у цьому розділі, пов'язані з поняттям функціональних залежностей, т. е. сенс нормалізації схем баз даних нерозривно пов'язані з поняттям обмежень, накладаних системою функціональних залежностей, й багато в чому випливає з цього поняття. Вихідною точкою будь-якого проектування бази даних є уявлення предметної області як однієї чи кількох відносин, і кожному кроці проектування виробляється деякий набір схем відносин, які мають " поліпшеними " властивостями. Таким чином, процес проектування є процес нормалізації схем відносин, причому кожна наступна нормальна форма має властивості, в деякому сенсі кращі, ніж попередня. Кожній нормальній формі відповідає певний набір обмежень, і відношення перебуває у певній нормальній формі, якщо задовольняє властивому їй набору обмежень. Прикладом може бути обмеження першої нормальної форми - значення всіх атрибутів відношення атомарні. Теоретично реляційних баз даних зазвичай виділяється наступна послідовність нормальних форм: 1) перша нормальна форма (1 NF); 2) друга нормальна форма (2 NF); 3) третя нормальна форма (3 NF); 4) нормальна форма Бойса – Кодда (BCNF); 5) четверта нормальна форма (4 NF); 6) п'ята нормальна форма або нормальна форма проекції-з'єднання (5 NF або PJ/NF). (До цього курсу лекцій включається докладний розгляд перших чотирьох нормальних форм базових відносин, тому ми детально розбиратимемо четверту і п'яту нормальні форми.) Основні властивості нормальних форм полягають у наступному: 1) кожна наступна нормальна форма в деякому сенсі краща за попередню нормальну форму; 2) під час переходу до наступної нормальної формі властивості попередніх нормальних форм зберігаються. В основі процесу проектування лежить метод нормалізації, тобто декомпозиції відносини, що перебуває в попередній нормальній формі, на два або більше відносин, які задовольняють вимогам наступної нормальної форми (з цим ми зіткнемося, коли нам самим доведеться в міру проходження матеріалу проводити нормалізацію того чи іншого базового відносини). Як згадувалося у розділі, присвяченому створенню базових відносин, задані безлічі функціональних залежностей, накладають відповідні обмеження на схеми базових відносин. Ці обмеження у випадку реалізуються двома методами: 1) декларативно, тобто за допомогою оголошення в базовому відношенні різного виду первинних, кандидатних та зовнішніх ключів (це метод, який набув найбільшого поширення); 2) процедурно, т. е. написанням програмного коду (використанням згаданих вище про тригерів). За допомогою простої логіки можна зрозуміти, в чому полягає сенс нормалізації схем баз даних. Нормалізувати бази даних або приводити бази даних до нормального вигляду - це означає визначати такі схеми базових відносин, щоб максимально зменшити необхідність написання програмного коду, збільшити продуктивність роботи бази даних, полегшити підтримку цілісності даних за станом та цілісністю посилань. Тобто зробити код та роботу з ним максимально простою та зручною розробникам та користувачам. Для того, щоб наочно в порівнянні продемонструвати роботу ненормалізованої та нормалізованої бази даних, розглянемо наступний приклад. Нехай у нас є базове відношення, яке містить інформацію про результати екзаменаційної сесії. Таку базу даних ми вже розглядали раніше. Отже, варіант 1 схеми бази даних Сесія (№ залікової книжки, Прізвище ім'я по батькові, Предмет, Оцінка) У цьому відношенні, як видно із зображення схеми базового відношення, заданий складовий первинний ключ: Primary key (№ залікової книжки, Предмет); Також щодо цього задана система функціональних залежностей: {№ залікової книжки} → {Прізвище, Ім'я, По батькові}; Наведемо табличний вигляд невеликого фрагмента бази даних із даною схемою відношення. Цей фрагмент ми вже застосовували в розгляді обмежень функціональних залежностей, тому на його прикладі нам буде досить легко зрозуміти цю тему.
Тут для підтримки цілісності даних за станом, тобто для виконання обмеження системи функціональної залежності {№ залікової книжки} → {Прізвище, Ім'я, По-батькові} при зміні, наприклад, прізвища необхідно переглядати всі кортежі цього базового відношення і послідовно вводити необхідні зміни. Однак, оскільки це досить громіздкий і трудомісткий процес (особливо якщо ми маємо справу з базою даних великого навчального закладу), розробники систем управління базами даних дійшли висновку, що цей процес необхідно автоматизувати, тобто зробити автоматичним. Тепер контроль за виконанням цієї (і будь-якої іншої) функціональної залежності можна організовувати автоматично за допомогою правильного оголошення в базовому відношенні різних ключів і так званої декомпозиції (тобто розбиття чогось на кілька самостійних частин) цього відношення. Отже, нашу схему відносини "Сесія" розіб'ємо на дві схеми: схему "Студенти", що містить тільки інформацію про студентів цього навчального закладу, і схему "Сесія", що містить інформацію про останню сесію. А потім оголосимо ключі таким чином, щоб можна було легко отримати будь-яку необхідну інформацію. Покажемо, як виглядатимуть ці нові схеми стосунків зі своїми ключами. Варіант 2 схеми бази даних Студенти (№ залікової книжки, Прізвище ім'я по батькові), Primary key (№ залікової книжки). Сесія (№ залікової книжки, Предмет, Оцінка), Primary key (№ залікової книжки, Предмет), Foreign key (№ залікової книжки) Студенти (№ номер залікової книжки). Що ми маємо тепер? Щодо "Студенти" первинний ключ "№ залікової книжки" функціонально визначає решту трьох атрибутів: "Прізвище", "Ім'я" та "По батькові". А щодо "Сесія" складовий первинний ключ "№ залікової книжки, Предмет" також однозначно, тобто буквально функціонально визначає останній атрибут цієї схеми відношення - "Оцінка". І зв'язок між цими двома відносинами налагоджено: він здійснюється за допомогою зовнішнього ключа відносини "Сесія" "№ залікової книжки", який посилається на однойменний атрибут відносини "Студенти" і за відповідного запиту надає всю необхідну інформацію. Покажемо тепер, як виглядатимуть відносини, представлені таблицями, відповідальні другого варіанту завдання відповідних схем баз даних.
Таким чином, ми бачимо, що метою нормалізації в аспекті обмежень, що накладаються функціональними залежностями, є необхідність нав'язати будь-якій базі даних необхідні функціональні залежності за допомогою оголошень різного виду первинних, кандидатних та зовнішніх ключів базових відносин. 2. Перша нормальна форма (1NF) На ранніх стадіях проектування баз даних та розробки схем їх управління використовувалися прості та однозначні атрибути як найбільш продуктивні та раціональні одиниці коду. Тоді застосовували поряд з простими та складові атрибути, а також поряд з однозначними та багатозначними атрибутами. Пояснимо значення кожного з цих понять. Складові атрибути, на відміну простих, - це атрибути, складені з кількох простих атрибутів. Багатозначні атрибути, на відміну однозначних, - це атрибути, які мають безліч значень. Наведемо приклади простих, складових, однозначних та багатозначних атрибутів. Розглянемо наступну таблицю, що становить ставлення:
Тут атрибут "Телефон" - простий, однозначний, а атрибут "Адреса" - простий, але багатозначний. Тепер розглянемо іншу таблицю з іншими атрибутами:
У цьому відношенні, представленому таблицею, атрибут "Телефони" - простий, але багатозначний, а атрибут "Адреси" - і складовий, і багатозначний. Взагалі можливі різні комбінації простих чи складових атрибутів. У різних випадках таблиці, що представляють відносини, можуть виглядати наступним чином:
p align="justify"> При нормалізації схем базових відносин програмістами може бути використана одна з чотирьох найбільш поширених видів нормальних форм: перша нормальна форма (1NF), друга нормальна форма (2NF), третя нормальна форма (3NF) або нормальна форма Бойса - Кодда (NFBC). Пояснимо: скорочення NF – це абревіатура від англомовного словосполучення Normal Form. Формально, крім вищеназваних, існують інші види нормальних форм, але вищеназвані - одні з найбільш затребуваних. Нині розробники баз даних намагаються уникати складових і багатозначних атрибутів, ніж ускладнювати написання коду, не перевантажувати його структуру і заплутувати користувачів. З цих міркувань логічно і випливає визначення першої нормальної форми. Визначення. Будь-яке базове відношення знаходиться в першій нормальній формі тоді й лише тоді, коли схема цього відношення містить лише прості і лише однозначні атрибути, причому обов'язково з тією самою семантикою. Для наочного пояснення відмінностей нормалізованих та ненормалізованих відносин розглянемо приклад. Нехай є ненормалізоване ставлення з наступною схемою. Отже, варіант 1 схеми відносини із заданим на ній простим первинним ключем: Співробітники (№ табельний, Прізвище Ім'я По батькові, Код посади, Телефони, Дата прийому або звільнення); Primary key (№ табельний); Перелічимо, які в цій схемі відносини є помилки, тобто назвемо ті ознаки, які й роблять власне цю схему ненормалізованою: 1) атрибут "Прізвище Ім'я По батькові" є складовим, тобто складеним із різнорідних елементів; 2) атрибут "Телефони" є багатозначним, тобто його значенням є безліч значень; 3) атрибут "Дата прийому чи звільнення" не має однозначної семантики, тобто в останньому випадку не зрозуміло, яку саме дату внесено. Якщо, наприклад, ввести додатковий атрибут, щоб точніше визначити зміст дати, то для цього атрибута значення буде семантично зрозумілим, але залишається можливість зберігання тільки однієї з зазначених дат для кожного співробітника. Що ж потрібно зробити для приведення цього ставлення до нормальної форми? По-перше, необхідно провести розбиття складових атрибутів на прості, щоб виключити ці складові атрибути, а також атрибути зі складовою семантикою. А по-друге, необхідно провести декомпозицію цього відношення, тобто потрібно розбити його на кілька нових самостійних відносин, щоб виключити багатозначні атрибути. Таким чином, з урахуванням всього вищесказаного після приведення відношення "Співробітники" до першої нормальної форми або 1NF шляхом його декомпозиції ми отримаємо систему наступних відносин із заданими на них первинними та зовнішніми ключами. Отже, варіант 2 відносини: Співробітники (№ табельний, Прізвище, Ім'я, По-батькові, Код посади, Дата прийому, Дата звільнення); Primary key (№ табельний); Телефони (№ табельний, Телефон); Primary key (№ табельний, Телефон); Foreign key (№ табельний) references Співробітники (№ табельний); Отже, що бачимо? Складового атрибуту "Прізвище Ім'я По батькові" більше у нашому відношенні немає, замість нього присутні три простих атрибути "Прізвище", "Ім'я" та "По батькові", тому ця причина "ненормальності" стосунку виключилася. Крім того, замість атрибуту з неясною семантикою "Дата прийому чи звільнення" у нас з'явилося два атрибути "Дата прийому" та "Дата звільнення", кожен з яких має однозначну семантику. Отже, друга причина того, що наше ставлення "Співробітники" не перебуває у нормальній формі, також благополучно усунуто. І, нарешті, остання причина того, що відношення "Співробітники" не було приведено до нормальної форми, - наявність багатозначного атрибуту "Телефони". Щоб позбавитися цього атрибуту, і необхідно було провести декомпозицію всього відношення. З вихідного відношення "Співробітники" в результаті цієї декомпозиції було виключено атрибут "Телефони" взагалі, зате утворилося друге відношення - "Телефони", в якому присутні два атрибути: "№ табельний" співробітника і "Телефон", тобто всі атрибути - Знов-таки прості, умова належності до першої нормальної форми виконується. Ці атрибути "№ табельний" і "Телефон" утворюють складовий первинний ключ відношення "Телефони", а атрибут "№ табельний", у свою чергу, є зовнішнім ключем, що посилається на однойменний атрибут відносини "Співробітники", тобто щодо " Телефони" атрибут первинного ключа "№ табельний" є одночасно зовнішнім ключем, що посилається на первинний ключ відношення "Співробітники". Таким чином забезпечується зв'язок між цими двома відносинами. За допомогою цього зв'язку можна за номером табельним будь-якого співробітника без особливих зусиль і витрат часу вивести весь список його телефонів, не вдаючись до використання складових атрибутів. Зауважимо, що у разі наявності щодо системи обмежень функціональних залежностей після всіх вищенаведених перетворень нормалізація була б завершена. Однак у даному конкретному прикладі немає обмежень функціональних залежностей, тому подальша нормалізація цього відношення не потрібна. 3. Друга нормальна форма (2NF) Більш сильні вимоги накладає на відносини друга нормальна форма, або 2NF. Це тому, що визначення другої нормальної форми відносин передбачає, на відміну першої нормальної форми, наявність системи обмежень функціональних залежностей. Визначення. Базове ставлення знаходиться в другий нормальній формі відносного заданого безлічі функціональних залежностей тоді і лише тоді, коли воно знаходиться в першій нормальній формі і, крім того, кожен неключовий атрибут повністю функціонально залежить від кожного ключа. У цьому визначенні неключовий атрибут - це будь-який атрибут відносини, який міститься у якомусь первинному чи кандидатному ключі відносини. Повна функціональна залежність від ключа передбачає відсутність функціональної залежності від будь-якої частини ключа. Таким чином, тепер при нормалізації відносини ми повинні стежити і за виконанням умов перебування відносини у першій нормальній формі, тобто стежити, щоб його атрибути були простими та однозначними, а також за виконанням другої умови щодо обмежень функціональних залежностей. Зрозуміло, що відносини з простими ключами (первинними та кандидатними) свідомо перебувають у другій нормальній формі. Адже в такому разі, залежність від частини ключа просто не представляється можливою, тому що жодних окремих частин ключ банально не має. Тепер, як і під час проходження попередньої теми, розглянемо приклад ненормалізованої схеми відносини і процес нормалізації. Отже, варіант 1 схеми відношення: Аудиторії (№ корпусу, № аудиторії, площа кв. м, № табельний коменданта корпусу); Primary key (№ корпусу, № аудиторії); Крім того, визначено таку систему функціональної залежності: {№ корпусу} → {№ табельний коменданта корпусу}; Що ми бачимо? Усі умови перебування цього відношення "Аудиторії" у першій нормальній формі виконані, адже всі до єдиного атрибути цього відношення однозначні та прості. Але та умова, що кожен неключовий елемент має повністю функціонально залежати від ключа, не виконується. Чому? Та оскільки атрибут " № табельний коменданта корпусу " функціонально залежить немає від складового ключа " № корпусу, № аудиторії " , як від частини цього ключа, т. е. від атрибута " № корпуса " . Справді, саме номер корпусу повністю визначає, який саме комендант до нього приписаний, а, у свою чергу, ні від яких номерів аудиторій табельний номер коменданта корпусу залежати ніяк не може. Таким чином, основним завданням нашої нормалізації стає завдання досягти того, щоб ключі розподілялися таким чином, щоб, зокрема, атрибут "№ табельний коменданта корпусу" повністю функціонально залежав від усього ключа, а не від його якоїсь частини. Для того, щоб цього досягти, доведеться знову, як і в попередньому параграфі, застосувати декомпозицію відносин. Отже, наступна система відносин, що є варіант 2 відносини "Аудиторії", якраз і вийшла з вихідного відношення шляхом його декомпозиції на кілька нових самостійних відносин: Корпуси (№ корпусу, № табельний коменданта корпусу); Primary key (№ корпусу); Аудиторії (№ корпусу, № аудиторії, площа кв. м); Primary key (№ корпусу, № аудиторії); Foreign key (№ корпусу) references Корпуса (№ корпусу); Що ми тепер бачимо? Щодо "Корпуса" неключовий атрибут "№ табельний коменданта корпусу" повністю функціонально залежить від первинного ключа "№ корпусу". Тут умова знаходження відносин у другій нормальній формі повністю виконалися. Тепер перейдемо до розгляду другого відношення – "Аудиторії". Щодо "Аудиторії" атрибут первинного ключа "№ корпусу" є одночасно зовнішнім ключем, що посилається на первинний ключ відношення "Корпуса". Щодо цього неключовий атрибут "Площа кв. м" повністю залежить від усього складового первинного ключа "№ корпусу, № аудиторії" і не залежить, навіть не може залежати від жодної з його частин. Таким чином, шляхом декомпозиції вихідного відношення, ми дійшли того, що всі умови визначення другої нормальної форми повністю виконалися. У цьому прикладі всі вимоги функціональної залежності нав'язані оголошенням первинних ключів (кандидатних ключів немає) і зовнішніх ключів. Тому подальша нормалізація не потрібна. 4. Третя нормальна форма (3NF) Наступною нормальною формою, яку ми будемо розглядати, є третя нормальна форма (або 3NF). На відміну від першої нормальної форми, як і друга нормальна форма, третя - передбачає завдання разом із ставленням системи функціональних залежностей. Сформулюємо, які властивості має мати відношення, щоб воно було наведеним до третьої нормальної форми. Визначення. Базове відношення знаходиться в третій нормальній формі щодо заданої множини функціональних залежностей тоді і тільки тоді, коли вона знаходиться в другій нормальній формі і кожен неключовий атрибут повністю функціонально залежить тільки від ключів. Таким чином, вимоги, що пред'являються третьою нормальною формою, сильніші за вимоги, що накладаються першою та другою нормальною формою, навіть разом узятих. Фактично в третій нормальній формі кожен неключовий атрибут залежить від ключа, причому від усього ключа цілком і ні від чого іншого, крім від ключа. Проілюструємо процес приведення ненормалізованого ставлення до третьої нормальної форми. Для цього розглянемо приклад: ставлення, що знаходиться не в третій нормальній формі. Отже, варіант 1 схеми відносини "Співробітники": Співробітники (№ табельний, Прізвище, Ім'я, По батькові, Код посади, Оклад); Primary key (№ табельний); Крім того, над цим ставленням "Співробітники" задана така система функціональних залежностей: {Код посади} → {Оклад}; Справді, зазвичай, з посади, отже, від її коду у відповідній базі даних безпосередньо залежить розмір окладу, т. е. розмір зарплати. Саме тому це відношення "Співробітники" і не перебуває у третій нормальній формі, адже виходить, що неключовий атрибут "Оклад" повністю функціонально залежить від атрибуту "Код посади", хоча цей атрибут і не є ключовим. Цікаво, що до третьої нормальної форми будь-яке відношення наводиться таким самим методом, як і до двох форм до цієї, а саме, шляхом декомпозиції. Провівши декомпозицію відносини "Співробітники", отримаємо наступну систему нових самостійних відносин: Отже, варіант 2 схеми відносини "Співробітники": Посади (Код посади, Оклад); Primary key (Код посади); Співробітники (№ табельний, Прізвище, Ім'я, По батькові, Код посади); Primary key (Код посади); Foreign key (Код посади) Посади (Код посади); Тепер, як бачимо, щодо "Посади" неключовий атрибут "Оклад" повністю функціонально залежить від простого первинного ключа "Код посади" і від цього ключа. Зауважимо, що щодо "Співробітники" всі чотири неключові атрибути "Прізвище", "Ім'я", "По батькові" та "Код посади" повністю функціонально залежать від простого первинного ключа "№ табельний". Щодо цього атрибут "Код посади" - зовнішній ключ, що посилається на первинний ключ відношення "Посади". У цьому прикладі всі вимоги нав'язані оголошенням простих первинних та зовнішніх ключів, тому подальша нормалізація не потрібна. Цікаво та корисно знати, що на практиці зазвичай обмежуються приведенням баз даних до третьої нормальної форми. При цьому, можливо, не нав'язаними залишаються деякі функціональні залежності ключових атрибутів від інших атрибутів цього ж відношення. Підтримка таких нестандартних функціональних залежностей реалізується за допомогою згадуваних раніше тригерів (тобто процедурно, шляхом написання відповідного програмного коду). Причому тригери мають оперувати кортежами цього відношення. 5. Нормальна форма Бойса – Кодда (NFBC) Нормальна форма Бойса – Кодда слід за "складністю" відразу після третьої нормальної форми. Тому нормальну форму Бойса – Кодда ще іноді називають просто посиленою третьою нормальною формою (або посиленою 3 NF). Чому вона саме посилена? Сформулюємо визначення нормальної форми Бойса - Кодда: Визначення. Базове відношення знаходиться в нормальній формі Бойса - Кодда тоді і тільки тоді, коли вона знаходиться у третій нормальній формі, і при цьому не тільки будь-який неключовий атрибут повністю функціонально залежить від будь-якого ключа, але й будь-який ключовий атрибут повинен функціонально залежати від будь-якого ключа. Таким чином, вимога про фактичну залежність неключових атрибутів від усього ключа цілком і ні від чого іншого, крім ключа, поширюється і на ключові атрибути. Що стосується, що у нормальної формі Бойса - Кодда, все функціональні залежності у межах відносини нав'язані оголошенням ключів. Однак при приведенні відносин баз даних до форми Бойса - Кодда, можливі ситуації, за яких не нав'язаними функціональними залежностями виявляються залежності між атрибутами різних відносин. Підтримка таких функціональних залежностей за допомогою тригерів, що оперують кортежами різних відносин, складніша, ніж у випадку третьої нормальної форми, коли тригери оперують кортежами єдиного відношення. Окрім іншого, практика проектування систем управління базами даних показала, що не вдається привести базове ставлення до нормальної форми Бойса - Кодда. Причиною зазначених аномалій є те, що у вимогах другої нормальної форми та третьої нормальної форми не була потрібна мінімальна функціональна залежність від первинного ключа атрибутів, що є компонентами інших можливих ключів. Цю проблему і вирішує нормальна форма, яку історично прийнято називати нормальною формою Бойса - Кодда і яка є уточненням третьої нормальної форми у разі наявності кількох можливих ключів, що перекриваються. Взагалі нормалізація схеми бази даних сприяє більш ефективного виконання системою управління базами даних операцій оновлення бази даних, оскільки скорочується кількість перевірок та допоміжних дій, що підтримують цілісність бази даних. При проектуванні реляційної бази даних майже завжди домагаються другої нормальної форми всіх відносин, що входять до бази даних. У базах даних, що часто оновлюються, зазвичай намагаються забезпечити третю нормальну форму відносин. На нормальну форму Бойса - Кодда увагу звертають набагато рідше, оскільки на практиці ситуації, в яких у відносини є кілька складових можливих ключів, що перекриваються, зустрічаються нечасто. Все вищезгадане робить нормальну форму Бойса - Кодда не надто зручною у використанні при розробці програмного коду, тому, як уже було сказано раніше, на практиці розробники зазвичай обмежуються приведенням своїх баз даних до третьої нормальної форми. Однак тут також є своя досить цікава особливість. Справа в тому, що ситуації, коли відношення знаходиться в третій нормальній формі, але не знаходиться в нормальній формі Бойса - Кодда вкрай рідкісні на практиці, тобто після приведення до третьої нормальної форми зазвичай всі функціональні залежності виявляються нав'язаними оголошеннями первинних, кандидатних і зовнішніх ключів, тому потреба в тригерах підтримки функціональних залежностей відпадає. Проте необхідність у тригерах залишається підтримки обмеження цілісності, не пов'язаних функціональними залежностями. 6. Складність нормальних форм Що означає вкладеність нормальних форм один одного? Вкладеність нормальних форм - це відношення понять ослабленої та посиленої форми по відношенню один до одного. Вкладенность нормальних форм цілком випливає з відповідних визначень. Представимо діаграму, що ілюструє відношення вкладеності відомих нам нормальних форм:
Пояснимо поняття ослабленої та посиленої нормальної форми стосовно один одного на конкретних прикладах. Перша нормальна форма є ослабленою по відношенню до другої нормальної форми (та й по відношенню до всіх інших нормальних форм теж). Справді, згадуючи визначення всіх пройдених нами нормальних форм, можна помітити, що вимоги кожної нормальної форми включали вимогу належності саме до першої нормальної формі (адже вона входила в кожне наступне визначення). Друга нормальна форма є посиленою по відношенню до першої нормальної форми, але ослабленою по відношенню до третьої нормальної форми та нормальної форми Бойса - Кодда. Насправді приналежність другий нормальній формі входить у визначення третьої, а друга форма, своєю чергою, включає у собі першу нормальну форму. Нормальна форма Бойса - Кодда є посиленої як стосовно третьої нормальної формі, але й стосовно всім іншим, попереднім їй. А третя нормальна форма, у свою чергу, є ослабленою лише по відношенню до нормальної форми Бойса – Кодда. Лекція №11. Проектування схем баз даних Найбільш поширеним засобом абстрактного представлення схем баз даних під час проектування на логічному рівні є так звана модель "сутність – зв'язок". Її ще іноді називають ER-модель, де ER – абревіатура англійського словосполучення Entity – Relationship, що буквально і перекладається як “сутність – зв'язок”. Елементами таких моделей є класи сутностей, їх атрибути та зв'язки. Дамо пояснення та визначення кожного з цих елементів. Клас сутностей - це хіба що позбавлений методів клас об'єктів у сенсі объектно-ориентированного програмування. При переході до фізичного рівня класи сутностей перетворюються на базові відносини реляційних баз даних для конкретних систем управління базами даних. У них, як і власне базових відносин, існують власні атрибути. Дамо більш точне і строге визначення щойно наведених об'єктів. Класом називається іменований опис сукупності об'єктів із загальними атрибутами, операціями, зв'язками та семантикою. Графічно зазвичай клас зображується як прямокутника. У кожного класу має бути ім'я (текстовий рядок), що унікально відрізняє його від усіх інших класів. Атрибут класу називається іменоване властивість класу, що описує безліч значень, які можуть набувати екземпляри цієї властивості. Клас може мати будь-яке число атрибутів (зокрема, не мати жодного атрибуту). Властивість, що виражається атрибутом, є властивістю сутності, що моделюється, загальним для всіх об'єктів даного класу. Отже, атрибут є абстракцією стану об'єкта. Будь-який атрибут будь-якого об'єкта класу повинен мати певне значення. Так звані зв'язки реалізуються за допомогою оголошення зовнішніх ключів (подібні явища нам вже зустрічалися раніше), тобто щодо оголошуються зовнішні ключі, що посилаються на первинні чи кандидатні ключі якихось інших відносин. І з цього і відбувається " зв'язування " кількох різних самостійних базових взаємин у єдину систему, звану базою даних. Далі діаграма, що становить графічну основу моделі "сутність – зв'язок", зображується за допомогою уніфікованої мови моделювання UML. Мовою об'єктно-орієнтованого моделювання UML (або Unified Modeling Language) присвячено безліч книг, багато з яких перекладені російською мовою (а деякі і написані російськими авторами). Взагалі, UML дозволяє моделювати різні види систем: чисто програмні, чисто апаратні, програмно-апаратні, змішані, які включають діяльність людей і т.д. Однак, як ми вже згадували, мова UML активно застосовується для проектування реляційних баз даних. Для цього використовується невелика частина мови (діаграми класів) та й то не в повному обсязі. З точки зору проектування реляційних баз даних модельні можливості не надто відрізняються від можливостей ER-діаграм. Ми також хотіли показати, що в контексті проектування реляційних баз даних структурні методи проектування, що базуються на використанні ER-діаграм, та об'єктно-орієнтовані методи, що базуються на використанні мови UML, розрізняються головним чином лише термінологією. ER-модель концептуально простіше UML, у ній менше понять, термінів, варіантів застосування. І це зрозуміло, оскільки різні варіанти ER-моделей розроблялися саме для підтримки проектування реляційних баз даних і ER-моделі майже не містять можливостей, що виходять за межі реальних потреб проектувальника реляційної бази даних. Мова UML належить до об'єктного світу. Цей світ набагато складніший (якщо завгодно, незрозуміліше, заплутаніше) реляційного світу. Оскільки UML може використовуватися для уніфікованого об'єктно-орієнтованого моделювання всього чого завгодно, у цій мові міститься безліч різних понять, термінів та варіантів використання, надмірних з погляду проектування реляційних баз даних. Якщо виокремити із загального механізму діаграм класів те, що дійсно потрібно для проектування реляційних баз даних, ми отримаємо точно ER-діаграми з іншою нотацією і термінологією. Цікаво, що при формуванні імен класів в UML допускається використання довільної комбінації букв, цифр і навіть розділових знаків. Однак на практиці рекомендується використовувати як імена класів короткі і осмислені прикметники і іменники, кожне з яких починається з великої літери. (Докладніше поняття діаграми ми розглянемо у наступному параграфі нашої лекції.) 1. Різні типи та кратності зв'язків Зв'язок між відносинами під час проектування схем баз даних зображується як ліній, що з'єднують класи сутностей. У цьому кожен із кінців зв'язку може (і взагалі повинен) характеризуватись найменуванням (т. е. типом зв'язку) і кратністю ролі класу у зв'язку. Розглянемо докладніше поняття кратності та типи зв'язків. Кратністю (multiplicity) називається характеристика, що вказує, скільки атрибутів класу сутності з цією роллю може чи має брати участь у кожному екземплярі зв'язку якогось виду. Найбільш поширеним способом завдання кратності ролі зв'язку є пряма вказівка конкретного числа чи діапазону. Наприклад, вказівка "1" говорить про те, що кожен клас з цією роллю повинен брати участь у деякому екземплярі даного зв'язку, причому в кожному екземплярі зв'язку може брати участь один об'єкт класу з цією роллю. Вказівка діапазону " 0..1 " свідчить, що не об'єкти класу з цією роллю повинні брати участь у якомусь екземплярі цього зв'язку, але у кожному екземплярі зв'язку може брати участь лише одне об'єкт. Поговоримо про кратності докладніше. Типовими, найпоширенішими кратностями у системах проектування баз даних є такі кратності: 1) 1 - кратність зв'язку на відповідному її кінці дорівнює одиниці; 2) 0 ... 1 - така форма запису означає, що кратність цього зв'язку на відповідному своєму кінці не може перевищувати одиниці; 3) 0... ∞ - така кратність розшифровується просто "багато". Цікаво, що, як правило, "багато" означає "нічого"; 4) 1... ∞ - таке позначення набула кратність "один або більше". Наведемо приклад простий діаграми для ілюстрування роботи з різними кратностями зв'язків.
Згідно з цією діаграмою, можна легко зрозуміти, що кожна каса має багато квитків, а, у свою чергу, кожен квиток знаходиться в якійсь одній (і не більше) касі. Тепер розглянемо найпоширеніші типи чи найменування зв'язків. Перерахуємо їх: 1) 1 : 1 - таке позначення отримала зв'язокодин до одного", тобто це як би взаємно-однозначне відповідність двох множин; 2) 1 : 0... ∞ - це позначення зв'язку типу "один до багатьох". Для стислості такий зв'язок називають "1: М". У розглянутій раніше діаграмі, як можна помітити, є зв'язок саме з таким найменуванням; 3) 0... ∞ : 1 - це звернення попереднього зв'язку або зв'язок типу "багато до одного"; 4) 0... ∞ : 0... ∞ - це позначення зв'язку типу "багато хто до багатьох", тобто з кожного кінця зв'язку є багато атрибутів; 5) 0... 1 : 0... 1 - це зв'язок, аналогічний введеному раніше зв'язку типу "один до одного", він, у свою чергу, називається "не більше одного до не більше одного"; 6) 0... 1 : 0... ∞ - це зв'язок, аналогічний зв'язку типу "один до багатьох", він називається "не більше одного до багатьох"; 7) 0... ∞ : 0... 1 - це зв'язок, у свою чергу, аналогічний зв'язку типу "багато до одного", він називається "багато хто до не більше одного". Як можна помітити, три останні зв'язки вийшли зі зв'язків, які в нашій лекції перераховані під номерами один, два і три шляхом заміни кратності "один" на кратність "не більше одного". 2. Діаграми. Види діаграм І тепер перейдемо, нарешті, безпосередньо до розгляду діаграм та їх видів. Загалом виділяють три рівні логічної моделі. Ці рівні розрізняються по глибині уявлення про структурі даних. Цим рівням відповідають такі діаграми: 1) презентаційна діаграма; 2) ключова діаграма; 3) повна атрибутивна діаграма. Розберемо кожен із названих видів діаграм і докладно пояснимо зміст їхньої відмінності за глибиною подання інформації про структуру даних. 1. Презентаційна діаграма. Такі діаграми описують лише основні класи сутностей та його зв'язку. Ключі в таких діаграмах можуть не описуватися зовсім, і, відповідно, зв'язки - ніяк не індивідуалізуватися. Тому допустимими є зв'язки типу "багато до багатьох", хоча зазвичай їх намагаються уникати або, якщо вони все ж таки присутні, - деталізувати. Також цілком допустимими є складові та багатозначні атрибути, хоча ми й писали раніше, що базові відносини з такими атрибутами не є наведеними до будь-якої нормальної форми. Цікаво, що з розглянутих нами трьох видів діаграм тільки останній вид (повна атрибутивна діаграма) передбачає, що дані, представлені за допомогою, знаходяться в певній нормальній формі. Тоді як вже розглянута презентаційна діаграма та наступна на черзі ключова діаграма нічого подібного не припускають. Такі діаграми, як правило, використовуються для презентацій (звідси і їх назва – презентаційні, тобто використовуються для презентацій, демонстрацій, де надмірна деталізація і не потрібна). Іноді під час проектування баз даних необхідно проконсультуватися з експертами предметної галузі, інформацією якої ця конкретна база даних і займається. Тоді також використовуються презентаційні діаграми, адже для отримання потрібних відомостей у фахівців професії, далекої від програмування, надмірне уточнення специфічних деталей зовсім не потрібне. 2. Ключова діаграма. На відміну від презентаційних діаграм ключові діаграми обов'язково описують всі класи сутностей та їх зв'язку, щоправда, в термінах тільки первинних ключів. Тут зв'язки "багато до багатьох" вже неодмінно деталізуються (тобто зв'язків такого типу в чистому вигляді тут просто не може бути задано). Багатозначні атрибути все ще допускаються так само, як і в презентаційній діаграмі, але якщо вони присутні в ключовій діаграмі, то, як правило, вони перетворюються на самостійні класи сутностей. Але, що цікаво, однозначні атрибути все ще можуть бути не повністю представлені або описані як складові. Ці "вільності", ще допустимі у таких діаграмах, як презентаційна та ключова, не допустимі вже в наступному вигляді діаграми, адже вони визначають, що базове відношення не є нормалізованим. Таким чином, можна зробити висновок, що ключові діаграми передбачають надалі лише "навішування" атрибутів на вже описані класи сутностей, тобто за допомогою презентаційної діаграми достатньо описати найнеобхідніші класи сутностей, а потім вже за допомогою діаграми ключової додати до неї все необхідні атрибути і конкретизувати всі найважливіші зв'язки. 3. Повна атрибутивна діаграма. Повні атрибутивні діаграми найбільш детально з усіх вищезгаданих описують усі класи сутностей, їх атрибути та зв'язки між цими класами сутностей. Як правило, такі діаграми представляють дані, що знаходяться в третій нормальній формі, тому природно, що в базових відносинах, описаних такими діаграмами, не допускається наявності складових або багатозначних атрибутів, так само як і не допускається наявність недеталізованих зв'язків типу "багато до багатьох". Однак у повних атрибутивних діаграм все-таки є недолік, тобто їх не можна повною мірою назвати найбільш повними з діаграм у сенсі подання даних. Наприклад, особливість конкретних систем керування базами даних при використанні повних атрибутивних діаграм все ще не враховується, і зокрема, тип даних конкретизується лише тією мірою, якою це необхідно для необхідного логічного рівня моделювання. 3. Зв'язки та міграція ключів Дещо раніше ми вже говорили про те, що таке зв'язки в базах даних. Зокрема, зв'язок встановлювався під час оголошення зовнішніх ключів відносин. Але в цьому розділі нашого курсу йдеться вже не про базові відносини, а про каса сутностей. У цьому сенсі процес встановлення зв'язків однаково пов'язані з оголошеннями різних ключів, але тепер говоримо вже ключах класів сутностей. А саме процес встановлення зв'язків пов'язаний із перенесенням простого або складового первинного ключа одного класу сутностей до іншого класу. Сам процес такого перенесення ще називають міграцією ключів. При цьому клас сутностей, первинні ключі якого переносяться, називається батьківським класом, А клас сутностей, у чиї зовнішні ключі і відбувається міграція, називається дочірнім класом сутностей. У дочірньому класі сутностей атрибути ключа набувають статусу атрибутів зовнішнього ключа і при цьому можуть брати участь або, навпаки, не брати участь у формуванні його первинного ключа. Таким чином, при міграції первинного ключа з батьківського класу сутностей до дочірнього в дочірньому класі виникає зовнішній ключ, що посилається на первинний ключ батьківського класу. Для зручності формулярного уявлення міграції ключів, введемо такі маркери ключів: 1) PK - так ми позначатимемо будь-який атрибут первинного ключа (primary key); 2) FK - цим маркером ми позначатимемо атрибути зовнішнього ключа (foreign key); 3) PFK - таким маркером ми позначатимемо атрибут первинного/зовнішнього ключа, тобто будь-який такий атрибут, який входить до складу єдиного первинного ключа деякого класу сутностей і одночасно до складу деякого зовнішнього ключа цього ж класу сутностей. Таким чином, атрибути класу сутностей із маркерами PK і FK утворюють первинний ключ цього класу. А атрибути з маркерами FK та PFK входять до складу деяких зовнішніх ключів цього класу сутностей. Взагалі, ключі можуть мігрувати по-різному, і в кожному такому разі виникає якийсь свій вид зв'язку. Отже, розглянемо, які бувають види зв'язків залежно від схеми міграції ключів. Усього розрізняють дві схеми міграції ключів. 1. Схема міграції ∀PK (PK |→PFK); У цьому записі символ "|→" означає поняття "мігрує", тобто наведена формула прочитається наступним чином: будь-який (кожний) атрибут первинного ключа PK батьківського класу сутностей переноситься (мігрує) до складу первинного ключа PFДочірній клас сутностей, який, природно, є одночасно і зовнішнім ключем для цього класу. І тут йдеться у тому, кожен без винятку атрибут ключа батьківського класу сутностей повинен мігрувати дочірній клас сутностей. Такий вид зв'язку називається ідентифікуючою, оскільки ключ батьківського класу сутності цілком бере участь у ідентифікації дочірніх сутностей. Серед зв'язків ідентифікуючого типу, у свою чергу, виділяють ще два можливі самостійні типи зв'язків. Отже, ідентифікуючі зв'язки бувають двох таких типів: 1) повністю ідентифікуючими. Ідентифікуючий зв'язок називається повністю ідентифікуючим в тому і тільки в тому випадку, коли атрибути мігруючого первинний ключ батьківського класу сутностей повністю формують первинний (і одночасно зовнішній) ключ дочірнього класу сутностей. Повністю ідентифікуючий зв'язок ще іноді називають категоріальноїтому, що повністю ідентифікуючий зв'язок ідентифікує дочірні сутності по всіх категоріях; 2) не повністю ідентифікуючими. Ідентифікуючий зв'язок називається не повністю ідентифікуючим у тому і тільки в тому випадку, коли атрибути мігруючого первинного ключа батьківського класу сутностей лише частково формує первинний (і водночас зовнішній) ключ дочірнього класу сутностей. Таким чином, крім ключа з маркером PFK також буде присутній ключ з маркером PK. При цьому зовнішній ключ PFK дочірнього класу сутностей повністю визначатиметься первинним ключем PK батьківського класу сутностей, а просто первинний ключ PK цього дочірнього відношення не визначатиметься первинним ключем PK батьківського класу сутностей, він буде сам по собі. 2. Схема міграції ∃PK (PK |→ FK); Така схема міграції має читатися так: існують такі атрибути первинного ключа батьківського класу сутностей, які за міграції переносяться до складу обов'язково неключових атрибутів дочірнього класу сутностей. Таким чином, у цьому випадку йдеться про те, що деякі, а не всі, як у попередньому випадку, атрибути первинного ключа батьківського класу сутностей переносяться до дочірнього класу сутностей. Крім того, якщо попередня схема міграції визначала міграцію до первинного ключа дочірнього відношення, який при цьому ставав ще й зовнішнім ключем, то останній вид міграції визначає, що атрибути первинного ключа батьківського класу сутностей мігрують у звичайні, спочатку неключові атрибути, які вже після цього набувають статус зовнішнього ключа Такий тип зв'язку називається неідентифікуючимадже, дійсно, батьківський ключ цілком не бере участі у формуванні дочірніх сутностей, він просто не ідентифікує їх. Серед неідентифікуючих зв'язків також виділяють два можливі типи зв'язків. Таким чином, неідентифікуючі зв'язки бувають двох таких видів: 1) обов'язково неідентифікуючими. Неідентифікуючі зв'язки називаються обов'язково не ідентифікуючими в тому і тільки в тому випадку, коли Null-значення для всіх атрибутів мігруючого ключа дочірнього класу сутностей заборонені; 2) необов'язково неідентифікуючими. Неідентифікуючі зв'язки називаються не обов'язково неідентифікуючими в тому і тільки в тому випадку, коли Null-значення для деяких атрибутів мігруючого ключа дочірнього класу сутностей дозволено. Узагальним усе вищесказане у вигляді наступної таблиці, щоб полегшити завдання систематизації та розуміння наведеного матеріалу. Також до цієї таблиці ми включимо інформацію про те, які типи зв'язків ("не більше одного до одного", "багато до одного", "багато до не більше одного") відповідають яким видам зв'язків (повністю ідентифікуючими, не повністю ідентифікуючими, обов'язково не ідентифікуючими, які не обов'язково не ідентифікують). Отже, між батьківськими та дочірніми класами сутностей встановлюється наступний тип зв'язків залежно від виду зв'язку.
Отже, бачимо, що у всіх випадках, крім останнього, посилання не порожнє (not null) → 1. Зауважимо таку тенденцію, що у батьківському кінці зв'язку у всіх випадках, крім останнього, встановлюється кратність "один". Це відбувається тому, що значенню зовнішнього ключа у випадках цих зв'язків (а саме повністю ідентифікуюча, не повністю ідентифікуюча і обов'язково не ідентифікуюча види зв'язків) обов'язково має відповідати (і притому єдине) значення первинного ключа батьківського класу сутностей. А в останньому випадку через те, що значення зовнішнього ключа допускає рівність Null-значенню (прапорець допустимості FK: null), на батьківському кінці зв'язку встановлюється кратність "не більше одного". Проводимо наш аналіз далі. На дочірньому кінці зв'язку в усіх випадках, крім першого, встановлюється кратність "багато". Це відбувається тому, що за рахунок неповної ідентифікації, як у другому випадку, (або взагалі відсутності такої, у другому та третьому випадках) значення первинного ключа батьківського класу сутностей може багаторазово зустрічатися серед значень зовнішнього ключа дочірнього класу. А в першому випадку зв'язок – повністю ідентифікуючий, тому атрибути первинного ключа батьківського класу сутностей можуть зустрічатися серед атрибутів ключів дочірнього класу сутностей лише одного разу. Лекція №12. Зв'язки класів сутностей Отже, усі пройдені нами поняття, а саме діаграми та їхні види, кратності та види зв'язків, а також види міграції ключів, тепер допоможуть нам у проходженні матеріалу про ті ж зв'язки, але вже між конкретними класами сутностей. Серед них, як ми побачимо, також бувають зв'язки різних видів. 1. Ієрархічний рекурсивний зв'язок Першим видом зв'язку класів сутностей між собою, який ми розглянемо, є так звана ієрархічний рекурсивний зв'язок. Взагалі рекурсія (або рекурсивний зв'язок) - це зв'язок класу сутностей із самим собою. Іноді за аналогією з життєвими ситуаціями такий зв'язок ще називають "рибальський гачок". Ієрархічним рекурсивним зв'язком (або просто ієрархічною рекурсією) називається будь-яка рекурсивна зв'язок типу " трохи більше одного багатьом " . Ієрархічна рекурсія найчастіше використовується у тому, щоб зберігати дані деревоподібної структури. При завданні ієрархічного рекурсивного зв'язку первинний ключ батьківського класу сутностей (який у цьому конкретному випадку одночасно виступає у ролі дочірнього класу сутностей) повинен мігрувати як зовнішнього ключа до складу обов'язково неключових атрибутів тієї самої класу сутностей. Усе це необхідно підтримки логічної цілісності самого поняття " ієрархічна рекурсія " . Таким чином, з урахуванням всього вищесказаного, можна зробити висновок, що ієрархічний рекурсивний зв'язок може бути лише не обов'язково не ідентифікує і ніякий інший, тому що у разі використання будь-якого іншого виду зв'язку, Null-значення для зовнішнього ключа були б неприпустимі і рекурсія була б нескінченною. Важливо також пам'ятати, що атрибути не можуть з'являтися двічі в тому самому класі сутностей під одним і тим же ім'ям. Тому атрибути ключа, що мігрував, обов'язково повинні отримати так зване ім'я ролі. Таким чином, в ієрархічному рекурсивному зв'язку атрибути вузла розширюються зовнішнім ключем, що є необов'язковим посиланням на первинний ключ вузла, що є його безпосереднім предком. Побудуємо презентаційну та ключову діаграми, що реалізує ієрархічну рекурсію в реляційній моделі даних, та наведемо приклад табличної форми. Спочатку складемо презентаційну діаграму:
Тепер побудуємо докладнішу - ключову діаграму:
Розглянемо приклад, що наочно ілюструє такий вид зв'язку, як ієрархічний рекурсивний зв'язок. Нехай нам дано наступний клас сутностей, що складається, як і попередній приклад, з атрибутів "Код Предка" та "Код Вузла". Спочатку покажемо табличну форму представлення цього класу сутності:
А тепер збудуємо діаграму, що представляє цей клас сутностей. Для цього виділимо з таблиці всі необхідні для цього відомості: предка біля вузла з кодом "одиниця" не існує або не визначено, з цього робимо висновок, що вузол "одиниця" є вершиною. Цей самий вузол "одиниця" є предком для вузлів з кодом "два" і "три". У свою чергу, у вузла з кодом "два" є два нащадки: вузол з кодом "чотири" та вузол з кодом "п'ять". А біля вузла з кодом "три" - лише один нащадок - вузол із кодом "шість". Отже, з урахуванням всього вищесказаного побудуємо деревоподібну структуру, яка відображатиме інформацію про дані, закладену в попередній таблиці:
Отже, ми побачили, що репрезентувати деревоподібні структури дійсно зручно за допомогою ієрархічного рекурсивного зв'язку. 2. Мережевий рекурсивний зв'язок Мережевий рекурсивний зв'язок класів сутностей між собою є як би багатовимірним аналогом вже пройденого нами ієрархічного рекурсивного зв'язку. Тільки якщо ієрархічна рекурсія визначалася як рекурсивна зв'язок типу " трохи більше одного до багатьох " , то мережева рекурсія являє собою такий самий рекурсивний зв'язок, тільки вже типу "багато хто до багатьох". Через те, що у зв'язку з кожної сторони бере участь багато класів сутностей, її і називають мережевою. Як вже можна здогадатися за аналогією з ієрархічною рекурсією, зв'язки виду мережевої рекурсії призначені для представлення графових структур даних (тоді як ієрархічні зв'язки застосовуються, як ми пам'ятаємо, виключно для реалізації деревоподібних структур). Але, оскільки у зв'язку з видом мережевої рекурсії задані зв'язки типу саме "багато до багатьох", без їх додаткової деталізації не обійтися. Тому для уточнення всіх наявних у схемі зв'язків типу "багато до багатьох" стає необхідним створити новий самостійний клас сутностей, що містить усі посилання на предка або нащадка зв'язку "Предок - Нащадок". Такий клас у загальному випадку називається класом асоціативних сутностей. У нашому окремому випадку (у базах даних, що підлягають розгляду в нашому курсі) асоціативна сутність не має власних додаткових атрибутів і називається іменуючою, оскільки називає зв'язку " Предок - Нащадок " шляхом посилань ними. Таким чином, первинний ключ класу сутностей, що представляє вузли мережі, має двічі мігрувати до класів асоціативних сутностей. У цьому класі ключі, що мігрували, в сукупності повинні утворювати складовий первинний ключ. З усього вищесказаного можна дійти невтішного висновку, що що встановлюють зв'язку під час використання мережевої рекурсії мають бути повністю ідентифікуючими і ніякими іншими. Так само як і при використанні ієрархічного рекурсивного зв'язку, при застосуванні як зв'язок мережевої рекурсії жоден атрибут не може з'являтися двічі в одному класі сутностей під тим самим ім'ям. Тому, як і минулого разу, спеціально зазначається, що всі атрибути мігруючого ключа обов'язково мають отримати ім'я ролі. Для ілюстрування роботи мережного рекурсивного зв'язку, побудуємо презентаційну та ключову діаграми, що реалізують мережеву рекурсію у реляційній моделі даних. Спочатку представимо презентаційну діаграму:
А тепер побудуємо докладнішу ключову діаграму:
Що ми тут бачимо? А бачимо ми, що обидві зв'язки, що є в даній ключовій діаграмі, є зв'язками виду "багато до одного". Причому кратність "0... ∞" або кратність "багато" стоїть на кінці зв'язку, зверненого до класу сутностей. Справді, адже посилань багато, а посилаються вони на якийсь один код вузла, що є первинним ключем класу сутностей "Вузли". І, нарешті, розглянемо приклад, що ілюструє роботу такого виду зв'язку класом сутностей як мережева рекурсія. Нехай нам дано табличне уявлення деякого класу сутностей, а також іменуючий клас сутностей, що містить інформацію про посилання. Наведемо ці таблиці. вузли:
Посилання:
Дійсно, вищенаведене уявлення вичерпне: воно дає всю необхідну інформацію для того, щоб легко відтворити зашифровану тут графову структуру. Наприклад, ми без жодних перешкод можемо побачити, що у вузла з кодом "один" є три нащадки відповідно з кодами "два", "три" та "чотири". Також ми бачимо, що у вузлів з кодами "два" і "три" нащадків немає взагалі, а у вузла з кодом "чотири" є (так само як і у вузла "один") три нащадки з кодами "один", "два " і три". Зобразимо граф, заданий класами сутностей, наведеними вище:
Отже, щойно збудований нами граф і є тими даними, для зв'язування класів сутностей яких і використовувався зв'язок виду мережевої рекурсії. 3. Асоціація З усіх видів зв'язків, які входять до нашого конкретного курсу лекцій, рекурсивними зв'язками є лише дві. Ми їх уже встигли розглянути, це відповідно ієрархічний та мережевий рекурсивні зв'язки. Всі інші види зв'язків, які ми маємо розглянути, не є рекурсивними, а є, як правило, зв'язком кількох батьківських і кількох дочірніх класів сутностей. Причому, як можна здогадатися, батьківські та дочірні класи сутностей тепер уже ніколи не співпадатимуть (дійсно, адже вже не йдеться про рекурсію). Зв'язок, про який йтиметься в цьому параграфі лекції, називається асоціацією і відноситься якраз до нерекурсивного виду зв'язків. Отже, зв'язок асоціацією, реалізується як взаємозв'язок між кількома батьківськими класами сутностей та одним дочірнім класом сутностей. І при цьому, що цікаво, цей взаємозв'язок описується зв'язками різних типів. Також варто зазначити, що батьківський клас сутностей при асоціації може бути і один, як у мережевій рекурсії, але навіть у такій ситуації кількість зв'язків, що йдуть від дочірнього класу сутностей, має бути не меншою за дві. Цікаво, що з асоціації, як і і при мережевий рекурсії, існують спеціальні види класів сутностей. Приклад такого класу є дочірній клас сутностей. Адже загалом у асоціації дочірній клас сутностей називається класом асоціативних сутностей. В окремому випадку, коли клас асоціативних сутностей не має власних додаткових атрибутів і містить лише атрибути, які мігрують разом із первинними ключами з батьківських класів сутностей, такий клас називається класом іменуючих сутностей. Як можна звернути увагу, при цьому простежується майже абсолютна аналогія з поняттям асоціативних та іменуючих сутностей у мережевому рекурсивному зв'язку. Найчастіше асоціація використовується для деталізації (дозвіл) зв'язків виду "багато хто до багатьох". Проілюструємо це твердження. Нехай, наприклад, нам дано наступну презентаційну діаграму, яка описує схему прийому деякого лікаря в якійсь лікарні:
Ця діаграма буквально означає, що в лікарні є багато лікарів і багато пацієнтів, і більше ніякого відношення та відповідності між лікарями та пацієнтами не відображено. Таким чином, очевидно, що з такою базою даних в адміністрації лікарні ніколи не було б зрозуміло, як проводити прийоми у різних лікарів різних пацієнтів. Ясно, що використані тут зв'язки типу "багато до багатьох" просто необхідно деталізувати, щоб конкретизувати відносини між різними лікарями та пацієнтами, іншими словами, щоб раціонально організувати розклад прийомів усіх лікарів та їх пацієнтів, які є в лікарні. А тепер побудуємо більш докладну ключову діаграму, в якій ми вже деталізуємо всі зв'язки, що є, "багато до багатьох". Для цього ми відповідно введемо новий клас сутностей, назвемо його "Прийом", який виступатиме в ролі класу асоціативних сутностей (пізніше ми подивимося, чому саме це буде класом асоціативних сутностей, а не просто класом сутностей, про які ми говорили раніше). Отже, наша ключова діаграма буде виглядати так:
Отже, тепер видно, чому новий клас "Прийом" не є класом іменуючих сутностей. Адже цей клас має свій додатковий атрибут "Дата - Час", тому згідно з визначенням нововведений клас "Прийом" і є класом асоціативних сутностей. Цей клас "асоціює" класи сутностей "Лікарі" та "Пацієнти" один з одним за допомогою часу, в який і проводиться той чи інший прийом, що робить роботу з такою базою даних набагато зручніше. Таким чином, ми, ввівши атрибут "Дата - Час", буквально організували такий необхідний розклад роботи різних лікарів. Також бачимо, що зовнішній первинний ключ " Код Ліка " класу сутностей " Прийом " посилається на однойменний первинний ключ класу сутностей " Лікарі " . І аналогічно зовнішній первинний ключ " Код Пацієнта " класу сутностей " Прийом " посилається на однойменний первинний ключ класу сутностей " Пацієнти " . У разі, що зрозуміло, класи сутностей " Лікарі " і " Пацієнти " є батьківськими, а клас асоціативних сутностей " Прийом " , своєю чергою, є єдиним дочірнім. Ми бачимо, що тепер наявний у попередній презентаційній діаграмі зв'язок типу "багато до багатьох" повністю деталізований. Замість одного зв'язку "багато хто до багатьох", який ми бачимо в презентаційній діаграмі, наведеній раніше, у нас є два зв'язки типу "багато до одного". На дочірньому кінці першого зв'язку стоїть кратність "багато", це буквально означає, що в класі сутностей "Прийом" записано багато лікарів (усі, які є у лікарні). А на батьківському кінці цього зв'язку стоїть кратність "один", що це означає? А значить це, що у класі сутностей "Прийом" кожен із наявних кодів кожного конкретного лікаря може зустрічатися необмежено багато разів. Справді, адже у розкладі у лікарні код одного й того ж лікаря зустрічається багато разів, у різні дні та час. А ось цей код, але вже в класі сутностей "Лікарі" може зустрітися один і тільки один раз. Справді, адже у списку всіх лікарів лікарні (а клас сутностей "Лікарі" є не що інше, як такий список) код кожного конкретного лікаря може бути лише один раз. Аналогічне відбувається і зі зв'язком між батьківським класом "Пацієнти" та дочірнім класом "Пацієнти". У списку всіх пацієнтів лікарні (у класі сутностей "Пацієнти") код кожного конкретного пацієнта може зустрітися лише один раз. Зате в розкладі прийомів (у класі сутностей "Прийом") кожен код конкретного пацієнта може зустрітися скільки завгодно багато разів. Саме тому кратності на кінцях зв'язку розставлені саме таким чином. Як приклад реалізації асоціації в реляційній моделі даних збудуємо модель, яка описує графік зустрічей замовника з виконавцем за необов'язкової участі консультантів. Не будемо зупинятись на презентаційній діаграмі, тому що нам необхідно розглянути побудову діаграм у всіх подробицях, а презентаційна діаграма такої можливості надати не може. Отже, побудуємо ключову діаграму, яка відображатиме суть відносин між замовником, виконавцем та консультантом.
Отже, почнемо докладний аналіз наведеної ключової діаграми. По-перше, клас "Графік" є класом асоціативних сутностей, але, так само як і в минулому прикладі, не є класом сутностей, адже у нього є атрибут, який не мігрує в нього разом з ключами, а є його власним атрибутом. Це атрибут "Дата – Час". По-друге, бачимо, що атрибути дочірнього класу сутностей "Графік" "Код замовника", "Код виконавця" і "Дата - Час" утворюють складовий первинний ключ цього класу сутностей. Атрибут "Код консультанта" є зовнішнім ключем класу сутностей "Графік". Звернемо увагу, що цей атрибут припускає серед своїх значень Null-значення, адже за умовою присутність на зустрічі консультанта не є обов'язковою. Далі, по-третє, зауважимо, що перші два зв'язки (з трьох зв'язків) є не повністю ідентифікуючими. Саме не повністю ідентифікують, тому що мігруючий ключ в обох випадках (первинні ключі "Код замовника" та "Код виконавця") не повністю формує первинний ключ класу сутностей "Графік". Справді, залишається атрибут "Дата - Час", який також є частиною складового первинного ключа. На кінцях обох цих в повному обсязі ідентифікуючих зв'язків проставлені кратності "один" і "багато". Це зроблено для того, щоб показати (як і в прикладі про лікарів та пацієнтів) різницю між згадкою коду замовника чи виконавця у різних класах сутностей. Справді, у класі сутностей "Графік" будь-який код замовника чи виконавця може зустрічатися скільки завгодно багато разів. Тому на цьому, дочірньому кінці зв'язку стоїть кратність "багато". А в класі сутностей "Замовники" або "Виконавці" кожен із кодів відповідно замовника чи виконавця може зустрічатися один і лише один раз, адже ці класи сутностей є кожним не чим іншим, як повним списком усіх замовників та виконавців. Тому на цьому, батьківському кінці зв'язку, і стоїть кратність "один". І, нарешті, зауважимо, що третій зв'язок, а саме зв'язок класу сутностей "Графік" з класом сутностей "Консультанти", не обов'язково не ідентифікує. Дійсно, адже в цьому випадку йдеться про перенесення ключового атрибуту "Код консультанта" класу сутностей "Консультанти" до однойменного неключового атрибута класу сутностей "Графік", тобто первинний ключ класу сутностей "Консультанти" у класі сутностей "Графік" не ідентифікує. первинного ключа цього класу. І, крім того, як уже було згадано раніше, атрибут "Код консультанта" припускає Null-значення, тому тут і використовується зв'язок, що саме не повністю не ідентифікує. Таким чином, атрибут "Код консультанта" набуває статусу зовнішнього ключа і нічого більше того. Також звернемо увагу на кратність зв'язків, поставлених на батьківському та дочірньому кінцях цього не повністю не ідентифікуючого зв'язку. На її батьківському кінці стоїть кратність "не більше одного". Справді, якщо згадати визначення не повністю не ідентифікуючого зв'язку, ми зрозуміємо, що атрибуту "Код консультанта" з класу сутностей "Графік" не може відповідати більше одного коду консультанта зі списку всіх консультантів (яким є клас сутностей "Консультанти"). Та й взагалі може так вийти, що йому не відповідатиме жодного коду консультанта (згадаймо про прапорець допустимості Null-значень Код консультанта: Null), адже за умовою присутність консультанта на зустрічі замовника та виконавця, взагалі кажучи, не обов'язково. 4. Узагальнення Ще одним видом зв'язку класів сутностей між собою, який ми розглянемо, є зв'язок виду узагальнення. Це також нерекурсивний вид зв'язку. Отже, зв'язок типу узагальнення реалізується як взаємозв'язок одного батьківського класу сутностей з кількома дочірніми класами сутностей (на відміну від попереднього розглянутого зв'язку Асоціації, в якому йшлося про декілька батьківських класів сутностей та один дочірній клас сутностей). При формулюванні правил подання даних за допомогою зв'язку Узагальнення необхідно відразу сказати, що цей взаємозв'язок одного батьківського класу сутностей та кількох дочірніх класів сутностей описується повністю ідентифікуючими зв'язками, тобто категоріальними зв'язками. Згадуючи визначення повністю ідентифікуючих зв'язків, ми приходимо до висновку, що при використанні Узагальнення кожен атрибут первинного ключа батьківського класу сутностей переноситься до складу первинного ключа класів сутностей. , вони їх ідентифікують Цікаво відзначити, що при Узагальненні реалізується так звана ієрархія категорій чи ієрархія успадкування. У цьому батьківський клас сутностей визначає клас узагальнених сутностей, що характеризується атрибутами, загальними для сутності всіх дочірніх класів або так званих категоріальних сутностей т. е. батьківський клас сутностей є буквальне узагальнення всіх своїх дочірніх класів сутностей. Як приклад реалізації узагальнення реляційної моделі даних побудуємо наступну модель. Ця модель буде заснована на узагальненому понятті "Учні" і описуватиме наступні категоріальні поняття (тобто узагальнюватиме наступні дочірні класи сутностей): "Школярі", "Студенти" та "Аспіранти". Отже, побудуємо ключову діаграму, що відображатиме суть взаємовідносин між батьківським класом сутності та дочірніми класами сутностей, що описуються зв'язком типу Узагальнення.
Отже, що ми бачимо? По-перше, кожному з базових відносин (або з класів сутностей, що одне й те саме) "Школярі", "Студенти" та "Аспіранти" відповідають свої власні атрибути, як "Клас", "Курс" та "Рік навчання" . Кожен із цих атрибутів характеризує учасників свого власного класу сутностей. Ще бачимо, що первинний ключ батьківського класу сутностей "Учні" мігрує у кожен дочірній клас сутностей і формує там первинний зовнішній ключ. За допомогою цих зв'язків ми можемо за кодом будь-якого учня визначити його ім'я, прізвище та по батькові, інформацію про які ми не знайдемо у відповідних дочірніх класах сутностей. По-друге, оскільки ми говоримо про повністю ідентифікуючий (або категоріальний) зв'язок класів сутностей, то звернемо увагу на кратності зв'язків між батьківським класом сутностей та його дочірніми класами. На батьківському кінці кожного із цих зв'язків стоїть кратність " один " , але в кожному дочірньому кінці зв'язків стоїть кратність " трохи більше одного " . Якщо згадати визначення повністю ідентифікуючого зв'язку класів сутностей, то стає зрозуміло, що справді єдиний у своєму роді код учня, що є первинним ключем класу сутностей "Учні", задає не більше одного атрибуту з таким кодом у кожному дочірньому класі сутностей "Школярі", "Студень" і "Аспіранти". Тому усі зв'язки мають саме такі кратності. Запишемо фрагмент операторів створення базових відносин "Школярі" та "Студенти" з визначенням правил підтримки цілісності типу cascade. Отже, маємо: Create table Школярі ... primary key (Код учня) foreign key (Код учня) references Учні (Код учня) on update cascade on delete cascade Create table Студенти ... primary key (Код студента) foreign key (Код студента) references Учні (Код студента) on update cascade on delete cascade; Отже, бачимо, що у дочірньому класі сутностей (чи відносин) " Школярі " задається первинний зовнішній ключ, посилається на батьківський клас сутностей (чи ставлення) " Учні " . Правило cascade підтримки цілісності посилання визначає, що при видаленні або при оновленні атрибутів батьківського класу сутностей "Учні" відповідні їм атрибути дочірнього відношення "Школярі" будуть автоматично (каскадом) оновлюватися або видалятися. Аналогічно при видаленні або оновленні атрибутів батьківського класу сутностей "Учні" відповідні їм атрибути дочірнього відношення "Студенти" також автоматично оновлюватимуться або видалятимуться. Необхідно зауважити, що тут використовується саме це правило підтримки цілісності посилань, тому що в даному контексті (перелік учнів) не раціонально забороняти видалення та оновлення інформації, а також присвоювати невизначене значення замість реальних відомостей. А тепер наведемо приклад класів сутностей, описаних у попередній діаграмі, лише представлених у табличній формі. Отже, маємо такі таблиці-відносини: Учні - Батьківське ставлення, що поєднує в собі інформацію про атрибути всіх інших відносин:
Школярі - Дочірнє ставлення:
студенти - друге дочірнє ставлення:
Аспіранти - Третє дочірнє ставлення:
Отже, дійсно, ми бачимо, що в дочірніх класах сутностей не прописана інформація про прізвище, ім'я та по батькові учнів, тобто школярів, студентів та аспірантів. Цю інформацію можна отримати лише за допомогою посилань на батьківський клас сутностей. Також бачимо, що різні коди учнів у класі сутностей "Учні" можуть відповідати різним дочірнім класам сутностей. Так, про учня з кодом "1" Турбота Миколи в батьківському відношенні невідомо нічого, крім його імені, а всю решту інформації (хто він, школяр, студент чи аспірант) можна дізнатися лише звернувшись до відповідного дочірнього класу сутностей (визначається за кодом). Аналогічно необхідно працювати з іншими учнями, чиї коди вказані в батьківському класі сутностей "Учні". 5. Композиція Зв'язок класів сутностей типу композиція, як і дві попередні, не належить до виду рекурсивного зв'язку. композиція (або, як її ще іноді називають, композитна агрегація) - це взаємозв'язок одного батьківського класу сутностей з кількома дочірніми класами сутностей, так само як і попередній розглянутий нами зв'язок. Узагальнення. Але якщо узагальнення визначалося як взаємозв'язок класів сутності, що описується повністю ідентифікуючими зв'язками, то композиція, у свою чергу, описується не повністю ідентифікуючими зв'язками, тобто при композиції кожен атрибут первинного ключа батьківського класу сутностей мігрує в ключовий атрибут дочерг. І при цьому атрибути мігруючого ключа лише частково формують первинний ключ дочірнього класу сутностей. Отже, за композитної агрегації (при композиції) батьківський клас сутностей (або агрегат) пов'язується з кількома дочірніми класами сутностей (або компонентами). При цьому компоненти агрегату (тобто компоненти батьківського класу сутностей) посилаються на агрегат за допомогою зовнішнього ключа, що входить до складу первинного ключа і, отже, не можуть існувати поза агрегатом. Взагалі композитна агрегація є посиленою формою простої агрегації (про яку ми поговоримо трохи далі). Композиція (або композитна агрегація) характеризується тим, що: 1) посилання на агрегат бере участь у ідентифікації компонентів; 2) ці компоненти не можуть існувати поза агрегатом. Агрегація (зв'язок, яку ми розглядатимемо далі) з обов'язково не ідентифікуючими зв'язками також не дозволяє компонентам існувати поза агрегатом і тому близька за змістом до описаної вище реалізації композитної агрегації. Побудуємо ключову діаграму, що описує взаємозв'язок між одним батьківським класом сутностей та кількома дочірніми класами сутностей, тобто описує зв'язок класів сутностей типу композитної агрегації. Нехай це буде ключова діаграма, що зображає склад корпусів якогось навчального містечка, що включає корпуси, їх аудиторії та ліфти. Отже, ця діаграма матиме такий вигляд:
Отже, розглянемо щойно побудовану діаграму. Що ми у ній бачимо? По-перше, ми бачимо, що зв'язок, використаний у цій композитній агрегації, дійсно ідентифікує і дійсно не повністю ідентифікує. Адже первинний ключ батьківського класу сутностей "Корпуса" бере участь у формуванні первинного ключа дочірніх класів сутностей "Аудиторії" та "Ліфти", але не визначає його повністю. Первинний ключ "№ корпусу" батьківського класу сутностей мігрує до зовнішніх первинних ключів "№ корпусу" обох дочірніх класів, але, крім цього мігрованого, ключа в обох дочірніх класів сутностей існує і свій власний первинний ключ, відповідно "№ аудиторії" і "№ ліфта" ", т. Е. Складові первинні ключі дочірніх класів сутностей лише частково виявляються сформованими атрибутами первинного ключа батьківського класу сутностей. Тепер розберемося з кратностями зв'язків, що поєднують батьківський та обидва дочірні класи. Оскільки ми маємо справу з не повністю ідентифікуючими зв'язками, то кратності є такі: "один" і "багато". Кратність "один" присутня на батьківському кінці обох зв'язків і символізує те, що у списку всіх наявних корпусів (а клас сутностей "Корпуса" є саме таким списком) кожен номер може зустрітися лише один (і не більше) разів. А, у свою чергу, серед атрибутів класів "Аудиторії" та "Ліфти" кожен номер корпусу може зустрітися багато разів, оскільки аудиторій (або ліфтів) більше, ніж корпусів, і в кожному корпусі - кілька аудиторій і ліфтів. Таким чином, при перерахуванні всіх аудиторій та ліфтів ми неминуче повторюватимемо номери корпусів. І, нарешті, як і при розгляді попереднього виду зв'язку, запишемо фрагменти операторів створення базових відносин (або, що те саме, класів сутностей) "Аудиторії" та "Ліфти", причому зробимо це з визначенням правил підтримки цілісності типу cascade. Отже, цей оператор виглядатиме так: Create table Аудиторії ... primary key (№ корпусу, № аудиторії) foreign key (№ корпусу) Корпуси (№ корпусу) on update cascade on delete cascade Create table Ліфти ... primary key (№ корпусу, № ліфта) foreign key (№ корпусу) Корпуси (№ корпусу) on update cascade on delete cascade; Таким чином, ми і задали всі необхідні первинні та зовнішні ключі дочірніх класів сутностей. Правило підтримки цілісності посилань ми знову взяли cascade, тому що вже описали його як найбільш раціональний. Тепер наведемо приклад у табличній формі всіх щойно розглянутих нами класів сутностей. Опишемо ті базові відносини, які відобразили за допомогою діаграми, у вигляді таблиць, і для наочності введемо кілька показових даних. Корпуси - Батьківське відношення має такий вигляд:
Аудиторії - Дочірній клас сутностей:
Ліфти - другий дочірній клас сутностей батьківського класу "Корпуса":
Отже, ми можемо бачити, яким чином організована інформація по всіх корпусах, їх аудиторіям та ліфтам у цій базі даних, яку цілком може використати будь-який реально існуючий навчальний заклад. 6. Агрегація Агрегація – це останній вид зв'язку між класами сутностей, що підлягає розгляду у межах нашого курсу. Вона також не є рекурсивною, і один із двох її видів є досить близьким за змістом до вже розглянутої раніше композитної агрегації. Отже, агрегація - це взаємозв'язок одного батьківського класу сутностей із кількома дочірніми класами сутностей. При цьому взаємозв'язки можуть бути описані зв'язками двох видів: 1) обов'язково не ідентифікуючими зв'язками; 2) необов'язково не ідентифікуючими зв'язками. Нагадаємо, що при обов'язково не ідентифікуючих зв'язках деякі атрибути первинного ключа батьківського класу сутностей переносяться в неключовий атрибут дочірнього класу, і при цьому значення Null для всіх атрибутів мігруючого ключа заборонені. А при не обов'язково не ідентифікуючих зв'язках міграція первинних ключів відбувається за таким же принципом, але при цьому Null-значення для деяких атрибутів мігруючого ключа дозволені. При агрегації батьківський клас сутностей (або агрегат) пов'язується з кількома дочірніми класами сутностей (або компонентами). Компоненти агрегату (тобто батьківського класу сутностей) посилаються на агрегат за допомогою зовнішнього ключа, що не входить до складу первинного ключа, і, отже, у разі не обов'язково не ідентифікуючих зв'язків, компоненти агрегату можуть існувати поза агрегатом. У разі використання агрегації з обов'язково не ідентифікуючими зв'язками компонентам агрегату не дозволяється існувати поза агрегатом, і в цьому сенсі агрегація з обов'язково не ідентифікуючими зв'язками близька до композитної агрегації. Тепер, коли стало зрозуміло, що є зв'язок типу агрегації, побудуємо ключову діаграму, що описує роботу цього зв'язку. Нехай наша майбутня діаграма описує марковані компоненти автомобілів (а саме двигун та шасі). При цьому вважатимемо, що списування автомобіля передбачає і списування шасі разом з ним, але не передбачає одночасне списування двигуна. Отже, наша ключова діаграма має такий вигляд:
Отже, що ми бачимо на цій ключовій діаграмі? По-перше, зв'язок батьківського класу сутностей "Автомобілі" з дочірнім класом сутностей "Двигуни" не обов'язково не ідентифікує, тому що атрибут "№ автомобіля" допускає серед своїх значень Null-значення. У свою чергу, Null-значення цей атрибут допускає з тієї причини, що списування двигуна, за умовою не залежить від списування всього автомобіля і, отже, при списуванні автомобіля відбувається не обов'язково. Також ми бачимо, що первинний ключ "№ двигуна" класу сутностей "Автомобілі" мігрує у неключовий атрибут "№ двигуна" класу сутностей "Двигуни". І при цьому даний атрибут набуває статусу зовнішнього ключа. А первинним ключем у цьому класі сутностей "Двигуни" є атрибут "Маркер двигуна", який не посилається на жодний атрибут батьківського відношення. По-друге, зв'язок батьківського класу сутностей "Двигуни" та дочірнього класу сутностей "Шассі" - це обов'язково не ідентифікуючий зв'язок, тому що атрибут зовнішнього ключа "№ автомобіля" не допускає серед своїх значень Null-значення. Це, у свою чергу, відбувається тому, що за умовою відомо, що списування автомобіля передбачає обов'язкове одночасне списування та шасі. Тут, як і у разі попереднього зв'язку, первинний ключ батьківського класу сутностей "Двигуни" мігрує до неключового атрибута "№ автомобіля" дочірнього класу сутностей "Шассі". При цьому первинним ключем цього класу сутностей є атрибут "Маркер шасі", який не посилається на жодний атрибут батьківського відношення "Двигуни". Йдемо далі. Для найкращого засвоєння пройденої теми, запишемо знову фрагменти операторів створення базових відносин "Двигуни" та "Шасі" з визначенням правил підтримки цілісності посилання. Create table Двигуни ... primary key (Маркер двигуна) foreign key (№ автомобіля) references Автомобілі (№ автомобіля) on update cascade on delete set Null Create table Шасі ... primary key (Маркер шасі) foreign key (№ автомобіля) references Автомобілі (№ автомобіля) on update cascade on delete cascade; Ми бачимо, що правило підтримки цілісності посилання ми використовували скрізь одне - cascade, так як ще раніше визнали його найбільш раціональним з усіх. Однак цього разу ми використовували (крім правила cascade) ще й правило підтримки цілісності посилання на set Null. Причому використовували ми його за наступної умови: якщо якесь значення первинного ключа "№ автомобіля" з батьківського класу сутностей "Автомобілі" буде видалено, то значенню зовнішнього ключа "№ автомобіля", що посилається на нього, дочірнього відношення "Двигуни" буде присвоєно Null-значення . 7. Уніфікація атрибутів Якщо при міграції первинних ключів якогось батьківського класу сутностей в один і той же дочірній клас потрапляють атрибути з різних батьківських класів, що збігаються за змістом, то ці атрибути необхідно "злити", тобто необхідно провести так звану уніфікацію атрибутів. Наприклад, у випадку, коли співробітник може працювати в організації, вважаючи не більше ніж в одному відділі, після уніфікації атрибуту "Код організації" отримаємо наступну ключову діаграму:
При міграції первинний ключ із батьківських класів сутностей "Організація" та "Відділи" до дочірнього класу "Співробітники", атрибут "Код організації" потрапляє до класу сутностей "Співробітники". Причому двічі: 1) перший раз із маркером PFK із класу сутностей "Організація" при встановленні не повністю ідентифікуючого зв'язку; 2) та вдруге, з маркером FK з умовою допустимості Null-значень із класу сутностей "Відділи" при встановленні не обов'язково не ідентифікуючого зв'язку. При уніфікації атрибут "Код організації" набуває статусу атрибута первинного / зовнішнього ключа, що поглинає статус атрибута зовнішнього ключа. Побудуємо нову ключову діаграму, що демонструє процес уніфікації:
У такий спосіб і відбулася уніфікація атрибутів. Лекція № 13. Експертні системи та продукційна модель знань 1. Призначення експертних систем Для ознайомлення з таким новим нам поняттям, як експертні системи ми, для початку, пройдемося з історії створення та розробки напряму "експертні системи", а потім визначимо і саме поняття експертних систем. На початку 80-х років. XX ст. у дослідженнях зі створення штучного інтелекту сформувався новий самостійний напрямок, який отримав назву експертних систем. Мета цих нових досліджень з експертних систем полягає у розробці спеціальних програм, призначених на вирішення особливих видів завдань. Що це за особливий вид завдань, що зажадав створення цілої нової інженерії знань? До цього особливого виду завдань можуть бути віднесені завдання абсолютно будь-якої предметної області. Головне, що відрізняє їхню відмінність від завдань звичайних, - те, що людині-експерту вирішити їх представляється дуже складним завданням. Тоді й було розроблено першу так звану експертна система (де в ролі експерта виступала вже не людина, а машина), причому експертна система отримує результати, що не поступаються за якістю та ефективності рішенням, одержуваним звичайною людиною - експертом. Результати роботи експертних систем можна пояснити користувачеві дуже високому рівні. Дана якість експертних систем забезпечується їхньою здатністю розмірковувати про власні знання та висновки. Експертні системи можуть поповнювати власні знання у процесі взаємодії з експертом. Таким чином, їх можна з повною впевненістю ставити в один ряд із штучним інтелектом, що цілком оформився. Дослідники в галузі експертних систем для назви своєї дисципліни часто використовують також згадуваний раніше термін "інженерія знань", введений німецьким ученим Е. Фейгенбаумом як "привнесення принципів та інструментарію досліджень з галузі штучного інтелекту у вирішення важких прикладних проблем, що вимагають знань експертів". Однак комерційні успіхи до фірм-розробників прийшла не одразу. Протягом чверті століття у період із 1960 по 1985 рр. успіхи штучного інтелекту стосувалися переважно дослідницьких розробок. Тим не менш, починаючи приблизно з 1985 р., а в масовому масштабі з 1987 по 1990 р.р. експертні системи стали активно використовуватися у комерційних додатках. Заслуги експертних систем досить великі і полягають у наступному: 1) технологія експертних систем істотно розширює коло практично значущих завдань, розв'язуваних на персональних комп'ютерах, вирішення яких приносить значний економічний ефект і спрощує пов'язані з ними процеси; 2) технологія експертних систем є одним із найважливіших засобів у вирішенні глобальних проблем традиційного програмування, таких як тривалість, якість та, отже, висока вартість розробки складних додатків, внаслідок якої значно знижувався економічний ефект; 3) є висока вартість експлуатації та обслуговування складних систем, яка часто у кілька разів перевищує вартість самої розробки, а також низький рівень повторної використання програм тощо; 4) об'єднання технології експертних систем із технологією традиційного програмування додає нові якості до програмних продуктів за рахунок, по-перше, забезпечення динамічної модифікації додатків рядовим користувачем, а не програмістом; по-друге, більшої "прозорості" програми, кращої графіки, інтерфейсу та взаємодії експертних систем. На думку рядових користувачів та провідних фахівців, у недалекій перспективі експертні системи знайдуть таке застосування: 1) експертні системи відіграватимуть провідну роль на всіх стадіях проектування, розробки, виробництва, розподілу, налагодження, контролю та надання послуг; 2) технологія експертних систем, що набула широкого комерційного поширення, забезпечить революційний прорив в інтеграції додатків із готових інтелектуально-взаємодіючих модулів. У загальному випадку експертні системи призначені для так званих неформалізованих завдань, т. е. експертні системи не відкидають і замінюють традиційного підходи до розробки програм, орієнтованого рішення формалізованих завдань, але доповнюють їх, цим значно розширюючи можливості. Саме цього і не може зробити проста людина-експерт. Такі складні неформалізовані завдання характеризуються: 1) помилковістю, неточністю, неоднозначністю, а також неповнотою та суперечливістю вихідних даних; 2) хибністю, неоднозначністю, неточністю, неповнотою та суперечливістю знань про проблемну галузь і розв'язуване завдання; 3) великою розмірністю простору рішень конкретної задачі; 4) динамічною мінливістю даних та знань безпосередньо в процесі вирішення такого неформалізованого завдання. Експертні системи головним чином ґрунтуються на евристичному пошуку рішення, а не на виконанні відомого алгоритму. У цьому одна з головних переваг технології експертних систем перед традиційним підходом до розробки програм. Саме це дозволяє їм так добре справлятися з поставленими перед ними завданнями. Технологія експертних систем використовується для вирішення різних завдань. Перелічимо основні із подібних завдань. 1. Інтерпретація. Експертні системи, що виконують інтерпретацію, найчастіше застосовують показання різних приладів з метою опису стану справ. Інтерпретують експертні системи здатні обробляти різні види інформації. Прикладом може послужити використання даних спектрального аналізу та зміни характеристик речовин для визначення їх складу та властивостей. Також прикладом може бути інтерпретація показань вимірювальних приладів у котельні для опису стану котлів та води в них. Інтерпретуючі системи найчастіше мають справу безпосередньо із показаннями. У зв'язку з цим виникають труднощі, яких немає в інших видів систем. Що це за труднощі? Ці труднощі виникають через те, що експертним системам доводиться інтерпретувати засмічену зайвою, неповну, ненадійну чи неправильну інформацію. Звідси неминучі або помилки, або значне збільшення обробки даних. 2. Прогнозування. Експертні системи, які здійснюють прогноз чогось, визначають імовірнісні умови заданих ситуацій. Прикладами є прогноз збитків, завданих урожаю хлібів несприятливими погодними умовами, оцінювання попиту на газ на світовому ринку, прогнозування погоди за даними метеорологічних станцій. Системи прогнозування іноді застосовують моделювання, тобто такі програми, які відображають деякі взаємозв'язки в реальному світі, щоб відтворити їх у середовищі програмування, і потім спроектувати ситуації, які можуть виникнути за тих чи інших вихідних даних. 3. Діагностика різних приладів. Експертні системи виробляють таку діагностику, застосовуючи описи будь-якої ситуації, поведінки або даних про будову різних компонентів, щоб визначити можливі причини несправної діагностованої системи. Прикладами є встановлення причин захворювання за симптомами, які спостерігаються у хворих (у медицині); визначення несправностей в електронних схемах та визначення несправних компонентів у механізмах різних приладів. Системи діагностики досить часто є помічниками, які не лише ставлять діагноз, а й допомагають усунути неполадки. У таких випадках дані системи можуть взаємодіяти з користувачем, щоб надати допомогу при пошуку несправностей, а потім навести список дій, необхідних для їх усунення. В даний час багато діагностичних систем розробляються як додатки до інженерної справи та комп'ютерних систем. 4. Планування різних подій. Експертні системи, призначені для планування, проектують різноманітні операції. Системи визначають практично повну послідовність дій, як розпочнеться їх реалізація. Прикладами такого планування подій можуть бути створення планів воєнних дій як оборонного, так і наступального характеру, визначеного на певний термін з метою одержання переваги перед ворожими силами. 5. Проектування. Експертні системи, що виконують проектування, розробляють різні форми об'єктів, враховуючи обставини, що склалися, і всі супутні фактори. Як приклад можна розглянути генну інженерію. 6. Контроль. Експертні системи, які здійснюють контроль, порівнюють справжню поведінку системи з її очікуваною поведінкою. Спостерігаючі експертні системи виявляють контрольовану поведінку, яка підтверджує їх очікування порівняно з нормальною поведінкою або їх припущенням про потенційні відхилення. Контролюючі експертні системи за своєю суттю повинні працювати в режимі реального часу і реалізовувати інтерпретацію поведінки контрольованого об'єкта, що залежить як від часу, так і від контексту. Як приклад можна навести стеження показаннями вимірювальних приладів в атомних реакторах з метою виявлення аварійних ситуацій або оцінку даних діагностики пацієнтів, що знаходяться в блоці інтенсивного лікування. 7. Управління. Адже відомо, що експертні системи, здійснюють управління, дуже результативно керують поведінкою системи загалом. Прикладом є управління різними виробництвами, і навіть розподілом комп'ютерних систем. Керуючі експертні системи повинні включати спостерігаючі компоненти, для того, щоб контролювати поведінку об'єкта протягом тривалого часу, але вони можуть потребувати і інших компонентів з вже проаналізованих типів завдань. Експертні системи застосовуються в різних галузях: фінансових операціях, нафтової та газової промисловості. Технологія експертних систем може бути застосована також в енергетиці, транспортному господарстві, фармацевтичному виробництві, космічних розробках, металургійній та гірничій промисловості, хімії та багатьох інших областях. 2. Структура експертних систем Розробка експертних систем має низку істотних відмінностей від розробки звичайного програмного продукту. Досвід створення експертних систем показав, що використання при розробці методології, прийнятої в традиційному програмуванні, або сильно збільшує кількість часу, витраченого на створення експертних систем, або зовсім призводить до негативного результату. Експертні системи в загальному випадку поділяються на статичні и динамічні. Спочатку розглянемо статичну експертну систему. Стандартна статична експертна система складається з наступних основних компонентів: 1) робочої пам'яті, що називається також базою даних; 2) основи знань; 3) вирішувача, званого також інтерпретатором; 4) компонентів набуття знань; 5) пояснювального компонента; 6) діалогового компонента. Розглянемо тепер кожен компонент докладніше. Робоча пам'ять (за абсолютною аналогією з робочою, тобто оперативною пам'яттю комп'ютера) призначена для отримання та зберігання вихідних і проміжних даних задачі, що вирішується в даний момент. База знань призначена для зберігання довгострокових даних, що описують конкретну предметну область, та правил, що описують раціональне перетворення даних цієї галузі розв'язуваної задачі. Вирішувач, званий також інтерпретатором, функціонує наступним чином: використовуючи вихідні дані з робочої пам'яті та довгострокові дані з бази знань, він формує правила, застосування яких до вихідних даних призводить до вирішення задачі. Одним словом, він дійсно "вирішує" поставлене перед ним завдання; Компонент придбання знань автоматизує процес заповнення експертної системи знаннями експерта, тобто саме цей компонент забезпечує базу знань всією необхідною інформацією з даної конкретної предметної галузі. Компонент пояснень роз'яснює, як система отримала розв'язання цієї задачі, або чому вона цього рішення не отримала і які знання вона при цьому використовувала. Інакше висловлюючись, компонент пояснень створює звіт про виконану роботу. Цей компонент є дуже важливим у всій експертній системі, оскільки він значно полегшує тестування системи експертом, а також підвищує довіру користувача до отриманого результату та, отже, прискорює процес розробок. Діалоговий компонент служить для забезпечення дружнього інтерфейсу користувача як у ході вирішення завдання, так і в процесі набуття знань та оголошення результатів роботи. Тепер, коли ми знаємо, з яких компонентів загалом складається статистична експертна система, побудуємо діаграму, яка відображатиме структуру такої експертної системи. Вона має такий вигляд:
Статичні експертні системи найчастіше використовуються у технічних додатках, де можна не враховувати зміни навколишнього середовища, що відбуваються під час вирішення задачі. Цікаво знати, що перші експертні системи, які отримали практичне застосування, були статичними. Отже, на цьому закінчимо поки що розгляд статистичної експертної системи, перейдемо до аналізу експертної системи динамічної. На жаль, до програми нашого курсу не входить докладний розгляд цієї експертної системи, тому обмежимося розбором лише найголовніших відмінностей динамічної експертної системи від статичних. На відміну від статичної експертної системи у структуру динамічної експертної системи додатково вводяться два наступні компоненти: 1) підсистема моделювання зовнішнього світу; 2) підсистема зв'язків із зовнішнім оточенням. Підсистема зв'язків із зовнішнім оточенням якраз і здійснює зв'язки із зовнішнім світом. Робить вона це за допомогою системи спеціальних датчиків та контролерів. Крім цього, деякі традиційні компоненти статичної експертної системи зазнають суттєвих змін, щоб відобразити тимчасову логіку подій, що відбуваються в даний момент у навколишньому середовищі. Це головна відмінність між статичною та динамічною експертними системами. Приклад динамічної експертної системи – управління виробництвом різних медикаментів у фармацевтичній промисловості. 3. Учасники розробки експертних систем У розробці експертних систем беруть участь представники різних спеціальностей. Найчастіше конкретну експертну систему розробляють троє спеціалістів. Це, як правило: 1) експерт; 2) інженер із знань; 3) програміст із розробки інструментальних засобів. Роз'яснимо обов'язки кожного з наведених тут спеціалістів. Експерт - це фахівець у тій предметній галузі, завдання якої і вирішуватимуться за допомогою цієї конкретної експертної системи, що розробляється. Інженер зі знань - це фахівець із розробки безпосередньо експертної системи. Використовувані ним технології та методи називаються технологіями та методами інженерії знань. Інженер із знань допомагає експерту виявити з усієї інформації предметної області ту інформацію, яка необхідна роботи з конкретної розроблюваної експертної системою, та був структурувати її. Цікаво, що відсутність серед учасників розробки інженерів за знаннями, тобто заміна їх програмістами, або призводить до невдачі проекту створення конкретної експертної системи, або значно збільшує терміни її розробки. І, нарешті, програміст розробляє інструментальні засоби (якщо інструментальні засоби розробляються наново), призначені для прискорення розробки експертних систем. Ці інструментальні засоби містять у межі всі основні компоненти експертної системи; також програміст здійснює сполучення своїх інструментальних засобів з тим середовищем, в якому вона використовуватиметься. 4. Режими роботи експертних систем Експертна система працює у двох основних режимах: 1) у режимі набуття знань; 2) у режимі вирішення задачі (називається також режимом консультацій, або режимом використання експертної системи). Це логічно і зрозуміло, адже спочатку необхідно завантажити експертну систему інформацією з тієї предметної галузі, в якій їй належить працювати, це і є режим "навчання" експертної системи, режим, коли вона отримує знання. А вже після завантаження всієї необхідної для роботи інформації слідує і сама робота. Експертна система стає готовою для експлуатації, і її тепер можна використовувати для консультацій або вирішення будь-яких завдань. Розглянемо докладніше режим набуття знань. У режимі придбання знань роботу з експертною системою здійснює експерт за посередництвом інженера зі знань. У цьому режимі експерт, використовуючи компонент набуття знань, наповнює систему знаннями (даними), які, своєю чергою, дозволяють системі режимі рішення без участі експерта вирішувати завдання з даної предметної області. Слід зазначити, що режиму набуття знань у традиційному підході до розробки програм відповідають етапи алгоритмізації, програмування та налагодження, що виконуються безпосередньо програмістом. Звідси випливає, що на відміну від традиційного підходу у разі експертних систем розробку програм здійснює не програміст, а експерт, природно, за допомогою експертних систем, тобто за великим рахунком людина, яка не володіє програмуванням. Нині ж розглянемо другий режим функціонування експертної системи, тобто. режим вирішення завдань. У режимі розв'язання задачі (або так званому режимі консультації) спілкування з експертними системами здійснює безпосередньо кінцевий користувач, якого цікавить кінцевий результат роботи та іноді спосіб його отримання. Необхідно відзначити, що залежно від призначення експертної системи користувач не обов'язково має бути фахівцем у цій проблемній галузі. У цьому випадку він звертається до експертних систем за результатом, не маючи достатніх знань для отримання результатів. Або все ж користувач може мати рівень знань, достатній для досягнення необхідного результату самостійно. У цьому випадку користувач може сам отримати результат, але звертається до експертних систем з метою прискорити процес отримання результату, або покласти на експертні системи монотонну роботу. У режимі консультації дані завдання користувача після обробки їх діалоговим компонентом надходять у робочу пам'ять. Вирішувач на основі вхідних даних з робочої пам'яті, загальних даних про проблемну область та правила з бази даних формує рішення задачі. Експертні системи під час вирішення завдання як виконують запропоновану послідовність конкретної операції, а й попередньо формує її. Це робиться для випадку, якщо реакція системи не зовсім зрозуміла для користувача. У цій ситуації користувач може вимагати пояснення про те, чому дана експертна система ставить те чи інше питання або чому дана експертна система не може виконати дану операцію, як отримано той чи інший результат, який постачається цією експертною системою. 5. Продукційна модель знань За своєю суттю продукційні моделі знань близькі до логічних моделей, що дозволяє організувати ефективні процедури логічного виведення даних. Це з одного боку. Однак, з іншого боку, якщо розглядати продукційні моделі знань у порівнянні з логічними моделями, то перші наочно відображають знання, що є незаперечною перевагою. Тому, безсумнівно, продукційна модель знань одна із основних засобів уявлення знань у системах штучного інтелекту. Отже, розпочнемо докладний розгляд поняття продукційної моделі знань. Традиційна продукційна модель знань включає наступні базові компоненти: 1) набір правил (чи продукцій), які мають базу знань продукційної системи; 2) робочу пам'ять, у якій зберігаються вихідні факти, і навіть факти, виведені з вихідних фактів з допомогою механізму логічного вывода; 3) сам механізм логічного висновку, що дозволяє з наявних фактів, згідно з наявними правилами виведення, виводити нові факти. Причому, що цікаво, кількість таких операцій може бути нескінченною. Кожне правило, що є базою знань продукційної системи, містить умовну та заключну частини. В умовній частині правила знаходиться або одиночний факт, або кілька фактів, поєднаних кон'юнкцією. У заключній частині правила є факти, якими необхідно поповнити робочу пам'ять, якщо умовна частина правила є істинною. Якщо спробувати схематично зобразити продукційну модель знань, то під продукцією розуміється вираз такого виду: (i) Q; P; A → B; N; Тут i - це ім'я продукційної моделі знань або її порядковий номер, за допомогою якого дана продукція виділяється з безлічі продукційних моделей, отримуючи певну ідентифікацію. Як ім'я може бути деяка лексична одиниця, що відбиває суть даної продукції. Фактично ми називаємо продукцію для кращого сприйняття свідомістю, щоб спростити пошук потрібної продукції зі списку. Наведемо простий приклад: покупка зошита" або "набір кольорових олівців. Очевидно, що кожну продукцію зазвичай називають словами, придатними для цього моменту. Простіше кажучи називають речі своїми іменами. Йдемо далі. Елемент Q характеризує сферу застосування цієї конкретної продукційної моделі знань. Такі сфери легко виділяються у свідомості людини, тому з визначенням даного елемента, як правило, складнощів не виникає. Наведемо приклад. Розглянемо таку ситуацію: припустимо, в одній сфері нашої свідомості зберігаються знання про те, як треба готувати їжу, в іншій, як дістатися роботи, у третій, як правильно експлуатувати пральну машину. Подібний поділ є і в пам'яті продукційної моделі знань. Цей поділ знань на окремі сфери дозволяє значно економити час, що витрачається на пошук потрібних на даний момент якихось конкретних продукційних моделей знань і тим самим значно спрощує процес роботи з ними. Очевидно, що основним елементом продукції є її так зване ядро, яке в нашій наведеній вище формулі позначалося як А → В. Ця формула може бути інтерпретована, як "якщо виконується умова А, то слід виконати дію В". Якщо ж ми маємо справу з складнішими конструкціями ядра, то в правій частині допускається наступний альтернативний вибір: "якщо виконується умова А, то слід виконати дію1, інакше слід виконати дію2". Однак інтерпретація ядра продукційної моделі знань може бути різною і залежатиме від того, що стоятиме ліворуч і праворуч від знака секвенції "→". При одній з інтерпретацій ядра продукційної моделі знань секвенція може тлумачитися у звичайному логічному сенсі, тобто як знак логічного слідування дії В з істинної умови А. Проте можливі інші інтерпретації ядра продукційної моделі знань. Так, наприклад, А може описувати якусь умову, виконання якої необхідне для того, щоб можна було зробити якусь дію. Далі розглянемо елемент продукційної моделі знань Р. елемент Р визначається, як умова застосування ядра продукції. Якщо умова Р істинна, то ядро продукції активізується. В іншому випадку, якщо умова Р не виконується, тобто вона хибна, ядро не може бути активізовано. Як наочний приклад розглянемо наступну продукційну модель знань: "Наявність грошей"; "Якщо хочеш купити річ А, то слід заплатити до каси її вартість та пред'явити чек продавцю". Дивимося, якщо умова Р істинна, тобто купівлю сплачено і чек пред'явлено, то ядро активізується. Купівля здійснена. Якщо в цій продукційній моделі знань умова застосування ядра помилкова, тобто якщо немає грошей, то застосувати ядро продукційної моделі знань неможливо, і воно не активізується. І переходимо, нарешті, до елемента N. Елемент N називається постумовою продукційної моделі даних. Постуслів задає дії та процедури, які необхідно виконати після реалізації ядра продукції. Для кращого сприйняття наведемо простий приклад: після купівлі речі в магазині необхідно в описі товарів цього магазину зменшити на одиницю кількість речей такого типу, тобто якщо покупка здійснена (отже, реалізовано ядро), то в магазині стало одну одиницю даного конкретного товару менше. Звідси постмова "Викреслити одиницю купленого товару". Підсумовуючи, ми можемо сказати, що уявлення знань як набору правил, т. е. у вигляді використання продукційної моделі знань, має такі переваги: 1) це простота створення та розуміння окремих правил; 2) це простота механізму логічного вибору. Однак у поданні знань у вигляді набору правил є і недоліки, які все ж таки обмежують сферу і частоту застосування продукційних моделей знань. Основним таким недоліком вважається неясність взаємних відносин між складовими конкретної продукційної моделі знань правилами, а також правилами логічного вибору. Примітки 1. Підкресленому шрифту у друкарському виданні книги відповідає напівжирний курсив у цій (електронній) версії книги. (Прим. ел. ред)
▪ Страхове право. Конспект лекцій ▪ Дитяча хірургія Конспект лекцій
Новий спосіб управління та маніпулювання оптичними сигналами
05.05.2024 Приміальна клавіатура Seneca
05.05.2024 Запрацювала найвища у світі астрономічна обсерваторія
04.05.2024
▪ Датчики для захисту американських футболістів ▪ Електронна книга Xiaomi Mi Reader Pro ▪ Оптичний прискорювач нейронної мережі ▪ Акумулятори Ampd Energy для великих баштових кранів.
▪ Розділ сайту Електромонтажні роботи. Добірка статей ▪ стаття І терпентин на щось корисний! Крилатий вислів ▪ стаття Що таке екологія? Детальна відповідь ▪ стаття Вітрило на гумовому човні. Особистий транспорт ▪ стаття Цифровий фотоапарат – слайд-сканер. Енциклопедія радіоелектроніки та електротехніки ▪ стаття Виготовлення трансформаторів своїми руками. Енциклопедія радіоелектроніки та електротехніки
Головна сторінка | Бібліотека | Статті | Карта сайту | Відгуки про сайт
www.diagram.com.ua |



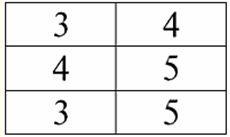

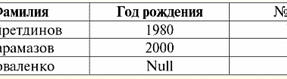

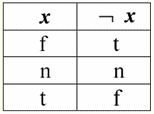

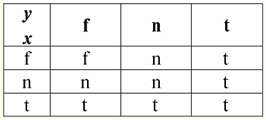
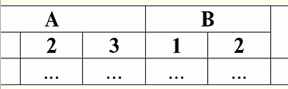


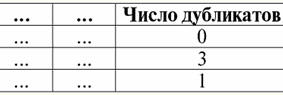
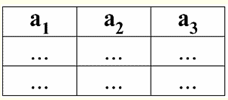






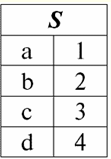
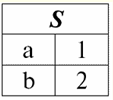

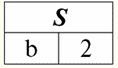
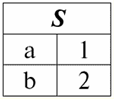

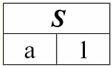
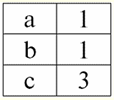

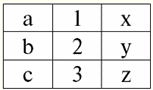









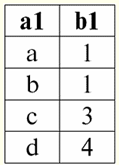






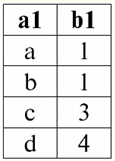



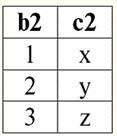

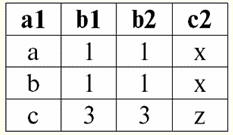
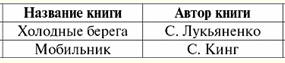







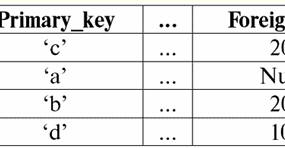








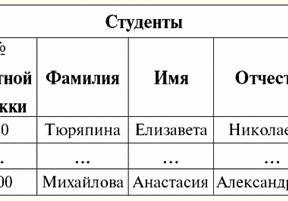
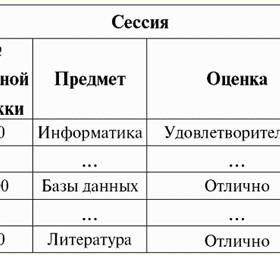



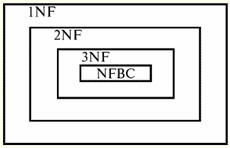

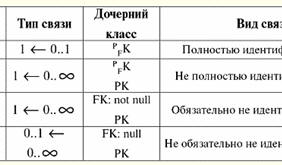






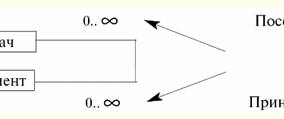

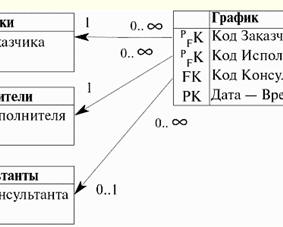







 Дивіться інші статті розділу
Дивіться інші статті розділу 